1. 引言
抓取58同城中的手机号类目下所有帖子的标题和链接, 并将结果存储在mongodb中
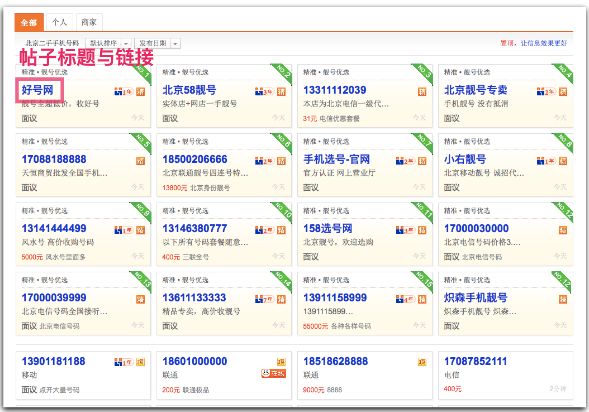
Paste_Image.png
取出存储在mongodb中的链接, 获取详情页中的信息
Paste_Image.png
网址: http://bj.58.com/shoujihao/pn1/
2. 分析
- 列表页随url中的最后一个数字增加而增加
- 列表首页有推广信息, 推广链接中带有
jump字样 - 从mongodb中取出存储好的url, 获取详情信息
3. 实现部分
# vim spider_shoujihao.py
代码
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
__author__ = 'jhw'
from bs4 import BeautifulSoup
from pymongo import MongoClient
import requests
# 连接mongo数据库
client = MongoClient('10.66.17.17', 27017)
database = client['58tongcheng']
# 存放url信息的collection
url_info = database['shoujihao_url']
# 存放item信息的collection
item_info = database['shoujihao_item']
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36',
}
# 定义获取手机号信息的函数
def get_url_info(url):
data = requests.get(url, headers=headers)
soup = BeautifulSoup(data.text, 'lxml')
# 判断是否到了列表尾部
if len(soup.select('.boxlist a.t')) == 0:
print('*'*20, 'End of the pages...', '*'*20)
print(url)
return 1
else:
titles = soup.select('.boxlist a.t > strong')
urls = soup.select('.boxlist a.t')
for title, url in zip(titles, urls):
# 过虑推广信息
if 'jump' in url.get('href'):
print('Advertising info, Pass...')
else:
data = {
'title': title.get_text(),
'url': url.get('href').split('?')[0],
}
print(data)
# 将url信息插入mongodb中
url_info.insert_one(data)
def get_item_info(url):
data = requests.get(url, headers=headers)
soup = BeautifulSoup(data.text, 'lxml')
titles = soup.select('.mainTitle h1')
updates = soup.select('li.time')
prices = soup.select('.price.c_f50')
data = {
# 去掉多余的字符
'title': titles[0].get_text().replace('\n', '').replace('\t', '').replace(' ', ''),
'price': prices[0].get_text().replace('\n', '').replace('\t', '').replace(' ', ''),
'update': updates[0].get_text().replace('\n', '').replace('\t', '').replace(' ', ''),
}
print(data)
# 将item信息插入mongodb中
item_info.insert_one(data)
# 定义包含所有列表页的列表
url_list = ['http://bj.58.com/shoujihao/pn{}/'.format(i) for i in range(1, 200)]
# 逐一抓取列表页中的手机号信息
for url in url_list:
# 至列表尾部了就退出
if get_url_info(url):
break
# 从mongodb中取出url, 获取其详细信息
for url in url_info.find():
get_item_info(url['url'])
# python3 spider_shoujihao.py
结果
{'url': 'http://bj.58.com/shoujihao/26587258835761x.shtml', 'title': '13911877000'}
{'url': 'http://bj.58.com/shoujihao/26587259235500x.shtml', 'title': '15652002222'}
{'url': 'http://bj.58.com/shoujihao/26587260023234x.shtml', 'title': '15652333362'}
.
.
.
{'url': 'http://bj.58.com/shoujihao/26587240534580x.shtml', 'title': '18910353708'}
{'url': 'http://bj.58.com/shoujihao/26587241641547x.shtml', 'title': '15652112222'}
******************** End of the pages... ********************
http://bj.58.com/shoujihao/pn117/
{'price': '440元', 'title': '13911677825移动', 'update': '2016-07-06'}
{'price': '9576元', 'title': '18801301999动感地带媛媛一号店', 'update': '2016-07-06'}
{'price': '500元', 'title': '13366553236电信套餐任意改', 'update': '2016-07-06'}
.
.
.
{'price': '350元', 'title': '13126964333移动微信更多号码', 'update': '2016-07-06'}
{'price': '600元', 'title': '15311116287电信无低消可过户', 'update': '2016-07-06'}
4. 总结
-
string信息中无用的字符可以用replace替换掉 - 不存在的列表页网页组成部分有别于包含信息的页面