分布式日志分析系统(二):Zipkin的介绍以及在Elasticsearch的部署
0、引言
继上一节之后,顺带看了下zipkin在elasticsearch上的部署应用,自己倒腾了一阵子,写下这篇博客,希望能够帮助到有需要的朋友,也方便自己之后的查看。
1、zipkin简介
zipkin是一款开源的分布式实时数据追踪系统(Distributed Tracking System),基于 Google Dapper的论文设计而来,由 Twitter 公司开发贡献。其主要功能是聚集来自各个异构系统的实时监控数据。
主要有三个应用场景:
- 故障快速定位
通过分析调用链,可以将一次请求的逻辑轨迹完整清晰的展示出来,通过在开发中在业务日志中添加调用链ID,可以通过调用链结合业务日志快速定位错误信息。
- 性能分析
在调用链的各个环节分别添加调用时延,可以分析系统的性能瓶颈,进行有针对性的优化。
- 服务可用性
通过分析各个环节的平均时延,QPS等信息,可以找到系统的薄弱环节,对一些模块做调整,例如数据冗余、链路可用等。
zipkin架构图如下:

zipkin主要有以下四个模块:
- Collector:接收各service传输的数据;
- Storage:存储收集过来的数据,当前支持Cassandra,Redis,HBase,MySQL,PostgreSQL, SQLite等,默认存储在内存中;
- API(Query)负责查询Storage中存储的数据,提供简单的JSON API获取数据,主要提供给web UI使用;
- Web 提供简单的web界面
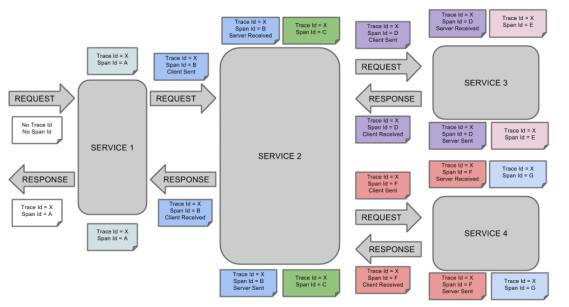
这里简单地介绍span,对于链路追踪理解有很大的帮助:
Zipkin 以 Trace 结构表示对一次请求的追踪,又把每个 Trace 拆分为若干个有依赖关系的 Span。在微服务架构中,一次用户请求可能会由后台若干个服务负责处理,那么每个处理请求的服务就可以理解为一个 Span(可以包括 API 服务,缓存服务,数据库服务以及报表服务等)。当然这个服务也可能继续请求其他的服务,因此 Span 是一个树形结构,以体现服务之间的调用关系。
基础数据,包括traceId、spanId、parentId、name、timestamp和duration,主要用于跟踪树中节点的关联和界面展示。
traceId:全局跟踪ID,用它来标记一次完整服务调用,所以和一次服务调用相关的span中的traceId都是相同的,Zipkin将具有相同traceId的span组装成跟踪树来直观的将调用链路图展现在我们面前。
spanid:span的id,理论上来说,span的id只要做到一个traceId下唯一就可以。
parentId:父span的id,调用有层级关系,所以span作为调用节点的存储结构,也有层级关系,跟踪链是采用跟踪树的形式来展现的,树的根节点就是调用的顶点,其中parentId为null的Span将成为跟踪树的根节点来展示,当然它也是调用链的起点。
name:span的名称,主要用于在界面上展示,一般是接口方法名,name的作用是让人知道它是哪里采集的span。
timestamp:span创建时的时间戳,用来记录采集的时刻。
duration:持续时间,即span的创建到span完成最终的采集所经历的时间,除去span自己逻辑处理的时间,该时间段可以理解成对于该跟踪埋点来说服务调用的总耗时,timestamp+duration将表示成调用的结束时间。
Annotation,注解,用来记录请求特定事件相关信息(例如时间),通常包含四个注解信息。
2、zipkin安装
上链接:https://search.maven.org/remote_content?g=io.zipkin.java&a=zipkin-server&v=LATEST&c=exec
下载的是最新的jar包,然后打开下载的目录,执行命令:
java -jar zipkin-server-2.10.3-exec.jar
把版本号替换成你下载的即可,然后就可以运行浏览器检查下:你的本地ip:9411,9411为zipkin默认的端口号,回车一下:
3、Demo下载、运行;
参考文章:https://blog.csdn.net/qq924862077/article/details/80314258 中的代码,谢谢大牛帮忙写了Demo,于是我直接借用大牛在GitHub的代码,在IDEA进行运行;
文件夹中有四个Demo:分别运行;然后用zipkin进行监听:
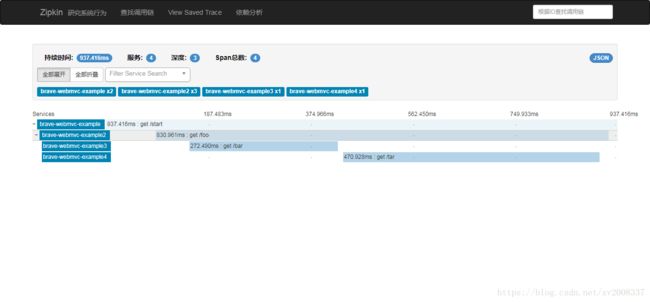
4、ZipKin连接Elasticsearch
执行这一步之前,先打开Elasticsearch(有安装head的话一起打开),确保都在运行中,然后:
java -DSTORAGE_TYPE=elasticsearch -DES_HOSTS=http://你的ip:9200 -jar zipkin-server-2.10.3-exec.jar运行后,打开浏览器,输入ip:9100,回车,界面如下:
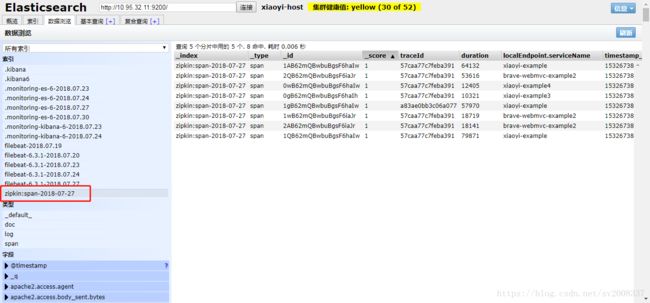
成功~
感谢同事的帮助~希望这一篇帖子对大家部署有所帮助~
参考资料:
1、https://www.sohu.com/a/140122885_610730
2、https://blog.csdn.net/qq924862077/article/details/80314258