【Graph Embedding】:Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba
本文是阿里在kdd2018发表的关于使用graph embedding作为淘宝首页推荐召回策略的算法实现。现在利用图embedding来做召回算是业界最前沿的技术,下面我们来看看淘宝是如何来用户行为转化为图,以及从图中学习出item的embdding。
论文下载地址:https://arxiv.org/abs/1803.02349
介绍
淘宝应该是国内最大的C2C平台,平台上承载着10亿的用户量和20亿的商品量,这么大的用户量和商品就会出现问题,主要有三点
1.可扩展性(Scalability):很多算法在面对海量数据的时候都会失效,不管是计算量还是算法本身。
2.稀疏性(Sparsity): 想象一下,这么大的商品量,用户不可能看过所有的商品,别说所有,看过其中万分之一商品的可能性都没有,所有数据会存在严重的稀疏性问题,而且这么大的用户量,很多用户本身的交互也很少,所有很难训练一个精确的推荐模型出来。
3.冷启动(Cold Start): 淘宝每小时都会有数百万的新商品被上传上去,而这些用户没有任何的与用户的交互,这些冷启动数据将很难处理。
现在业界针对海量数据的推荐框架都是分为两层,阿里也一样,分别是召回层(matching)和排序层(ranking)。在召回层从海量的数据中,根据用户的交互行为过滤出一个较小的数据子集,然后再根据召回的数据集进一步对其排序,选出topn用户可能最喜欢的商品进行推荐。
本文的主要目的是为了解决matching阶段的问题,核心的任务是为了学习出item之间的相似性。像传统的方法一般是基于协同过滤(CF)来比较item之间的相似性,但是这样的相似性都是基于item之间的共现关系计算出来的,并没有考虑到时序之间的关联。
为了达到这个目的,文章提出使用用户的历史交互行为来构建item graph,然后利用现在前沿的graph embedding算法训练item 的embdding。文章针对具体的业务由简到繁设计来三个graph embedding的算法。第一个就是直接利用item构建graph的方法,叫做BGE(Base Graph Embedding),但是前面也说了,对于那些冷启动的数据,其交互行为很少,甚至没有,这样就很难学习出有效的embedding向量。为了能让这部分数据也可以学习出有效的embdding向量,文章进一步对BGE进行改进,尝试引入side information来增强embedding过程,这个方法被称为GES(Graph Embedding with Side information)。这些side information就是如item的类目,品牌,价格等item的基础信息,比如同一家店铺的同一种款式的衣服我们可以认为它们之间是很相似的。像airbnb在处理类似冷启动问题的时候,也采用来类似的方法,不过它们是直接利用多个类似的其他item embedding的均值来代替。进一步的既然要合并多种边界信息,BGE的话直接将多种信息进行合并,没有考虑到不同边界信息之间的差异,所以进一步提出了一个方法EGES(Enhanced Graph Embedding with Side information),该方法是针对BGE的改进,在边界信息合并的时候对不同边界信息做加权再合并。
所以本文主要贡献有以下三点:
1.基于多年的实践经验,设计来一个启发式的方法,在淘宝10多亿用户的行为历史上构建来item graph。
2.提出来三种embdding方法,BGE,GES,EGES用于学习淘宝平台上20亿商品的embdding值。并离线验证EGES和GES相比BGE和其他embedding方法带来的效果优势。
3.第三点工业实现,将该方法部署上线,构建了graph embedding 系统。
框架
本文提出的graph embedding方法是在DeepWalk进行优化的。给定一个图:![]() ,其中V和E分别代表图中的节点集合和边的集合。graph embedding的目的就是为了学习出在空间
,其中V和E分别代表图中的节点集合和边的集合。graph embedding的目的就是为了学习出在空间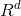 能代表每个节点
能代表每个节点![]() 的一个低纬表示。简单的说,我们要做的就是把graph中的每个节点从V维映射到d维度,就是要学习一个映射函数:
的一个低纬表示。简单的说,我们要做的就是把graph中的每个节点从V维映射到d维度,就是要学习一个映射函数:![]()
DeepWalk的思想来自word2vec,先用随机游走(random walk)从graph中生成节点序列,有了序列后再用skip-gram(word2vec的一种实现)来实现graph中的每个节点的embedding,所以问题就转化为优化如下问题:
![]()
其中,N(v)是节点v的邻节点,可以理解为图中节点邻近n跳的节点,这个n是指定的数值。![]() 就是在节点v的前提下,上下文为c的概率。
就是在节点v的前提下,上下文为c的概率。
根据用户行为构建item graph
前面大概奖了算法的思路,现在来讲一下具体怎么通过用户行为来构建这个item graph。

实际中用户按时间访问item是个序列,如图2(a)所示。一般同一个用户的访问记录会按时间间隔对其进行划分,形成session。
文章就是将session按有向边的方式连接起来,比如将图2(a)的session全部连接起来就形成来图2(b)的graph。并且根据所有session的共现关系,给graph中每条边附上一个权重,这个权重就是在所有用户交互行为中,边连接的item i向item j转移的次数。
当然在实际使用中,数据肯定存在噪声,需要对做一些处理,来消除噪声,比如如下噪声:
1.在点击后停留的时间少于1秒,可以认为是误点,需要移除。
2.还有一些过度活跃用户,三月内购买商品数超过1000,或者点击数超过3500,就可以认为是一个无效用户,需要去除。
3.还有一些商品频繁的修改商品内容的,造成前后同一id的商品信息不对应,需要移除。
基本图embedding(BGE)
前面的一系列操作后,就可以获得商品的加权有向图了,表示为![]() ,就可以利用DeepWalk来学习图G中的节点embedding。先讲一下随机游走(random walk)的思想,如何利用随机游走在图(graph)中生成序列。假设M是G的邻接矩阵,
,就可以利用DeepWalk来学习图G中的节点embedding。先讲一下随机游走(random walk)的思想,如何利用随机游走在图(graph)中生成序列。假设M是G的邻接矩阵, 表示从节点i指向节点j的加权边,那么随机游走的转移概率定义为:
表示从节点i指向节点j的加权边,那么随机游走的转移概率定义为:

其中![]() 表示的是所有节点
表示的是所有节点 的下一一跳节点集合,可以看出随机游走是按边的权重分配的概率值。通过这个概率值就可以从图中获取到大量的序列。
的下一一跳节点集合,可以看出随机游走是按边的权重分配的概率值。通过这个概率值就可以从图中获取到大量的序列。
再接着就利用skip-gram来学习embedding的值,这里的思想就和item2vec相似了,把每个item id看成是词,整个序列看成句子,然后做word2vec。优化目标如下:
![]()
这里的w就是再做skip-gram是选择的窗口大小,假设节点v_i到各个窗口内节点的概率独立,就可以得到记一步的优化函数:

然后就是加入负采样,这个为了减少计算量,做的近似,神经网络优化里一个常见的trick:

其中,V(vi)′是对于vivi的负采样,σ()是sigmoid函数。经验上,∣N(vi)′∣越大,获得的结果越好。
基于边界信息的图 embedding(Graph Embedding with Side Information)
上面的基本图模型存在一个问题,那就是对于那些新的商品由于缺少交互行为,所以和这些商品交互的边会很少,这样的话这些商品学习出来的embedding也不会有效。针对这些冷启动的问题,文章对BGE做了修改,加入side information来对基于id的embedding做补充。比如优衣库的两款卫衣很可以是很相似的,一个喜欢尼康镜头的用户,也很可以对尼康的相机感兴趣。所以进一步提出来如下图所示的GES方法 :

图表示的是从graph中获取到序列后的框架图,图中SI是side information的缩写,SI 0表示的是item自身,可以理解为item id,后面的SI 1,SI 2...这些都是不同的边界信息。看图从下往上看,最下面的SI 0,SI 1,... 都是稀疏特征,所以先做one-hot,然后将one-hot值映射到第二层的embedding空间,再进一步利用skip-gram学习出中间层的hidden representation。
清晰点说,如果使用W来表示SI的embedding矩阵,那么![]() 表示的是item v自身的embedding向量,可以把这个看成一个表,根据v的id去取它对应的embedding向量,并且这个向量是可以训练的。同理
表示的是item v自身的embedding向量,可以把这个看成一个表,根据v的id去取它对应的embedding向量,并且这个向量是可以训练的。同理![]() 是item v的第s个side information的embedding。具体怎么把这些矩阵合并起来呢?GES的方法是保证每个side information矩阵的embedding长度一致,然后把他们都按位加起来求平均。
是item v的第s个side information的embedding。具体怎么把这些矩阵合并起来呢?GES的方法是保证每个side information矩阵的embedding长度一致,然后把他们都按位加起来求平均。
如这样:

这里的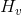 就被用来表示最终的item embedding。
就被用来表示最终的item embedding。
增强式的GES(Enhanced Graph Embedding with Side Information)
上面的GES中有个问题是,针对每个item,它把所有的side information embedding求和后做了平均,那么就存在一个问题,不同类型的商品,不同价格的商品,到底哪个维度的信息权重大,这个是没有被考虑进去的,所以最好能对每个边界信息在进行embedding聚合的时候能做个加权,EGES做的就是这个事。
整体的框架一样,为了让不同类型的side information具有不同的权重,提出来一个加权平均的方法来聚集这些边界embedding。
因为每个item对其不同边界信息的权重都不一样,所以就需要额外大小为v*(n+1)的一个矩阵来表示每个item对边界信息的权值,v是item的个数,n是边界信息的个数,加1是还要考虑item自身的权重。假设![]() 是权重矩阵,那么里面的项Aij就是第i个item、第j个类型的side information的权重。矩阵第一列还是用来表示自身的权重。这样就可以获得加权平均的方法:
是权重矩阵,那么里面的项Aij就是第i个item、第j个类型的side information的权重。矩阵第一列还是用来表示自身的权重。这样就可以获得加权平均的方法:

这里对权重项 做了指数变换,目的是为了保证每个边界信息的贡献都能大于0
做了指数变换,目的是为了保证每个边界信息的贡献都能大于0
其他的和前面的方法都一直,整体的算法逻辑如下图:


结果
结果不用说,效果肯定好,这里主要说两个东西
一个是离线评估。因为是图,所以离线评估用的是link prediction的方法,将图中1/3的边随机移除,作为测试集,然后训练模型去预测这些这些边出现的概率。测试的负样本选择是随机选择没有连接的节点对作为负样本。然后使用auc评价整体的模型。
第二个是它们整体的框架图

可以稍微了解以下。
完