CS229第一课——线性回归
CS229第一课
- 线性回归
- 1 LMS算法
- 2 正规方程
- 2.1 矩阵微积分
- 2.2 最小二乘新解释
- 3 概率解释
- 4 局部加权线性回归
线性回归
我们以下方的一个例子来讲解线性回归过程。

在该例子中,输入数据 x x x是一个二维变量, x 1 ( i ) x^{(i)}_1 x1(i)代表第 i i i个数据样本中的第一个特征值(在实际情况中我们需要自己来选择进行训练的特征数,我们会在之后讲解特征选择的方法,目前该例子中使用2个特征进行学习)。
为了进行学习,我们需要定义一个hypothesis,我们使用 x \mathbf{x} x的线性方程来近似 y y y,如下所示
y = θ 0 + θ 1 x 1 + θ 2 x 2 y = \theta_0+\theta_1 x_1+\theta_2 x_2 y=θ0+θ1x1+θ2x2
在此处 θ \theta θ是一个参数(权重)用来将输入的数据 x \mathbf{x} x映射到输出 y y y。为了方便编写,我们定义 x 0 = 1 x_0=1 x0=1,则上式可以修改为
y = ∑ i = 1 n θ i x i = θ T x y=\sum_{i=1}^n\theta_ix_i=\mathbf{\theta}^T\mathbf{x} y=i=1∑nθixi=θTx
接下来,为了学习合适的参数 θ \theta θ,我们需要定义一个损失函数来描述预测值与实际值之间的距离,定义如下
J = 1 2 ∑ i = 1 m ( h ( x i ) − y i ) 2 J=\frac{1}{2}\sum_{i=1}^m(h(x^{i})-y^{i})^2 J=21i=1∑m(h(xi)−yi)2
1 LMS算法
我们需要学习一个参数向量 θ \mathbf{\theta} θ来最小化损失函数 J ( θ ) J(\mathbf{\theta}) J(θ),我们一般使用梯度下降法来学习 θ \mathbf{\theta} θ值,该算法学习过程如下所示
θ j = θ j − α ∂ ∂ θ j J ( θ ) \theta_j = \theta_j-\alpha\frac{\partial}{\partial\theta_j}J(\mathbf{\theta}) θj=θj−α∂θj∂J(θ)
为了方便描述,我们首先假设训练数据集中只有一个样本,则训练的梯度下降如下所示。
θ j = θ j − α ∂ ∂ θ j J ( θ ) = θ j − α ∂ ∂ θ j ( 1 2 ( h ( x ) − y ) 2 ) = θ j − α ∂ ∂ θ j ( 1 2 ( ∑ i = 1 n θ i x i − y ) 2 ) = θ j − α ( ∑ i = 1 n θ i x i − y ) 2 x j \begin{aligned} \theta_j &= \theta_j-\alpha\frac{\partial}{\partial\theta_j}J(\theta) \\ &=\theta_j-\alpha\frac{\partial}{\partial\theta_j}(\frac{1}{2}(h(x)-y)^2)\\ &=\theta_j-\alpha\frac{\partial}{\partial\theta_j}(\frac{1}{2}(\sum_{i=1}^n\theta_ix_i-y)^2)\\ &=\theta_j-\alpha(\sum_{i=1}^n\theta_ix_i-y)^2x_j\\ \end{aligned} θj=θj−α∂θj∂J(θ)=θj−α∂θj∂(21(h(x)−y)2)=θj−α∂θj∂(21(i=1∑nθixi−y)2)=θj−α(i=1∑nθixi−y)2xj
这个更新规则称为LMS(最小均方误差),一般有两种方法来应用该规则。
一种是批量梯度下降,每一次更新参数值都需要应用所有的数据样本,如下所示。

梯度下降算法容易收敛到局部最优值,而在线性回归中,损失函数是凸函数,只存在一个全局最优值,因此能实现较好的收敛效果。
第二种应用LMS规则的方法是随机梯度下降,每利用一个数据样本就更新一次参数值,具体情况如下所示。
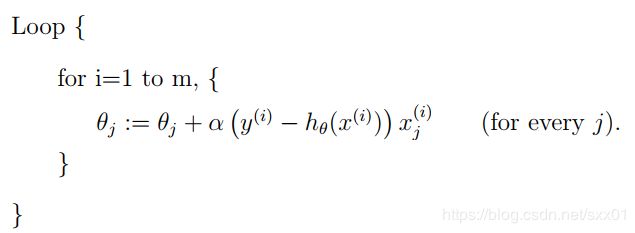
如果数据样本数量非常大,则批量梯度下降的更新速度太慢,随机梯度下降每针对一个样本就更新一次,因此能快速对参数进行更新,通常会比批量梯度下降更快收敛的“靠近”全局最优的位置,但一般不会收敛到最优值处。
2 正规方程
接下来考虑第二种方法来最小化损失函数 J J J,这种方法是通过将损失函数对应的 θ j \theta_j θj的导数值设为0来求解 θ \theta θ,为了介绍该方法,我们需要定义一些矩阵微积分符号。
2.1 矩阵微积分
定义一个函数 f f f,该函数能将一个 m × n m\times n m×n的矩阵映射成一个实数,我们定义函数 f f f关于矩阵 A A A的微积分如下。
∇ A f ( A ) = [ ∂ f ∂ A 11 ⋯ ∂ f ∂ A 1 n ⋮ ⋱ ⋮ ∂ f ∂ A m 1 ⋯ ∂ f ∂ A m n ] \nabla_Af(A) = \begin{bmatrix} \frac{\partial f}{\partial A_{11}} & \cdots & \frac{\partial f}{\partial A_{1n}} \\ \vdots & \ddots & \vdots \\ \frac{\partial f}{\partial A_{m1}} & \cdots & \frac{\partial f}{\partial A_{mn}} \end{bmatrix} ∇Af(A)=⎣⎢⎡∂A11∂f⋮∂Am1∂f⋯⋱⋯∂A1n∂f⋮∂Amn∂f⎦⎥⎤
接下来我们定义trace计算,即
t r A = ∑ i = 1 n A i i tr A = \sum_{i=1}^n A_{ii} trA=i=1∑nAii
如果我们有矩阵 A A A和 B B B,且 A B AB AB是一个方阵,则 t r A B = t r B A tr AB = tr BA trAB=trBA
证明:令 A A A为 m × n m\times n m×n的矩阵, B B B为 n × m n\times m n×m的矩阵,则 A B AB AB为 m × m m\times m m×m的矩阵, B A BA BA为 n × n n\times n n×n的矩阵,令 A B = C AB = C AB=C, A B = D AB = D AB=D,因此
t r A B = ∑ i = 1 m C i i = ∑ i = 1 m ( ∑ j = 1 n ( A i j B j i ) ) t r B A = ∑ i = 1 n D i i = ∑ j = 1 n ( ∑ i = 1 m ( A i j B j i ) ) \begin{aligned} tr AB &= \sum_{i=1}^m C_{ii} \\ &= \sum_{i=1}^m (\sum_{j=1}^n(A_{ij}B_{ji})) \\ tr BA &= \sum_{i=1}^n D_{ii} \\ &= \sum_{j=1}^n (\sum_{i=1}^m(A_{ij}B_{ji})) \\ \end{aligned} trABtrBA=i=1∑mCii=i=1∑m(j=1∑n(AijBji))=i=1∑nDii=j=1∑n(i=1∑m(AijBji))
因此 t r A B = t r B A tr AB = tr BA trAB=trBA,证毕。
有这个推论我们可以得出
t r A B C = t r C A B = t r B C A tr ABC = tr CAB = tr BCA trABC=trCAB=trBCA
此外trace计算还有以下的性质:
t r A T = t r A t r ( A + B ) = t r A + t r B t r a A = a t r A tr A^T = tr A \\ tr (A+B) = tr A + tr B \\ tr aA =a tr A trAT=trAtr(A+B)=trA+trBtraA=atrA
矩阵微积分有着以下的性质,其中| A A A|代表 A A A的行列式
∇ A t r A B = B T ∇ A T f ( A ) = ( ∇ A f ( A ) ) T ∇ A t r A B A T C = C B A + C T A B T ∇ A ∣ A ∣ = ∣ A ∣ ( A − 1 ) T \begin{aligned} \nabla_A tr AB &= B^T \\ \nabla_{A^T} f(A) &= (\nabla_A f(A))^T \\ \nabla_A trABA^TC &= CBA + C^TAB^T \\ \nabla_A |A| &= |A|(A^{-1})^T \end{aligned} ∇AtrAB∇ATf(A)∇AtrABATC∇A∣A∣=BT=(∇Af(A))T=CBA+CTABT=∣A∣(A−1)T
2.2 最小二乘新解释
利用上述提到的矩阵微积分来对最小二乘进行求解,我们首先将损失函数 J ( θ ) J(\theta) J(θ)写成矩阵-向量格式。
对于给定的数据集,我们将其定义为 m × n m\times n m×n的矩阵 X \mathbf{X} X,该矩阵为
X = [ ( x ( 1 ) ) T ( x ( 2 ) ) T ⋮ ( x ( m ) ) T ] \mathbf{X} = \begin{bmatrix} (x^{(1)})^T \\ (x^{(2)})^T \\ \vdots \\ (x^{(m)})^T \end{bmatrix} X=⎣⎢⎢⎢⎡(x(1))T(x(2))T⋮(x(m))T⎦⎥⎥⎥⎤
并且将标签数据定义为m维的向量 Y \mathbf{Y} Y,该向量为
Y = [ ( y ( 1 ) ) ( y ( 2 ) ) ⋮ ( y ( m ) ) ] \mathbf{Y} = \begin{bmatrix} (y^{(1)}) \\ (y^{(2)}) \\ \vdots \\ (y^{(m)}) \end{bmatrix} Y=⎣⎢⎢⎢⎡(y(1))(y(2))⋮(y(m))⎦⎥⎥⎥⎤
则
X θ − Y = [ h θ ( x ( 1 ) ) − y ( 1 ) h θ ( x ( 2 ) ) − y ( 2 ) ⋮ h θ ( x ( m ) ) − y ( m ) ] \mathbf{X}\theta-\mathbf{Y} = \begin{bmatrix} h_{\theta}(x^{(1)})-y^{(1)} \\ h_{\theta}(x^{(2)})-y^{(2)} \\ \vdots \\ h_{\theta}(x^{(m)})-y^{(m)} \end{bmatrix} Xθ−Y=⎣⎢⎢⎢⎡hθ(x(1))−y(1)hθ(x(2))−y(2)⋮hθ(x(m))−y(m)⎦⎥⎥⎥⎤
损失函数定义为
J ( θ ) = 1 2 ( X θ − Y ) T ( X θ − Y ) J(\theta) = \frac{1}{2}(\mathbf{X}\theta-\mathbf{Y})^T(\mathbf{X}\theta-\mathbf{Y}) J(θ)=21(Xθ−Y)T(Xθ−Y)
因此
∇ θ J ( θ ) = ∇ θ ( 1 2 ( X θ − Y ) T ( X θ − Y ) ) = 1 2 ∇ θ ( θ T X T X θ − θ T X T Y − Y T X θ + Y T Y ) = 1 2 ∇ θ t r ( θ T X T X θ − θ T X T Y − Y T X θ + Y T Y ) = 1 2 ( ∇ θ t r ( θ T X T X θ ) − 2 ∇ θ t r Y T X θ ) = 1 2 ( X T X θ + X T X θ − 2 X T Y ) = X T X θ − X T Y \begin{aligned} \nabla_{\theta}J(\theta) &= \nabla_{\theta}( \frac{1}{2}(\mathbf{X}\theta-\mathbf{Y})^T(\mathbf{X}\theta-\mathbf{Y})) \\ &= \frac{1}{2}\nabla_{\theta} (\theta^T\mathbf{X}^T\mathbf{X}\theta-\theta^T\mathbf{X}^T\mathbf{Y}-\mathbf{Y}^T\mathbf{X}\theta+\mathbf{Y}^T\mathbf{Y}) \\ &=\frac{1}{2}\nabla_{\theta}tr(\theta^T\mathbf{X}^T\mathbf{X}\theta-\theta^T\mathbf{X}^T\mathbf{Y}-\mathbf{Y}^T\mathbf{X}\theta+\mathbf{Y}^T\mathbf{Y}) \\ &= \frac{1}{2}(\nabla_{\theta}tr(\theta^T\mathbf{X}^T\mathbf{X}\theta)-2\nabla_{\theta}tr\mathbf{Y}^T\mathbf{X}\theta) \\ &=\frac{1}{2}(\mathbf{X}^T\mathbf{X}\theta+\mathbf{X}^T\mathbf{X}\theta-2\mathbf{X^T}\mathbf{Y}) \\ &=\mathbf{X}^T\mathbf{X}\theta - \mathbf{X^T}\mathbf{Y} \end{aligned} ∇θJ(θ)=∇θ(21(Xθ−Y)T(Xθ−Y))=21∇θ(θTXTXθ−θTXTY−YTXθ+YTY)=21∇θtr(θTXTXθ−θTXTY−YTXθ+YTY)=21(∇θtr(θTXTXθ)−2∇θtrYTXθ)=21(XTXθ+XTXθ−2XTY)=XTXθ−XTY
令该微分式为0,则 X T X θ − X T Y = 0 \mathbf{X}^T\mathbf{X}\theta - \mathbf{X^T}\mathbf{Y}=0 XTXθ−XTY=0,可以得到
θ = ( X T X ) − 1 X T Y \theta = (\mathbf{X}^T\mathbf{X})^{-1}\mathbf{X}^T\mathbf{Y} θ=(XTX)−1XTY
3 概率解释
在进行线性回归训练的时候,为什么使用最小二乘作为损失函数?我们将会给出一些概率假设进行解释。
我们假设标签 y y y的值为 y ( i ) = θ T x ( i ) + ϵ y^{(i)} = \theta^Tx^{(i)}+\epsilon y(i)=θTx(i)+ϵ,其中第一项为我们的预测值,第二项为错误项(代表忽略的特征项或者随机噪声)。我们假设错误项 ϵ \epsilon ϵ的分布符合IID特点,并且符合均值为0、方差为 σ 2 \sigma^2 σ2,因此 ϵ ( i ) \epsilon^{(i)} ϵ(i)的概率密度为
p ( ϵ ( i ) ) = 1 2 π σ e x p ( − ( ϵ ( i ) ) 2 2 σ 2 ) p(\epsilon^{(i)})=\frac{1}{\sqrt{2\pi}\sigma}exp(-\frac{(\epsilon^{(i)})^2}{2\sigma^2}) p(ϵ(i))=2πσ1exp(−2σ2(ϵ(i))2)
给定输入数据 x ( i ) x^{(i)} x(i)和权重 θ \theta θ后,可以得到
p ( y ( i ) ∣ x ( i ) ; θ ) = 1 2 π σ e x p ( − ( y ( i ) − θ T x ( i ) ) 2 2 σ 2 ) p(y^{(i)}|x^{(i)};\theta) = \frac{1}{\sqrt{2\pi}\sigma}exp(-\frac{(y^{(i)}-\theta^Tx^{(i)})^2}{2\sigma^2}) p(y(i)∣x(i);θ)=2πσ1exp(−2σ2(y(i)−θTx(i))2)
该式中 p ( y ( i ) ∣ x ( i ) ; θ ) p(y^{(i)}|x^{(i)};\theta) p(y(i)∣x(i);θ)代表给定 x ( i ) x^{(i)} x(i)并由权重 θ \theta θ参数化的分布 y ( i ) y^{(i)} y(i),我们同样可以将 y ( i ) y^{(i)} y(i)的分布写为 y ( i ) ∣ x ( i ) ; θ ∼ N ( θ T x ( i ) , σ 2 ) y^{(i)}|x^{(i)};\theta \sim \mathcal{N}(\theta^Tx^{(i)}, \sigma^2) y(i)∣x(i);θ∼N(θTx(i),σ2)。
当给定输入矩阵 X \mathbf{X} X和参数 θ \theta θ后,关于输出数据 Y \mathbf{Y} Y的概率给定为 p ( Y ∣ X ; θ ) p(\mathbf{Y}|\mathbf{X};\theta) p(Y∣X;θ),当给定参数 θ \theta θ后,将该式定义为 Y \mathbf{Y} Y的函数。当我们将其视为关于 θ \theta θ的函数时,我们将其称为似然函数,定义为
L ( θ ) = L ( θ ; X , Y ) = p ( Y ∣ X ; θ ) L(\theta)=L(\theta;\mathbf{X},\mathbf{Y})=p(\mathbf{Y}|\mathbf{X};\theta) L(θ)=L(θ;X,Y)=p(Y∣X;θ)
由于我们将错误项 ϵ ( i ) \epsilon^{(i)} ϵ(i)定义为独立分布,因此可以得到
L ( θ ) = ∏ i = 1 m p ( y ( i ) ∣ x ( i ) ; θ ) = ∏ i = 1 m 1 2 π σ e x p ( − ( y ( i ) − θ T x ( i ) ) 2 2 σ 2 ) \begin{aligned} L(\theta) &= \prod_{i=1}^mp(y^{(i)}|x^{(i)};\theta) \\ &= \prod_{i=1}^m\frac{1}{\sqrt{2\pi}\sigma}exp(-\frac{(y^{(i)}-\theta^Tx^{(i)})^2}{2\sigma^2}) \end{aligned} L(θ)=i=1∏mp(y(i)∣x(i);θ)=i=1∏m2πσ1exp(−2σ2(y(i)−θTx(i))2)
在训练模型的时候,给定了输入数据 X \mathbf{X} X和标签数据 Y \mathbf{Y} Y,我们需要通过将该似然函数进行最大化,使给定的数据以最大的概率出现,从而选择合适的参数 θ \theta θ。为了使得求解方便,我们给似然函数增加一个对数操作,这样不会改变其递增性质,也方便求解,具体如下所示
l ( θ ) = l o g L ( θ ) = l o g ∏ i = 1 m 1 2 π σ e x p ( − ( y ( i ) − θ T x ( i ) ) 2 2 σ 2 ) = ∑ i = 1 m l o g 1 2 π σ e x p ( − ( y ( i ) − θ T x ( i ) ) 2 2 σ 2 ) = ∑ i = 1 m ( l o g 1 2 π σ − ( y ( i ) − θ T x ( i ) ) 2 2 σ 2 ) = m l o g 1 2 π σ − 1 σ 2 1 2 ∑ i = 1 m ( y ( i ) − θ T x ( i ) ) 2 \begin{aligned} l(\theta) &= logL(\theta) \\ &= log \prod_{i=1}^m\frac{1}{\sqrt{2\pi}\sigma}exp(-\frac{(y^{(i)}-\theta^Tx^{(i)})^2}{2\sigma^2}) \\ &= \sum_{i=1}^m log\frac{1}{\sqrt{2\pi}\sigma}exp(-\frac{(y^{(i)}-\theta^Tx^{(i)})^2}{2\sigma^2}) \\ &= \sum_{i=1}^m(log\frac{1}{\sqrt{2\pi}\sigma}-\frac{(y^{(i)}-\theta^Tx^{(i)})^2}{2\sigma^2})\\ &= mlog\frac{1}{\sqrt{2\pi}\sigma}-\frac{1}{\sigma^2}\frac{1}{2}\sum_{i=1}^m(y^{(i)}-\theta^Tx^{(i)})^2 \end{aligned} l(θ)=logL(θ)=logi=1∏m2πσ1exp(−2σ2(y(i)−θTx(i))2)=i=1∑mlog2πσ1exp(−2σ2(y(i)−θTx(i))2)=i=1∑m(log2πσ1−2σ2(y(i)−θTx(i))2)=mlog2πσ1−σ2121i=1∑m(y(i)−θTx(i))2
由于在上式中,第一项是定项,因此我们需要最小化第二项,也就是最小化 1 2 ∑ i = 1 m ( y ( i ) − θ T x ( i ) ) 2 \frac{1}{2}\sum_{i=1}^m(y^{(i)}-\theta^Tx^{(i)})^2 21∑i=1m(y(i)−θTx(i))2,因此我们将线性回归中的损失函数定义为最小二乘。
总结:给定了上述关于数据分布的假设后,线性回归的最小二乘对应于最大似然函数,因此使用最小二乘作为线性回归的损失函数是一种自然的选择。在我们之前的讨论中,我们训练的参数 θ \theta θ并不依赖于分布的方差 σ 2 \sigma^2 σ2,即使该方差是未知的结果也不会变化。
4 局部加权线性回归

如上图所示,不同的特征选择会导致我们训练出来的模型的性能表现不同,左侧的图属于欠拟合,右侧的图属于过拟合,在之后我们会详细介绍这些概念并且介绍自动选择特征的算法,在本节中,我们会介绍局部加权线性回归(LWR)算法,该算法假设有足够多的数据样本,那么特征的选择就不是很重要了。
在局部加权线性回归中,给定 x x x进行预测时,我们需要
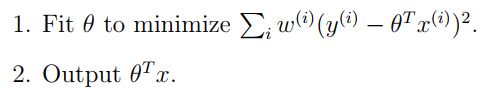
其中的 w ( i ) w^{(i)} w(i)是一个非负的权重值,该值的大小决定了我们对于错误项 ( y ( i ) − θ T x ( i ) ) 2 (y^{(i)}-\theta^Tx^{(i)})^2 (y(i)−θTx(i))2的重视程度,我们一般将该值定义为
w ( i ) = e x p ( − ( x ( i ) − x ) 2 2 τ 2 ) w^{(i)}=exp(-\frac{(x^{(i)}-x)^2}{2\tau^2}) w(i)=exp(−2τ2(x(i)−x)2)
当训练的数据点与要预测的点接近时,该权重值趋近于1,否则趋近于0,因此对于接近的点的重视程度会比较高。参数 τ \tau τ用来控制训练样本随着点 x ( i ) x^{(i)} x(i)与预测点 x x x的距离下降快慢的程度,称为带宽参数。
局部加权线性回归属于非参数算法,表示在使用该算法进行预测的时候,我们需要保留整个训练集;而之前学习的线性回归属于参数化算法,因为一旦参数固定后我们不需要再使用训练数据集。