【CTR预估】The Wide and Deep Learning Model(译文+Tensorlfow源码解析)
本文主要讲解Google的Wide and Deep Learning 模型。本文先从原始论文开始,先一步步分析论文,把论文看懂。再去分析官方开源的Tensorflow源码,解析各个特征的具体实现方法,以及模型的具体构造方法等。
我在github开源来一个自己写的关于ctr预估模型的库,里面复现了一些经典的网络,如DIN,ESMM,DIEN,DeepFM等。当然其中也包含了wide and deep model,感兴趣的可以看看:
https://github.com/Shicoder/Deep_Rec/tree/master/Deep_Rank
先上图

1.论文翻译
ABSTRACT
Generalized linear models with nonlinear feature transformations are widely used for large-scale regression and classification problems with sparse inputs. Memorization of feature interactions through a wide set of cross-product feature transformations are effective and interpretable, while generalization requires more feature engineering effort. With less feature engineering, deep neural networks can generalize better to unseen feature combinations through low-dimensional dense embeddings learned for the sparse features. However, deep neural networks with embeddings can over-generalize and recommend less relevant items when the user-item interactions are sparse and high-rank. In this paper, we present Wide & Deep learning—jointly trained wide linear models and deep neural networks—to combine the benefits of memorization and generalization for recommender systems. We productionized and evaluated the system on Google Play, a commercial mobile app store with over one billion active users and over one million apps. Online experiment results show that Wide & Deep significantly increased app acquisitions compared with wide-only and deep-only models. We have also open sourced our implementation in TensorFlow.
译文:
通过将稀疏数据的非线性转化特征应用在广义线性模型中被广泛应用于大规模的回归和分类问题。通过广泛的使用交叉特征转化,使得特征交互的记忆性是有效的,并且具有可解释性,而然不得不做许多的特征工作。相对来说,通过从稀疏数据中学习低纬稠密embedding特征,并应用到深度学习中,只需要少量的特征工程就能对潜在的特征组合具有更好的范化性。但是当用户项目交互是稀疏和高纬数据的时候,利用了embeddings的深度学习则表现得过于笼统(over-generalize),推荐的都是些相关性很低的items。在这篇文章中,我们提出了一个wide and deep 联合学习模型,去结合集合推荐系统的memorization和generalization。我们评估在Google Play上评估了该方法,在线实验结果显示,相比于单个的wide或者deep模型,WD模型显著的增加了app获取率。我们在tensorflow上开源了该源码。
点评:
提出了一个结合使用了非线性特征的线性模型和一个用来embedding特征的深度学习,并且使用联合训练的方法进行优化。思想是,基于交叉特征的线性模型只能从历史出现过的数据中找到非线性(显性的非线性),深度学习可以找到没有出现过的非线性(隐形的非线性)。
INTRODUCTION
A recommender system can be viewed as a search ranking system, where the input query is a set of user and contextual information, and the output is a ranked list of items. Given a query, the recommendation task is to find the relevant items in a database and then rank the items based on certain objectives, such as clicks or purchases.
One challenge in recommender systems, similar to the general search ranking problem, is to achieve both memorization and generalization. Memorization can be loosely defined as learning the frequent co-occurrence of items or features and exploiting the correlation available in the historical data.Generalization, on the other hand, is based on transitivity of correlation and explores new feature combinations that have never or rarely occurred in the past. Recommendations based on memorization are usually more topical and directly relevant to the items on which users have already performed actions. Compared with memorization, generalization tends to improve the diversity of the recommended items. In this paper, we focus on the apps recommendation problem for the Google Play store, but the approach should apply to generic recommender systems.
译文:
推荐系统可以被看做是一个搜索排序系统,其中输入的query是一系列的用户和文本信息,输出是items的排序列表。给定一个query,推荐的任务就是到数据库中去找出相关的items,然后对这些items根据相关对象,如点击或者购买行为,进行排序。
和传统的搜索排序问题一样,在推荐系统中,一个挑战就是区域同时达到memorization和generalization。Memorization可以被大概定义为学习items或者features之间的相关频率,在历史数据中探索相关性的可行性。Generalizaion的话则是基于相关性的传递,去探索一些在过去没有出现过的特征组合。基于memorization的推荐相对来说具有局部性,是在哪些用户和items已经有直接相关联的活动上。相较于memorization,generalization尝试去提高推荐items的多元化。在这篇paper中,我们主要关注Google Play 商店的app推荐问题,但是该方法对推荐系统具有通用性。
点评:
这里我没有对memorization和generalization进行翻译,因为我也不知道怎么翻译,memorization的话就是去把历史数据中显性的非线性找出来,generalization的就是范化性,就是把一些隐性的找出来。
For massive-scale online recommendation and ranking systems in an industrial setting, generalized linear models such as logistic regression are widely used because they are simple, scalable and interpretable. The models are often trained on binarized sparse features with one-hot encoding. E.g., the binary feature “user_installed_app=netflix ”has value 1 if the user installed Netflix. Memorization can be achieved effectively using cross-product transformations over sparse features, such as AND( user_installed_app=netflix, impression_app=pandora”), whose value is 1 if the user installed Netflix and then is later shown Pandora. This explains how the co-occurrence of a feature pair correlates with the target label. Generalization can be added by using features that are less granular, such as AND ( user_installed_category=video, impression_category=music ), but manual feature engineering is often required. One limitation of cross-product transformations is that they do not generalize to query-item feature pairs that have not appeared in the training data.
译文:
在工业中,对于大规模的在线推荐和排序系统,想逻辑回归这样的广义线性模型应用是相当广泛的,简单,伸缩性好,可解释性强。可以喂给它一些one-hot编码的稀疏特征,比如二值特征‘user_installed_app=netfix’表示用户安装了Netflix。Memorization则可以通过对稀疏特征做交叉积转换获得,就是求交叉特征,比如AND操作 (user_installed_app= netflix, impression_app=pandora )这两个特征,当用户安装了Netflix并且之后展示在Pandora上,那么得到特征的值为1,其余为0.这个交叉特征就展示了特征对之间的相关性和目标lable之间的关联。Generalization可以通过增加一些粗粒度的特征实现,如AND(user_installed_category=video, impression_category=music ),但是这写都是需要手工做特征工程实现。交叉积转换的一个限制就是他们不能生成从未在训练数据中出现过的query-item特征对。
点评:
这里主要是对接下来线性模型需要的特征做了下解释,一个是one-hot,比较稀疏。一个是交叉特征,简单的说就是AND,就是特征之间做笛卡尔积。用于线性模型去寻找显性的非线性。
Embedding-based models, such as factorization machines[5] or deep neural networks, can generalize to previously unseen query-item feature pairs by learning a low-dimensional dense embedding vector for each query and item feature, with less burden of feature engineering. However, it is difficult to learn effective low-dimensional representations for queries and items when the underlying query-item matrix is sparse and high-rank, such as users with specific preferences or niche items with a narrow appeal. In such cases, there should be no interactions between most query-item pairs, but dense embeddings will lead to nonzero predictions for all query-item pairs, and thus can over-generalize and make less relevant recommendations. On the other hand, linear models with cross-product feature transformations can memorize these “exception rules” with much fewer parameters.
译文:
像FM或者DNN,这种基于embedding的模型,是对预先没出现的query-item特征对有一定范化性,通过为每个query和item特征学习一个低纬稠密的embedding向量,而且不需要太多的特征工程。但是如果潜在的query-item矩阵是稀疏,高秩的话,为query和items学习出一个有效的低纬表示往往很困难,比如基于特殊爱好的users,或者一些很少出现的小众items。在这种情况下,大多数的query-item没有交互,但是稠密的embedding还是会对全部的query-item对有非零的输出预测,因此能做出一些过范化和做出一些不太相关的推荐。另一方面,利用交叉积特征的线性模型能用很少的参数记住那些‘exception_rules’。
点评:
讲了下深度网络需要的特征,embedding特征,就是把稀疏数据映射到稠密的低纬数据。
In this paper, we present the Wide & Deep learning framework to achieve both memorization and generalization in one model, by jointly training a linear model component and a neural network component as shown in Figure 1.
The main contributions of the paper include:
• The Wide & Deep learning framework for jointly training feed-forward neural networks with embeddings and linear model with feature transformations for generic recommender systems with sparse inputs.
• The implementation and evaluation of the Wide & Deep recommender system productionized on Google Play, a mobile app store with over one billion active users and over one million apps.
• We have open-sourced our implementation along with a high-level API in TensorFlow.
While the idea is simple, we show that the Wide & Deep framework significantly improves the app acquisition rate on the mobile app store, while satisfying the training and serving speed requirements.
译文:
在这篇paper里,我们提出一个wide&Deep学习框架,以此来同时在一个模型中获得Memorization和generalization,并联合训练之。
本文的主要贡献:
1.联合训练使用了embedding的深度网络和使用了交叉特征的线性模型。
2.WD系统在Google Play上投入使用。
3.在Tensrolfow开源代码。
尽管idea简单,但是wd显著的提高了app获取率,且速度也还可以。
RECOMMENDER SYSTEM OVERVIEW
An overview of the app recommender system is shown in Figure 2. A query, which can include various user and contextual features, is generated when a user visits the app store. The recommender system returns a list of apps (also referred to as impressions) on which users can perform certain actions such as clicks or purchases. These user actions, along with the queries and impressions, are recorded in the logs as the training data for the learner. Since there are over a million apps in the database, it is intractable to exhaustively score every app for every query within the serving latency requirements (often O(10) milliseconds). Therefore, the first step upon receiving a query is retrieval. The retrieval system returns a short list of items that best match the query using various signals, usually a combination of machine-learned models and human-defined rules. After reducing the candidate pool, the ranking system ranks all items by their scores. The scores are usually P(y|x), the probability of a user action label y given the features x, including user features (e.g., country, language, demographics), contextual features (e.g., device, hour of the day, day of the week), and impression features (e.g., app age, historical statistics of an app). In this paper, we focus on the ranking model using the Wide & Deep learning framework.

图2展示了app推荐系统的概括图。
query:当用户访问app store的时候生成的许多用户和文本特征。
推荐系统返回一个app列表(也被叫做展示(impressions)),然后用户能在这些展示的app上进行确切的操作,比如点击或者购买。这些用户活动,以及queries和impressions都被记录下来作为训练数据。
因为数据库中有过百万的apps,所以对全部的app计算score不合理。因此,收到一个query的第一步是retrieval(检索)。检索系统返回一个items的短列表,这个列表是通过机器学习和人工定义的大量标记找出来的,和query最匹配的一个app列表。然后减少了候选池后,排序系统通过对这些items按score再对其进行排序。而这个scores通常就是给定的特征x下,用户行为y的概率值
P(y|x)。特征x包括一些用户特征(国家,语言。。。),文本特征(设备。使用时长。。。)和展示特征(app历史统计数据。。。)。在本论文中,我们主要关注的是将WD模型用户排序系统。
WIDE&DEEP LEARNING
The Wide Component
The wide component is a generalized linear model of the form y = wT x + b, as illustrated in Figure 1 (left). y is the prediction, x = [x1, x2, …, xd] is a vector of d features, w =[w1, w2, …, wd] are the model parameters and b is the bias.The feature set includes raw input features and transformed features. One of the most important transformations is the cross-product transformation, which is defined as:

where cki is a boolean variable that is 1 if the i-th feature is part of the k-th transformation φk, and 0 otherwise.For binary features, a cross-product transformation (e.g.,“AND(gender=female, language=en)”) is 1 if and only if the constituent features (“gender=female” and “language=en”) are all 1, and 0 otherwise. This captures the interactions between the binary features, and adds non linearity to the generalized linear model.
译文:
模型中Wide模块是一个形如 y = W T X + b y=W^{T}X+b y=WTX+b的广义线性模型,如图1左所示。 y y y是预测值, X = [ x 1 , x 2 , . . . , x d ] X=[x_{1},x_{2},...,x_{d}] X=[x1,x2,...,xd]是d维特征的一个向量,其中 W = [ w 1 , w 2 , . . . , w d ] W=[w_{1},w_{2},...,w_{d}] W=[w1,w2,...,wd]是模型的参数,b是偏置项。特征集包含了原始输入特征和转化后的特征。其中最重要的就是交叉积转换特征,可以被定义为:
其中 c k i c_{ki} cki是一个boolean值变量,当第i个特征是第k个转换 ϕ k \phi_{k} ϕk,否则的就是0。对于一个二进制特征,交叉积特征可以简单理解为AND(gender=female,language=en),当且仅当gender=female,language=en时,交叉特征为1,其他都为0。该方法能捕捉出特征间的交互,为模型添加非线性。
点评:
就是生成交叉特征
The Deep Component
deep模块则是一个前向神经网络,如图1右,对于类别特征,原始输入特征其原始输入都是字符串形式的特征,如“language=en".我们把这些稀疏,高维的类别特征转换为低纬稠密的实值向量,这就是embedding向量。embedding随机初始化,并利用反向传播对其进行更新。将高维的特征换换为embedding特征后,这些低维的embedding向量就被fed到神经网络中,每个隐藏层做如下计算:
![]()
其中l是网络的层数,f是激活函数,一般用RELU, a l , b l , W l a^{l},b^{l},W^{l} al,bl,Wl分别为第l层的激活函数,偏置项,模型权值。
点评:
其实就是说输入的类别特征是字符串,得转化下,然后做embedding,模型是一个全连接。
Joint Training of Wide & Deep Model
通过将Wide模块和Deep模块的对数加权输出作为预测值,然后将其fed给一个常规的逻辑损失函数中,用于联合训练。需要注意的是,联合训练和ensemble是由区别滴。在集成方法中,模型都是独立训练的,模型之间没有关系,他们的预测输出只在最后才合并。但是,联合训练的话,两个模型是一起训练所有参数。对于模型大小来说,集成方法,因为模型之间独立,所以单个模型的大小需要更大,即需要更多的特征和特征工程。以此起来获得合理的精度。但是联合训练,两个模块只要互相补充对方不足即可。
WD模型的联合训练通过反向传播将输出值的误差梯度通过最小批随机梯度同时传送给Wide和Deep模块。在实验中,我们使用带 L 1 L_{1} L1的FTRL算法作为wide模块的优化器,使用AdaGrad更新deep模块。
结合的模型在图1(中)。对于逻辑回归问题,我们模型的预测是:
P ( Y = 1 ∣ X ) = σ ( W w i d e T [ X , ϕ ( X ) ] + W d e e p T a l f + b ) P(Y=1|X)=\sigma(W_{wide}^{T}[X,\phi(X)]+W_{deep}^{T}a^{l_{f}}+b) P(Y=1∣X)=σ(WwideT[X,ϕ(X)]+WdeepTalf+b) (3)
其中Y是一个二值的类别标签, σ ( ) \sigma() σ()是sigmoid函数, ϕ ( x ) \phi(x) ϕ(x)表示交叉特征, b b b是一个bias项, W w i d e W_{wide} Wwide是Wide模型的权值, W d e e p W_{deep} Wdeep是应用在最后的隐藏层输出上的权值。
点评:
一个是联合训练,就是一起训练呗,一个是优化器,分别为FTRL和AdaGrad。最后是将两个模型的输出加起来。 W d e e p W_{deep} Wdeep其实就是隐藏层到输出层的权值。
Data Generation
In this stage, user and app impression data within a period of time are used to generate training data. Each example corresponds to one impression. The label is app acquisition:1 if the impressed app was installed, and 0 otherwise. Vocabularies, which are tables mapping categorical feature strings to integer IDs, are also generated in this stage. The system computes the ID space for all the string features that occurred more than a minimum number of times. Continuous real-valued features are normalized to [0, 1] by mapping a feature value x to its cumulative distribution function P(X ≤ x), divided into nq quantiles. The normalized value is i−1 nq−1 for values in the i-th quantiles. Quantile boundaries are computed during data generation.
译文:
app推荐主要由三个阶段组成,data generation,model training,model serving。图3所示。
数据生成阶段,就是把之前的用户和app展示数据用于生成训练数据。每个样本对应一个展示,标签是app acquisition:如果展示的app被安装了则为1,否则为0。
Vacabularies,是一些将类别特征字符串映射为整型的ID。系统计算为哪些出现超过设置的最小次数的字符串特征计算ID空间。连续的实值特征通过映射特征x到它的累积分布P(X<=x),将其标准化到[0,1],然后在离散到nq个分位数。这些分位数边界也是在该阶段计算获得。
点评:
将整个推荐过程分为三部分,一:数据生成,为线性模型创建交叉特征,为深度模型创建embedding特征。对字符串类型的类别特征做整型转换。

Model Training
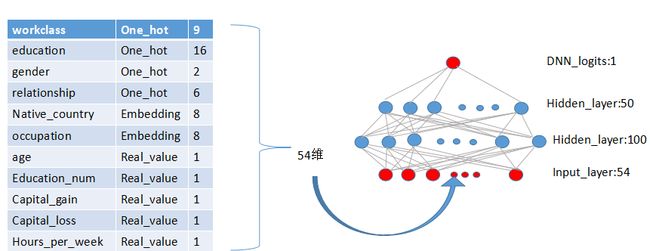
The model structure we used in the experiment is shown in Figure 4. During training, our input layer takes in training data and vocabularies and generate sparse and dense features together with a label. The wide component consists of the cross-product transformation of user installed apps and impression apps. For the deep part of the model, A 32 dimensional embedding vector is learned for each categorical feature. We concatenate all the embeddings together with the dense features, resulting in a dense vector of approximately 1200 dimensions. The concatenated vector is then fed into 3 ReLU layers, and finally the logistic output unit. The Wide & Deep models are trained on over 500 billion examples. Every time a new set of training data arrives, the model needs to be re-trained. However, retraining from scratch every time is computationally expensive and delays the time from data arrival to serving an updated model.
To tackle this challenge, we implemented a warm-starting system which initializes a new model with the embeddings and the linear model weights from the previous model. Before loading the models into the model servers, a dry run of the model is done to make sure that it does not cause problems in serving live traffic. We empirically validate the model quality against the previous model as a sanity check.
译文:
我们在实验中所用的模型结构展示在图4中。训练阶段,我们的输入层吸收训练数据,词汇,生成稀疏和稠密特征。Wide模块包含用户安装的app和展示的app的交叉特征。对于深度模块,我们为每个类别特征学习了32维的emedding特征。并将全部的embedding特征串联起来,获得一个近似1200维的稠密向量。并将该向量传入3层的RELU隐层,最终获得逻辑输出单元。
WD将被训练在超过5000亿的样本上。每次一个新的训练数据达到,模型需要重新训练。但是,重新训练费时费力。为了克服这个挑战,我们实现了一个热启动系统,我们使用预先的模型权值去初始化新模型权值。
在加载模型到模型server之前,为确保模型在实时情况下不会出现问题,我们对模型进行了预先模拟。
Model Serving
Once the model is trained and verified, we load it into the model servers. For each request, the servers receive a set of app candidates from the app retrieval system and user features to score each app. Then, the apps are ranked from the highest scores to the lowest, and we show the apps to the users in this order. The scores are calculated by running a forward inference pass over the Wide & Deep model. In order to serve each request on the order of 10 ms, we optimized the performance using multithreading parallelism by running smaller batches in parallel, instead of scoring all candidate apps in a single batch inference step.
译文:
一旦模型完成训练和验证,我们就将它放到模型server中。对每次请求,server都会从app检索系统获得一个app候选集,然后,对这些app利用模型计算的成绩排序,我们再按该顺序显示app。
为了使得能在10ms内响应请求,我们利用多线程并行运行小批次数据来代替对全部候选集在单个batch上打分,一次优化时间。
实验
后面是实验部分,不再翻译。
代码分析
该模型的Tenflow源码最近好像更新过了,和之前所用的模块也不一样了,之前的特征构建都是使用的tf.contrib模块,现在的代码使用的是tf.feature_column,之前的模型在tf.contrib.learn.DNNLinearCombinedClassifier,现在的版本在tf.estimator.DNNLinearCombinedClassifier。不过我试了下,之前的代码是能用的,说明两个都存在。(TF有点臃肿了),我就按我down下来的代码来分析吧,之前那个有大神分析的相当透彻:http://geek.csdn.net/news/detail/235465(完美,跪舔)。
数据
人口普查数据
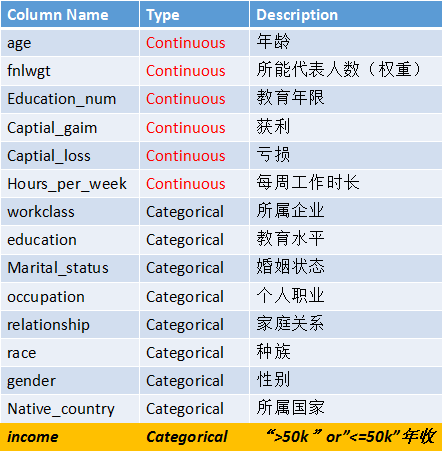
分别有连续性数据和类别数据,最后一类离散化后作为标签
用jupyter notebook看了下据大概长这样子

选出了几个类别(教育年份,职业、国家),看了下,是这样子的,有的类别值比较多,有的少点。

数据的输入
数据用的是pandas读取,直接将原始数据传入,并以原始数据的列名作为key,为之后的做特征工作做准备,之后所有的特征工作都是基于原始数据的key来构造的。
具体可看下图,

特征工程
Feature_column模块自带的函数有这么几个:
‘crossed_column’,
‘numeric_column’,
‘bucketized_column’,‘
‘categorical_column_with_hash_bucket’,
‘categorical_column_with_vocabulary_file’,
‘categorical_column_with_vocabulary_list’,
‘categorical_column_with_identity’,
‘weighted_categorical_column’,
‘indicator_column’,
crossed_column用于构造交叉特征,numeric_column用于处理实值,bucketized_column用于离散连续特征,categorical_column_with_hash_bucket将类别特征hash到不同bin中,categorical_column_with_vocabulary_file将类别特征的所有取值保存在文件中,categorical_column_vocabulary_list将类别特征的所有取值保存在list中,categorical_column_with_identity返回的是和特征本身一样的id,weighted_categorical_column是加权用的,indicator_column用来对类别特征做one-hot。
下面,我针对demo展开讲一下这几个方法
1.针对取值较少的类别特征,demo里使用了tf.feature_column.categorical_column_with_vocabulary_list()方法将类别特征从字符串类型映射到整型。比如性别特征,原始数据集中的取值为Femal或者Male,这样我们就可以将其通过
gender = tf.feature_column.categorical_column_with_vocabulary_list(
"gender", ["Female", "Male"])
把字符串Female和Male按其在vocabulary中的顺序,从0开始,按序编码,这里的话就是Female:0;Male:1。
categorical_column_with_vocabulary_list()方法中还有一个参数是oov,意思就是out of vocabulary,就是说如果数据没有出现在我们定义的vocabulary中的话,我们可以将其投到oov中。其实这个方法的底层就是一个将String映射到int的一个hashtable。
2.针对那些不清楚有多少个取值的类别特征,或者说取值数很多的特征,可以使用tf.feature_column.categorical_column_with_hash_bucket()方法,思想和categorical_column_with_vocabulary_list一样,因为我们不知道类别特征的取值,所以没法定义vocabulary。所以可以直接利用hash方法将其直接hash到不同的bucket中,该方法将特征中的每一个可能的取值散列分配一个整型ID。比如
occupation = tf.feature_column.categorical_column_with_hash_bucket(
"occupation", hash_bucket_size=1000)
这段代码就是讲occupation中的取值,哈希到1000个bucket中,这1000个bucket分别为0~999,那么occupation中的值就会被映射为这1000个中的一个整数。
if self.dtype == dtypes.string:
sparse_values = input_tensor.values
else:
sparse_values = string_ops.as_string(input_tensor.values)
sparse_id_values = string_ops.string_to_hash_bucket_fast( sparse_values, self.hash_bucket_size, name='lookup')
底层做的就是讲String转化为整型,然后再做hash,其实干的就是这么回事:
output_id = Hash(input_feature_string) % bucket_size
3.连续性变量
对于连续型变量就没啥说的,就是将其转化为浮点型
# Continuous base columns.
age = tf.feature_column.numeric_column("age")
education_num = tf.feature_column.numeric_column("education_num")
capital_gain = tf.feature_column.numeric_column("capital_gain")
capital_loss = tf.feature_column.numeric_column("capital_loss")
hours_per_week = tf.feature_column.numeric_column("hours_per_week")
4.对于分布不平均的连续性变量
对于一些每个段分布密度不均的连续性变量可以做分块,所以有了如下函数tf.feature_column.bucketized_column()。
连续型特征通过 bucketization 生成离散特征,boundaries 是一个浮点数的列表,而且列表必须是递增序的,如下代码
age_buckets = tf.feature_column.bucketized_column(
age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65])
这里就是讲age按给定的boundaries分成11个区域,比如样本的age是34,那么输出的就是3,age是21,那么输出的就是1。
5.交叉特征
交叉特征是为了找出一些非线性的特征,tf.feature_column.crossed_column()。如
tf.feature_column.crossed_column( ["education", "occupation"], hash_bucket_size=1000)
就是讲education和occupation做交叉,然后再做hash。
如下是源码中的一个例子,
SparseTensor referred by first key:
shape = [2, 2] {
[0, 0]: "a"
[1, 0]: "b"
[1, 1]: "c"
}
SparseTensor referred by second key:
shape = [2, 1]
{
[0, 0]: "d"
[1, 0]: "e"
}
then crossed feature will look like:
shape = [2, 2]{
[0, 0]: Hash64("d", Hash64("a")) % hash_bucket_size
[1, 0]: Hash64("e", Hash64("b")) % hash_bucket_size
[1, 1]: Hash64("e", Hash64("c")) % hash_bucket_size
这里的[0,0]表示的是输入batch_size含有值的坐标(就是sparseTensor,tensorflow里的sparseTensor定义就是由三个denseTensor组成,一个id,用于表示那个位置有值,一个value,用于表示这个位置上的值是多少,还有一个shape,用于表示数据的shape),像第一个key第一个样本只有[0,0],即只有第一个位置有值,第二个样本有[1,0],[1,1],那么说明其第一个维度和第二个维度都有值。
借用下前面提到过的那位大神画的图

本例的交叉特征做的就是这么回事,一行表示一个样本。
6.indicator特征,因为dnn是不能直接输入sparseColumn的,怎么说呢,之前那些类别特征处理好后,全是将string转化成了int,但是针对每个取值返回的还是一个整形的id值,我们不可能直接将该id传入网络,但是线性模型可以直接将这类特征做embedding,来实现线性模型。
接着看,具体的方法是tf.feature_column.indicator_column(),该方法主要讲一些类别特征进行one-hot编码,如果是多值的就进行multi-hot编码,底层调用的就是_IndicatorColumn()类,其实现就是一个one-hot()
one_hot_id_tensor = array_ops.one_hot(
dense_id_tensor,
depth=self._variable_shape[-1],
on_value=1.0,
off_value=0.0)
如果是多值的特征,在参数返回的时候回将各个one-hot编码进行压缩
return math_ops.reduce_sum(one_hot_id_tensor, axis=[-2])
Embedding_column
tf.feature_column.embedding_column(native_country, dimension=8)
看了下底层实现,相当于建了一个表,从表里去取embedding向量。
可以看这张图,

大概就是这么个意思,按id从矩阵表里取embedding向量。
具体实现在
return _EmbeddingColumn( categorical_column=categorical_column, dimension=dimension, combiner=combiner, initializer=initializer, ckpt_to_load_from=ckpt_to_load_from, tensor_name_in_ckpt=tensor_name_in_ckpt, max_norm=max_norm, trainable=trainable)
然后其初始化了embedding矩阵
embedding_weights = variable_scope.get_variable(
name='embedding_weights',
shape=(self.categorical_column._num_buckets, self.dimension),
dtype=dtypes.float32,
initializer=self.initializer,
trainable=self.trainable and trainable,
collections=weight_collections)
这个权值矩阵,其实相当于神经网络的权值,后续如果是trainable的话,我们就会把这个当做网络的权值矩阵进行训练,但是在用的时候,就把这个当成一个embedding表,按id去取每个特征的embedding。
取的时候是去_safe_embedding_lookup_sparse()按id取embedding。
为了防止矩阵过大,其底层还实现了矩阵的分块,就是将一个大矩阵分成几个小矩阵,所以有一个;partition_strategy
其定义了两种取数据的方式
https://stackoverflow.com/questions/34870614/what-does-tf-nn-embedding-lookup-function-do
这里分析的挺详细,说白了就是很多个矩阵现在来个id怎么去取数据,那肯定是按表取,每个表取完了再去取下一个表,这就是mod;或者一个一个来,这个表取一个,下一个表取一个,按顺序依次从各个表取,就是div。
模型的构造
m = tf.estimator.DNNLinearCombinedClassifier(
model_dir=model_dir,
linear_feature_columns=crossed_columns,
dnn_feature_columns=deep_columns,
dnn_hidden_units=[100, 50])
模型的构造直接调用该方法,该方法继承自Estimator。
class DNNLinearCombinedClassifier(estimator.Estimator)
具体实现在
_dnn_linear_combined_model_fn
主要做两件事,定义好优化器,架好模型结构(顶层的输出和loss等单独定义在head中)

DNN模型构建
先造输入层
net = feature_column_lib.input_layer()

其实就是按每个特征的维度建立节点,然后把全部的特征合起来输出为output_tensors。当然输入时按batch_size输入的。可以看出来,网络的数据是直接按batch_size来的,应该一次训练就是一个batch_size的数据,而不是一个一个的算,在按batch_size加起来。
输入层造好了,就是按自己传入的隐藏层节点数构造隐藏层。

他这里能改的只有激活函数,节点个数,权值的初试化方式是默认的,没有提供接口。
最后就是输出

输出层的节点,像这里因为是二分类,所以输出层的节点只有一个,这里head.logits_dimension获取的就是二分类问题的输出节点个数。如果是多分类,几分类最后的节点个数就是几,三分类那么输出的节点就是3。这里也可以发现,最后这里是没有激活函数的,因为等下要和线性模型加起来才一起输入的sigmoid函数里去。这里的dnn_logits就是deep部分的输出了。
这里做的就是这么一件事:
Linear模块
线性模型的话就是去做 y = W T X + b y=W^{T}X+b y=WTX+b一个东西,很简单,具体在linear_logits = feature_column_lib.linear_model()函数实现,这里和一般的线性模型不一样的是,它对类别特征和实值特征具体实现的方法有所不一样。
for column in sorted(feature_columns, key=lambda x: x.name):
with variable_scope.variable_scope(None, default_name=column.name):
ordered_columns.append(column)
if isinstance(column, _CategoricalColumn):
weighted_sums.append(_create_categorical_column_weighted_sum(
column, builder, units, sparse_combiner, weight_collections,
trainable))
else:
weighted_sums.append(_create_dense_column_weighted_sum(
column, builder, units, weight_collections, trainable))
针对categorical_column和dense_column其实现的时候分别使用embedding和矩阵乘积。分别在_create_categorical_column_weighted_sum()和_create_dense_column_weighted_sum()里实现。并将每个特征的实现加到weighted_sum中做汇总。
_create_categorical_column_weighted_sum()
weight = variable_scope.get_variable(
name='weights',
shape=(column._num_buckets, units), # pylint: disable=protected-access
initializer=init_ops.zeros_initializer(),
trainable=trainable,
collections=weight_collections)
return _safe_embedding_lookup_sparse(
weight,
id_tensor,
sparse_weights=weight_tensor,
combiner=sparse_combiner,
name='weighted_sum')
可以看到,其先用全0初始化了一个权值矩阵,再去调用_safe_embedding_lookup_sparse去取权重值,其实就是一个embedding的过程。
_create_dense_column_weighted_sum()
对于其他实值特征的话,就比较直接了

最后再把输出的weighted_sum都加起来,再加个bias就可以了
predictions_no_bias = math_ops.add_n(
weighted_sums, name='weighted_sum_no_bias')
bias = variable_scope.get_variable(
'bias_weights',
shape=[units],
initializer=init_ops.zeros_initializer(),
trainable=trainable,
collections=weight_collections)
predictions = nn_ops.bias_add(
predictions_no_bias, bias, name='weighted_sum')
简单画个图,其实就是这么回事

combine
if dnn_logits is not None and linear_logits is not None:
logits = dnn_logits + linear_logits
如图:

最后把两个模型的输出,直接加起来,送到sigmoid里去,再用交叉熵计算loss,这些都在head_lib._binary_logistic_head_with_sigmoid_cross_entropy_loss()里面完成了。
loss的反向传播,也很直接
`def _train_op_fn(loss):
“”“Returns the op to optimize the loss.”"" ……
……
if dnn_logits is not None:
train_ops.append(
dnn_optimizer.minimize(
loss, ……
……)
if linear_logits is not None:
train_ops.append(
loss, ……
……)
其实我不是特别理解,感觉线性模型的收敛速度,肯定比网络要快很多,那怎么去保证两边收敛情况呢?当然正则做得好,只要不过拟合,最后应该都会收敛得比较好。
还有就是这个版本的wd代码和之前版本的wd代码有一些差异,参数方面,默认的学习率其做了一定的调整,之前的center_bias,现在没有了。