目标检测算法SSD用于行人检测(一):数据集格式转换
将Caltech行人数据集转换成基于Caffe-SSD能够训练的格式(Pascal VOC数据集格式)
一、Caltech Pedestrian Dateset
Caltech数据集地址:http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/
该数据库是目前规模较大的行人数据库,采用车载摄像头拍摄,约10个小时左右,视频的分辨率为640x480,30帧/秒。标注了约250,000帧(约137分钟),350000个矩形框,2300个行人,另外还对矩形框之间的时间对应关系及其遮挡的情况进行标注。 数据集分为set00~set10,其中set00~set05为训练集,set06~set10为测试集(标注信息尚未公开)。
性能评估方法有以下三种:
(1)用外部数据进行训练,在set06~set10进行测试;
(2)6-fold交叉验证,选择其中的5个做训练,另外一个做测试,调整参数,最后给出训练集上的性能;
(3)用set00~set05训练,set06~set10做测试。
由于测试集的标注信息没有公开,需要提交给Pitor Dollar。结果提交方法为每30帧做一个测试,将结果保存在txt文档中(文件的命名方式为I00029.txt I00059.txt ……),每个txt文件中的每行表示检测到一个行人,格式为“[left, top,width, height, score]”。如果没有检测到任何行人,则txt文档为空。该数据库还提供了相应的Matlab工具包,包括视频标注信息的读取、画ROC(Receiver Operatingcharacteristic Curve)曲线图和非极大值抑制等工具。
二、转换工具
Caltech2VOC:https://github.com/WeiFeifan/Caltech2VOC
运行该工具必备的软件:推荐Ubuntu16.04+Matlab+python2.7+opencv
安装步骤:
第一步:在%caffe-root%/data文件夹中新建caltech文件夹,将Caltech2VOC中的所有内容复制到%caffe-root%/data/caltech;这里%caffe-root%是指本机上的caffe根目录。
第二步:下载Caltech数据集,下载到%caffe-root%/data/caltech中。并将其解压到%caffe-root%/data/caltech/caltech_code/data-USA;这里放在data/caltech只是为了方便说明,放在其他路径时,自己修改相应路径。
第三步:运行%caffe-root%/data/caltech/caltech_code/extractDatasets.m 这时会在%caffe-root%/data/caltech文件夹下生成trainval和test文件夹。
注:这里trainval设置的是每5帧提取出1帧图片,如果你想提取更多的训练数据的话,可以适当修改dbInfo.m。dbInfo.m中的第48行代码,skip就是每隔5帧提取出1帧图片。可以自行设置。test数据是每30帧提取一张图片,设置内容与官网上提交测试结果统一。

在dbExtractSSD.m文件中添加第48行,如下所示:

在DBExtractSSD.m文件中注意第40行的pth路径可能和你的路径有问题,我是直接将videos/去掉:
![]()
第四步:生成的trainval和test文件夹中会有images和labels文件夹,分别存放了图片和标注信息。其中bounding box是txt格式的,我们需要转化成VOC的xml格式。
运行%caffe-root%/data/caltech中的createXml.py,其中:
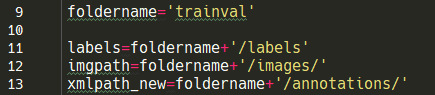
以上对应了你自己的路径信息。第一次运行生成trainval中的annotations,第二次运行修改foldername=‘test’后,生成test中的annotations。
第五步:在没有行人的图片中并不生成annotation文件,可以将没有行人的图片移除。这里将原来的原来的images文件夹改名为OImages,新建一个空文件夹images。
运行第二步复制来的move_jpgto.py。即可生成我们想要的VOC格式的caltech行人数据集。
最后我们可以看到在Caltech文件夹下生成了trainval文件夹和test文件夹。
参考博客: https://blog.csdn.net/u010725283/article/details/79122650
三、VOC数据集格式说明及其转换为LMDB格式
PASCAL VOC数据集详细解释:https://blog.csdn.net/u013832707/article/details/80060327
1、VOC数据集格式说明
VOC数据集必须包含以下三个文件夹:
(1) Annotations:存放的是xml格式的标签文件,每一个xml文件都对应于JPEGImages文件夹中的一张图片。
(2)JPEGImages:包含了PASCAL VOC所提供的所有的原图片,包括了训练图片和测试图片。
(3)ImageSets:该目录下存放的都是txt文件,txt文件中每一行包含一个图片的名称,末尾会加上±1表示正负样本。ImageSets里只需要用到Main文件夹,而在Main中,主要用到4个文件(我只保留了trainval.txt和test.txt两个文件):
- train.txt 是用来训练的图片文件的文件名列表
- trianval.txt是用来训练和验证的图片文件的文件名列表
- val.txt是用来验证的图片文件的文件名列表
- test.txt 是用来测试的图片文件的文件名列表
2、将VOC格式转换为LMDB格式
SSD提供了VOC数据到LMDB数据的转换脚本 data/VOC0712/create_list.sh 和 /data/VOC0712/create_data.sh,这两个脚本是完全针对VOC0712目录下的数据进行的转换。将VOC格式转换为LMDB格式必需的几个文件:
(1)create_list.sh :用于生成训练集,测试集的文件路径txt文件和一个测试集目录名和图片大小的txt;
(2)create_data.sh:用于生成lmdb格式的训练数据集和测试集;
(3)labelmap_voc.prototxt:里头是标签的信息。
四、将Caltech转换的到的VOC格式转换为LMDB格式
1、在caffe_SSD_root/data目录下建立自己的目录VOCdevkit/Caltech文件夹;在Caltech文件夹下创建一下三个子文件夹:
Annotations:将生成的trainval文件夹和test文件夹下的xml文件放入其中。
JPEGImages:将trainval文件夹和test文件夹下的图片都放入其中。
ImageSets:在其中生成Main文件夹,存放后面训练将用到的trainval.txt和test.txt。
2、在 examples 目录下创建 Caltech文件夹,存放指向生成的 lmdb 数据的软链接;
3、在 data 目录下创建 自己的目录 Caltech文件夹,存放数据转换命令:
将 data/VOC0712 下的 create_list.sh, create_data.sh, labelmap_voc.prototxt 这三个文件复制到 Caltech目录下,重命名为: create_list_caltech.sh, create_data_caltech.sh, labelma_caltech.prototxt
4、对上面三个文件进行修改
(1)修改create_list_caltech.sh,主要是修改路径,如下图所示:

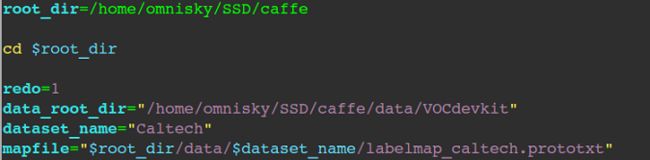
(2)修改create_data_caltech.sh,如下图所示

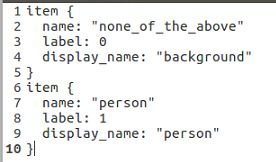
(3)修改labelmap_voc.prototxt,主要修改为数据集的类别信息,只有行人和背景,如下图所示
(4)创建Main中的trainval.txt和test.txt文件。
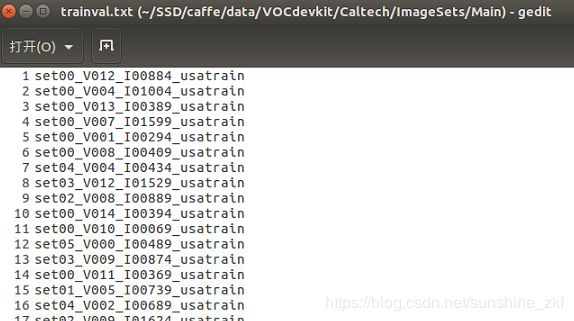
首先将同一label的train数据集放到一个文件夹内,在该文件夹目录下打开terminal输入find -name "*.jpg*" > trainval.txt,这样就可以将该文件夹内所有的图片全部存到txt中;
![]()
删除后缀和前缀
5、在caffe_SSD根目录下执行:
1 ./data/Caltech/create_list_caltech.sh在目录caffe_SSD_root/data/Caltech下生成以下三个txt文件:
trainval.txt :每一行保存了图像文件的路径和图像标注文件的路径,中间以空格分开。
test.txt :每一行保存了图像文件的路径和图像标注文件的路径,中间以空格分开。
test_name_size.txt :记录每张测试图像的height和width。
2 ./data/Caltech/create_data_caltech.sh
在caffe_SSD_root/data/VOCdevkit/Caltech/lmdb目录下生成了LMDB格式的文件。