LinkedHashMap源码解读
前言
之前在看HashMap的源码时看到几个空实现的函数,当时也没有在意,今天在了解LinkedHashMap时突然明白了那个空实现函数(钩子函数)的意义。
本文源码版本依旧是JDK1.8。
LinkedHashMap
钩子函数
首先先来看看HashMap中所谓的钩子函数。

为什么在HashMap中会有这几个空实现的钩子函数呢,原因很简单,因为HashMap的子类要用啊。接着往下看就会明白这几个类的奥秘了。
Entry的继承关系
LinkedHashMap中也实现了内部类Entry,并且继承于HashMap.Node。
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
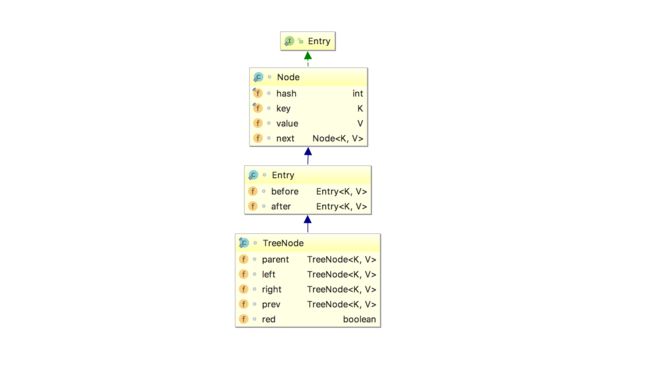
从上面的这张图中也可以很容易的看LinkedHashMap中Entry的继承关系,至于其中的TreeNode,emmmm,可以不用管它,因为这张图是我在网上偷的,hhh。
LinkedHashMap的继承关系
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>
已经很明显了这里就不说了。
LinkedHashMap的成员变量
private static final long serialVersionUID = 3801124242820219131L;
/**
* 指向双向链表的头部
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* 指向双向链表的尾部
*/
transient LinkedHashMap.Entry<K,V> tail;
/**
* 用来指定LinkedHashMap的迭代顺序
* 为true -- 则按照访问顺序来排列,即将最新访问的节点放在链表的尾部(LRU)
* 为false -- 则按照节点插入顺序来排列(FIFO)
*/
final boolean accessOrder;
如果不懂head、tail没关系,看了下面LinkedHashMap的数据结构就会明白了。
LinkedHashMap的数据结构

我们都知道HashMap的数据结构是数组+链表+红黑树的结构,其实LinkedHashMap只是在HashMap的基础上多了一个双向链表,如上图红色箭头所示。head与tail分别指向双向链表的首部与尾部。
到了这里对于LinkedHashMap应该也有了一个大体的了解了吧。因为HashMap内部是无序,如果我们想要得到一个有序的,并基于键值对存储,那么赶快newLinkedHashMap吧。
LinkedHashMap的构造函数
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
这个构造函数和HashMap的没有多大区别,不同的在于accessOrder的指定,accessOrder为true,则LinkedHashMap是一个LRU结构。为false,则是一个FIFO结构。
LinkedHashMap的get()方法
public V get(Object key) {
Node<K,V> e;
//调用HashMap的getNode方法
if ((e = getNode(hash(key), key)) == null)
return null;
//如果accessOrder为true,则需要将get的节点放到双向链表的尾部
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
LinkedHashMap的get()方法是通过多态调用的,并且在LinkedHashMap中调用的是HashMap的getNode()方法,不同的地方在于accessOrder。如果为true,则需要保证LinkedHashMap的LRU结构,在afterNodeAccess()方法中会将getNode()返回得到的节点放在双向链表的尾部。
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
//p为头部,前一个节点b不存在,则将p的下一个节点a设置为头部
if (b == null)
head = a;
else
b.after = a;
//p是尾部,后一个节点a不存在,则将p的上一个节点b设置为last
if (a != null)
a.before = b;
else
last = b;
//链表中只有p一个节点,则将p直接设置为head
if (last == null)
head = p;
//将p插在链表的最后
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
如果我们getNode()返回的节点是p,那么将p插到双向链表的尾部有以下几种情况。
- 如果p是链表中间的节点,则直接将p的前后节点相连,把p放到链表尾巴上。
- 如果p为头部,则它的前一个节点b不存在,将p的下一个节点a设置为头部。
- 如果p是尾部,则它的后一个节点a不存在,将p的上一个节点b设置为last。
- 如果链表中只有p一个节点,则head = p。
LinkedHashMap的put()方法
我在LinkedHashMap的方法中没有找到put方法。。。。因为这里调用的是父类HashMap的get()方法。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
...
...
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
...
...
...
if (e != null) { // existing mapping for key
...
afterNodeAccess(e);
return oldValue;
}
}
...
afterNodeInsertion(evict);
return null;
}
这里我省略了一些不必要的代码,全部的代码大家可以自行去HashMap中看。
在HashMap的put()方法中我们可以看到两个钩子函数。afterNodeAccess()、afterNodeInsertion()。其中的一个钩子函数在上面已经说过了,下面就只说另外一个钩子函数以及newNode()这个方法。
//newNode()方法
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
//如果last为空,则p设置为head
if (last == null)
head = p;
//否则将p接在链表尾巴上
else {
p.before = last;
last.after = p;
}
}
由于LinkedHashMap中重写了newNode()这个方法,因此在调用HashMap的put方法进行元素插入时,会通过多态调用子类的newNode方法,并将创建的这个节点放在双向链表的尾部。
//afterNodeInsertion()方法
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
//removeEldestEntry(first)返回总是false,所以这又是一个钩子函数,留着给子类使用
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
afterNodeInsertion()的作用是插入一个节点后,会将双向链表的头节点删掉,但是看源码会发现在LinkedHashMap中removeEldestEntry的返回值总是false,因此这里不会删除头节点,由此我们可知这又是一个钩子函数,将留给LinkedHashMap的子类去实现。
当我们需要实现一个LRU的LinkedHashMap时,可以重写removeEldestEntry方法,移除头节点,来实现淘汰最近最久未使用的元素(在上面的get()方法中说了,每当get一个节点,会将该节点放在链表的尾部,所有说链表的尾部存放的都是最近使用过的节点元素)。
LinkedHashMap的remove()方法
在HashMap的remove方法中留有一个afterNodeRemoval()钩子函数,依旧是用于LinkedHashMap调用父类的remove方法时使用。
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
//如果p是头部,则将p的下一个节点设置为head
if (b == null)
head = a;
else
b.after = a;
//如果链表中本来就只有p一个节点,则移除p节点后,将tail设置为null(b = p.before b是null)
if (a == null)
tail = b;
else
a.before = b;
}
总结
LinkedHashMap是在HashMap的基础上维护一个双向链表,来得到一个有序的排列,其中可以有两种排列方式,一种是按照插入顺序进行排列,一种是按照get元素进行排列,将最近get到的元素放在双向链表的尾部。
另外,LinkedHashMap的实现是通过重写HashMap中预留的钩子函数来实现的,可见jdk源码设计者的用心良苦吖。