前言
小的时候心中总有十万个为什么类似的问题,今天带大家爬取一个问答类的网站。
本堂课使用正则表达式对文本类的数据进行提取,正则表达式是数据提取的通用方法。
环境介绍:
python 3.6
pycharm
requests
re
json
爬虫的一般思路
1、确定爬取的url路径,headers参数
2、发送请求 -- requests 模拟浏览器发送请求,获取响应数据
3、解析数据 -- re模块:提供全部的正则表达式功能
4、保存数据 -- 保存json格式的数据
完整步骤:
1、安装库和导入模块
如果没有安装库的,可以WIN+R,然后输入cmd,最后输入代码安装
pip install requests
安装完成后可以输入代码查看你安装过所有的库:
pip list
导入模块
import requests import re import json
2、确定爬取的url路径,headers参数
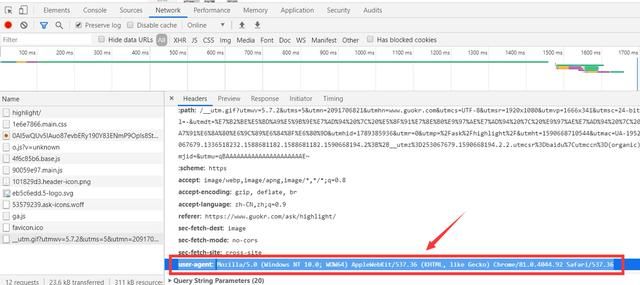
base_url = 'https://www.guokr.com/ask/highlight/' headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
3、发送请求 -- requests 模拟浏览器发送请求,获取响应数据
response = requests.get(base_url, headers=headers)
data = response.text
4、解析数据 -- re模块:提供全部的正则表达式功能
href="https://www.guokr.com/question/669761/">印度人把男人的生殖器叫林伽,把女人的生殖器叫瑜尼,林伽和瑜尼的交合,便是瑜伽。这是真还是假的编译正则表达式 预编译的代码对象比直接使用字符串要快,因为解释器在执行字符串形式的代码前都必须把字符串编译成代码对象
pattern = re.compile('(.*?)
', re.S) pattern_list = pattern.findall(data) # -->list # json [{[]}]{} # 构建json数据格式 data_list = [] for i in pattern_list: data_dict = {} data_dict['title'] = i[1] data_dict['href'] = i[0] data_list.append(data_dict)
5、保存json格式的文件
with open("guoke01.json", 'w', encoding='utf-8') as f: f.write(json_data_list)
6.构建一个循环爬取
for page in range(1, 101): print("====正在爬取第{}业数据====\n".format(page))
优化代码,把page传递进去
base_url = 'https://www.guokr.com/ask/highlight/?page={}'.format(str(page))
把列表添加到for循环上面去
data_list = []
最后运行代码,效果如下图: