YOLOv3原理及代码解析
博主完整翻译了YOLOV1和YOLOV3的论文;请移步查看:
YOLOV1:https://blog.csdn.net/taifengzikai/article/details/81988891
YOLOV3:https://blog.csdn.net/taifengzikai/article/details/100903687
YOLO v3原理及代码解析
YOLO是一种端到端的目标检测模型。YOLO算法的基本思想是:首先通过特征提取网络对输入特征提取特征,得到特定大小的特征图输出。输入图像分成13×13的grid cell,接着如果真实框中某个object的中心坐标落在某个grid cell中,那么就由该grid cell来预测该object。每个object有固定数量的bounding box,YOLO v3中有三个bounding box,使用逻辑回归确定用来预测的回归框。
一、YOLO结构
Yolo系列里,作者只在v1的论文里给出了结构图,而v2和v3的论文里没有给出结构图。但是清晰的结构图对于理解和学习Yolo十分重要。在“木盏”的CSDN博客上,找到了一份完整的Yolo v3结构图。经博主同意之后,我拿到了高清原图,如图1.1。Yolo v3整个结构,不包括池化层和全连接层。Yolo主干结构是Darknet-53网络,还有 Yolo预测支路采用的都是全卷积的结构。
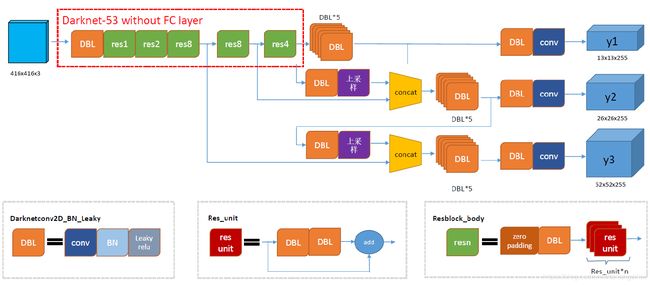
图1.1中的DBL是Yolo v3的基本组件。正如yolo3.model中的DarknetConv2D_BN_Leaky函数所定义的那样,Darknet的卷积层后接BatchNormalization(BN)和LeakyReLU。除最后一层卷积层外,在yolo v3中BN和LeakyReLU已经是卷积层不可分离的部分了,共同构成了最小组件。
主干网络中使用了5个resn结构。n代表数字,有res1,res2, … ,res8等等,表示这个res_block里含有n个res_unit,这是Yolo v3的大组件。从Yolo v2的darknet-19上升到Yolo v3的darknet-53,前者没有残差结构。Yolo v3开始借鉴了ResNet的残差结构,使用这种结构可以让网络结构更深。对于res_block的解释,可以在图1.1的右下角直观看到,其基本组件也是DBL。
在预测支路上有张量拼接(concat)操作。其实现方法是将darknet中间层和中间层后某一层的上采样进行拼接。值得注意的是,张量拼接和Res_unit结构的add的操作是不一样的,张量拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变。
从代码层面来整体分析,Yolo_body一共有252层。23个Res_unit对应23个add层。BN层和LeakyReLU层数量都是72层,在网络结构中的表现为:每一层BN后面都会接一层LeakyReLU。上采样和张量拼接操作各2个,5个零填充对应5个res_block。卷积层一共有75层,其中有72层后面都会接BatchNormalization和LeakyReLU构成的DBL。三个不同尺度的输出对应三个卷积层,最后的卷积层的卷积核个数是255,是针对COCO数据集的80类:3×(80+4+1)=255,3表示一个grid cell包含3个bounding box,4表示框的4个坐标信息,1表示置信度。
二、Darknet-53特征提取网络(Backbone)
Yolo v3中使用了一个53层的卷积网络,这个网络由残差单元叠加而成。Joseph Redmon的实验表明,在分类准确度上与效率的平衡上,Darknet-53模型比ResNet-101、 ResNet-152和Darknet-19表现得更好。Yolo v3并没有那么追求速度,而是在保证实时性(fps>60)的基础上追求performance。
一方面,Darknet-53网络采用全卷积结构,Yolo v3前向传播过程中,张量的尺寸变换是通过改变卷积核的步长来实现的。卷积的步长为2,每次经过卷积之后,图像边长缩小一半。如图2.1中所示,Darknet-53中有5次卷积的步长为2。经过5次缩小,特征图缩小为原输入尺寸的1/32。所以网络输入图片的尺寸为32的倍数,取为416×416。Yolo v2中对于前向过程中张量尺寸变换,都是通过最大池化来进行,一共有5次。而v3是通过卷积核增大步长来进行,也是5次。
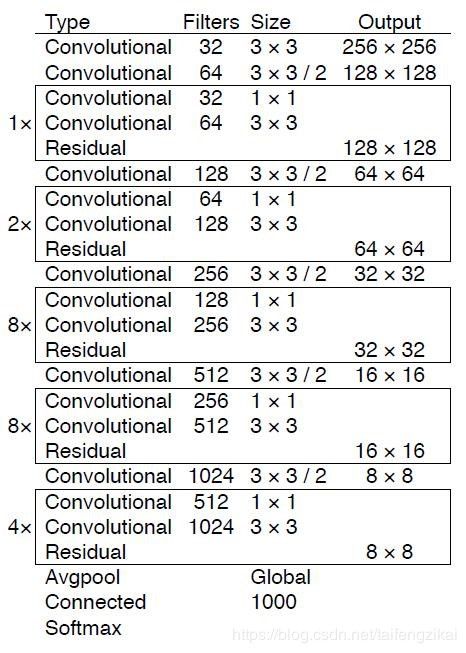
Darknet-53网络只是特征提取层,源码中只使用了pooling层前面的卷积层来提取特征,因此multi-scale的特征融合和预测支路并没有在该网络结构中体现。
三、边界框的预测(Bounding Box Prediction)
Yolo v3关于bounding box的初始尺寸还是采用Yolo v2 v2中的k-means聚类的方式来做,这种先验知识对于bounding box的初始化帮助还是很大的,毕竟过多的bounding box虽然对于效果来说有保障,但是对于算法速度影响还是比较大的。
Yolo v2借鉴了faster R-CNN的RPN的anchor机制,不同的是,采用k-means聚类的方法来确定默认框的尺寸。Joseph Redmon修改了k-means算法中关于距离的定义,使用的是IOU距离。同样地,YOLO v3选择的默认框有9个。其尺寸可以通过k-means算法在数据集上聚类得到。在COCO数据集上,9个聚类是:(10×13);(16×30);(33×23);(30×61);(62×45); (59×119); (116×90); (156×198); (373×326)。默认框与不同尺寸特征图的对应关系是:13×13的feature map对应[(116×90),(156×198),(373×326)],26×26的feature map对应[(30×61),(62×45),(59×119)],52×52的feature map对应[(10×13),(16×30),(33×23)]。其原因是:特征图越大,感受野越小。对小目标越敏感,所以选用小的anchor box。特征图越小,感受野越大。对大目标越敏感,所以选用大的anchor box。
import numpy as np
class YOLO_Kmeans:
def __init__(self, cluster_number, filename):
self.cluster_number = cluster_number
self.filename = "2012_train.txt"
def iou(self, boxes, clusters): # 1 box -> k clusters
n = boxes.shape[0]
k = self.cluster_number
box_area = boxes[:, 0] * boxes[:, 1]
box_area = box_area.repeat(k)
box_area = np.reshape(box_area, (n, k))
cluster_area = clusters[:, 0] * clusters[:, 1]
cluster_area = np.tile(cluster_area, [1, n])
cluster_area = np.reshape(cluster_area, (n, k))
box_w_matrix = np.reshape(boxes[:, 0].repeat(k), (n, k))
cluster_w_matrix = np.reshape(np.tile(clusters[:, 0], (1, n)), (n, k))
min_w_matrix = np.minimum(cluster_w_matrix, box_w_matrix)
box_h_matrix = np.reshape(boxes[:, 1].repeat(k), (n, k))
cluster_h_matrix = np.reshape(np.tile(clusters[:, 1], (1, n)), (n, k))
min_h_matrix = np.minimum(cluster_h_matrix, box_h_matrix)
inter_area = np.multiply(min_w_matrix, min_h_matrix)
# 计算IOU值
result = inter_area / (box_area + cluster_area - inter_area)
return result
def avg_iou(self, boxes, clusters):
accuracy = np.mean([np.max(self.iou(boxes, clusters), axis=1)])
return accuracy
def kmeans(self, boxes, k, dist=np.median):
#聚类问题
box_number = boxes.shape[0]
distances = np.empty((box_number, k))
last_nearest = np.zeros((box_number,))
np.random.seed()
clusters = boxes[np.random.choice(
box_number, k, replace=False)] # init k clusters
while True:
#此处没有使用欧氏距离,较大的box会比较小的box产生更多的错误。自定义的距离度量公式为:
#d(box,centroid)=1-IOU(box,centroid)。到聚类中心的距离越小越好,但IOU值是越大越好,所以使用 #1 - IOU,这样就保证距离越小,IOU值越大。
distances = 1 - self.iou(boxes, clusters)
current_nearest = np.argmin(distances, axis=1)
if (last_nearest == current_nearest).all():
break # clusters won't change
for cluster in range(k):
clusters[cluster] = dist( # update clusters
boxes[current_nearest == cluster], axis=0)
last_nearest = current_nearest
return clusters
def result2txt(self, data):
f = open("yolo_anchors.txt", 'w')
row = np.shape(data)[0]
for i in range(row):
if i == 0:
x_y = "%d,%d" % (data[i][0], data[i][1])
else:
x_y = ", %d,%d" % (data[i][0], data[i][1])
f.write(x_y)
f.close()
def txt2boxes(self):
f = open(self.filename, 'r')
dataSet = []
for line in f:
infos = line.split(" ")
length = len(infos)
for i in range(1, length):
width = int(infos[i].split(",")[2]) - \
int(infos[i].split(",")[0])
height = int(infos[i].split(",")[3]) - \
int(infos[i].split(",")[1])
dataSet.append([width, height])
result = np.array(dataSet)
f.close()
return result
def txt2clusters(self):
all_boxes = self.txt2boxes()
result = self.kmeans(all_boxes, k=self.cluster_number)
result = result[np.lexsort(result.T[0, None])]
self.result2txt(result)
print("K anchors:\n {}".format(result))
print("Accuracy: {:.2f}%".format(
self.avg_iou(all_boxes, result) * 100))
if __name__ == "__main__":
cluster_number = 9
filename = "2012_train.txt"
kmeans = YOLO_Kmeans(cluster_number, filename)
kmeans.txt2clusters()
Yolo v3采用直接预测相对位置的方法。预测出b-box中心点相对于网格单元左上角的相对坐标。直接预测出(tx,ty,tw,th,t0),然后通过以下坐标偏移公式计算得到b-box的位置大小和confidence。
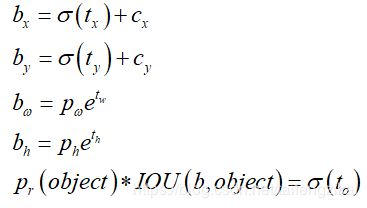
tx、ty、tw、th就是模型的预测输出。cx和cy表示grid cell的坐标,比如某层的feature map大小是13×13,那么grid cell就有13×13个,第0行第1列的grid cell的坐标cx就是0,cy就是1。pw和ph表示预测前bounding box的size。bx、by、bw和bh就是预测得到的bounding box的中心的坐标和size。在训练这几个坐标值的时候采用了sum of squared error loss(平方和距离误差损失),因为这种方式的误差可以很快的计算出来。
Yolo v3使用逻辑回归预测每个边界框的分数。如果边界框与真实框的重叠度比之前的任何其他边界框都要好,则该值应该为1。如果边界框不是最好的,但确实与真实对象的重叠超过某个阈值(Yolo v3中这里设定的阈值是0.5),那么就忽略这次预测。Yolo v3只为每个真实对象分配一个边界框,如果边界框与真实对象不吻合,则不会产生坐标或类别预测损失,只会产生物体预测损失。
四、类别预测
类别预测方面主要是将原来的单标签分类改进为多标签分类,因此网络结构上就将原来用于单标签多分类的softmax层换成用于多标签多分类的Logistic分类器。Yolo v2网络中的Softmax分类器,认为一个目标只属于一个类别,通过输出Score大小,使得每个框分配到Score最大的一个类别。但在一些复杂场景下,一个目标可能属于多个类(有重叠的类别标签),因此Yolo v3用多个独立的Logistic分类器替代Softmax层解决多标签分类问题,且准确率不会下降。举例说明,原来分类网络中的softmax层都是假设一张图像或一个object只属于一个类别,但是在一些复杂场景下,一个object可能属于多个类,比如你的类别中有woman和person这两个类,那么如果一张图像中有一个woman,那么你检测的结果中类别标签就要同时有woman和person两个类,这就是多标签分类,需要用Logistic分类器来对每个类别做二分类。Logistic分类器主要用到sigmoid函数,该函数可以将输入约束在0到1的范围内,因此当一张图像经过特征提取后的某一类输出经过sigmoid函数约束后如果大于0.5,就表示该边界框负责的目标属于该类。
五、多尺度预测
Yolo v3采用多个scale融合的方式做预测。原来的Yolo v2有一个层叫:passthrough layer,该层作用是为了加强Yolo算法对小目标检测的精确度。这个思想在Yolo v3中得到了进一步加强,在Yolo v3中采用类似FPN(feature pyramid networks)的upsample和融合做法(最后融合了3个scale,其他两个scale的大小分别是26×26和52×52),在多个scale的feature map上做检测,越精细的grid cell就可以检测出越精细的物体。对于小目标的检测效果提升明显。
在结构图1.1中可以看出,Yolo v3设定的是每个网格单元预测3个box,所以每个box需要有(x, y, w, h, confidence)五个基本参数。Yolo v3输出了3个不同尺度的feature map,如图1.1所示的y1, y2, y3。y1,y2和y3的深度都是255,边长的规律是13:26:52。
每个预测任务得到的特征大小都为N ×N ×[3∗(4+1+80)] ,N为格子大小,3为每个格子得到的边界框数量, 4是边界框坐标数量,1是目标预测值,80是类别数量。对于COCO类别而言,有80个类别的概率,所以每个box应该对每个种类都输出一个概率。所以3×(5 + 80) = 255。这个255就是这么来的。
Yolo v3用上采样的方法来实现这种多尺度的feature map。在Darknet-53得到的特征图的基础上,经过六个DBL结构和最后一层卷积层得到第一个特征图谱,在这个特征图谱上做第一次预测。Y1支路上,从后向前的倒数第3个卷积层的输出,经过一个DBL结构和一次(2,2)上采样,将上采样特征与第2个Res8结构输出的卷积特征张量连接,经过六个DBL结构和最后一层卷积层得到第二个特征图谱,在这个特征图谱上做第二次预测。Y2支路上,从后向前倒数第3个卷积层的输出,经过一个DBL结构和一次(2,2)上采样,将上采样特征与第1个Res8结构输出的卷积特征张量连接,经过六个DBL结构和最后一层卷积层得到第三个特征图谱,在这个特征图谱上做第三次预测。
就整个网络而言,Yolo v3多尺度预测输出的feature map尺寸为y1:(13×13),y2:(26×26),y3:(52×52)。网络接收一张(416×416)的图,经过5个步长为2的卷积来进行降采样(416 / 2ˆ5 = 13,y1输出(13×13)。从y1的倒数第二层的卷积层上采样(x2,up sampling)再与最后一个26×26大小的特征图张量连接,y2输出(26×26)。从y2的倒数第二层的卷积层上采样(x2,up sampling)再与最后一个52×52大小的特征图张量连接,y3输出(52×52)
六、Loss Function
对掌握Yolo来讲,loss function不可谓不重要。在Yolo v3的论文里没有明确提出所用的损失函数,确切地说,Yolo系列论文里面只有Yolo v1明确提了损失函数的公式。在Yolo v1中使用了一种叫sum-square error的损失计算方法,只是简单的差方相加。我们知道,在目标检测任务里,有几个关键信息是需要确定的:(x,y),(w,h),class,confidence 。根据关键信息的特点可以分为上述四类,损失函数应该由各自特点确定。最后加到一起就可以组成最终的loss function了,也就是一个loss function搞定端到端的训练。

xy_loss = object_mask * box_loss_scale * K.binary_crossentropy(raw_true_xy, raw_pred[...,0:2], from_logits=True)
wh_loss = object_mask * box_loss_scale * 0.5 * K.square(raw_true_wh-raw_pred[...,2:4])
# 置信度
confidence_loss = object_mask * K.binary_crossentropy(object_mask, raw_pred[...,4:5], from_logits=True)+ (1-object_mask) * K.binary_crossentropy(object_mask, raw_pred[...,4:5], from_logits=True) * ignore_mask
# 分类
class_loss = object_mask * K.binary_crossentropy(true_class_probs, raw_pred[...,5:], from_logits=True)
xy_loss = K.sum(xy_loss) / mf
wh_loss = K.sum(wh_loss) / mf
confidence_loss = K.sum(confidence_loss) / mf
class_loss = K.sum(class_loss) / mf
loss += xy_loss + wh_loss + confidence_loss + class_loss
七、实验
本文使用了qwe的keras版本的yolo v3代码,代码相对来说比较容易理解,复现比较容易。目录结构如图7.1所示
| Python3.6 | Cuda 9.0 | CuDnn 7.0.3 |
|---|---|---|
| Opencv 4.0.0 | Tensorflow-gpu 1.8.0 | Keras 2.2.4 |
整个仿真过程流程如图7.2:

7.1使用官方模型进行检测
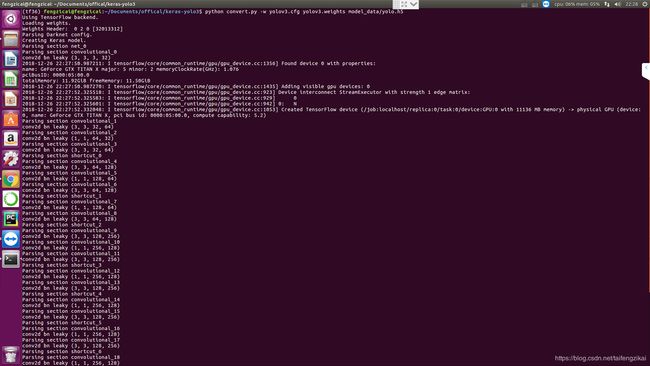
Yolo v3的作者训练的网络基于coco数据集。下载作者的权值文件,yolov3.weights。经convert.py转换为keras的网络结构和权值文件。执行以下命令,完成模型的转换。
python convert.py -w yolov3.cfg yolov3.weights model_data/yolo.h5
转换过程如图7.3。需要注意的是然后使用yolo_video.py检测图像或视频中的目标。yolov3.cfg是模型控制文件,yolov3.weights是模型权重文件,model_data/yolo.h5是输出的keras权重文件。
[net]
# Testing ### 测试模式
batch=1
subdivisions=1
# Training ### 训练模式,每次前向的图片数目 = batch/subdivisions
# batch=64
# subdivisions=16
width=416 ### 网络的输入宽、高、通道数
height=416
channels=3
momentum=0.9 ### 动量
decay=0.0005 ### 权重衰减
angle=0
saturation = 1.5 ### 饱和度
exposure = 1.5 ### 曝光度
hue=.1 ### 色调
learning_rate=0.001 ### 学习率
burn_in=1000 ### 学习率控制的参数
max_batches = 50200 ### 迭代次数
policy=steps ### 学习率策略
steps=40000,45000 ### 学习率变动步长
scales=.1,.1 ### 学习率变动因子
[convolutional]
batch_normalize=1 ### BN
filters=32 ### 卷积核数目
size=3 ### 卷积核尺寸
stride=1 ### 卷积核步长
pad=1 ### pad
activation=leaky ### 激活函数
……
[convolutional]
size=1
stride=1
pad=1
filters=255 ### 3x(classes + 4coor + 1prob) = 3x(20+4+1) = 75
activation=linear
[yolo]
mask = 0,1,2 ### mask序号
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=80 ### 类比数目
num=9
jitter=.3 ### 数据扩充的抖动操作
ignore_thresh = .5 ### 文章中的阈值1
truth_thresh = 1 ### 文章中的阈值2
random=1 ### 多尺度训练开关
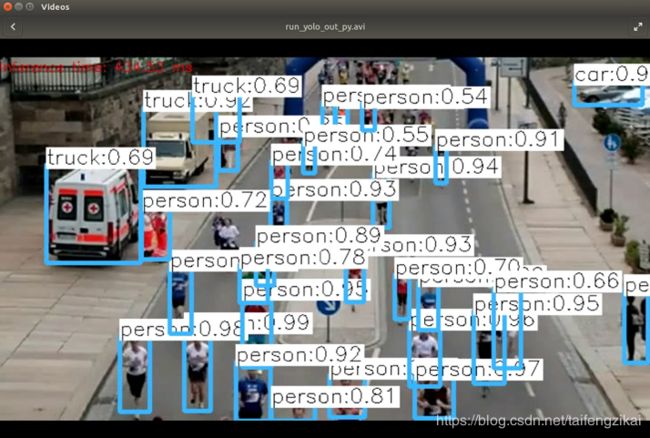
检测使用的脚本的分析放在使用自己的数据集训练并检测的部分。这里先给出使用官方权重文件的检测结果。使用python yolo_video.py –image命令,输入类别为狗,鸟,人的图片各一张,得到图片的检测结果,图7.4:

python yolo_video.py [video_path] [output_path (optional)]

import os
import random
trainval_percent = 0.1 #验证集比例
train_percent = 0.9 #训练集比例
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name) #10%的图片用作训练-验证集
if i in train:
ftest.write(name) #训练-验证集的90%用作测试集
else:
fval.write(name) #训练-验证集的10%用作验证集
else:
ftrain.write(name) #90%的图片作为训练集
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
最后将划分好的图片名称分别保存到’ImageSets\Main’目录下,trainval.txt,test.txt,train.txt和val.txt四个文件中。
该工程中使用的数据格式是: image_file_path box1 box2 … boxN; 边界框格式是: x_min,y_min,x_max,y_max,class_id (no space)。对于VOC数据集,需要使用voc_annotation.py脚本进行转换。在主目录下生成test.txt,train.txt和val.txt,包含上一步生成的训练集、验证集和测试集的图片的路径和(x,y,w,h,class)真实值信息。
import xml.etree.ElementTree as ET
from os import getcwd
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["people","front","side","back"] #数据集中所标记的四个类别
def convert_annotation(year, image_id, list_file):
in_file =open('/home/fengzicai/Documents/keras-yolo3/VOC%s/Annotations/%s.xml'%(year, image_id))
tree=ET.parse(in_file)
root = tree.getroot()
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (int(xmlbox.find('xmin').text), int(xmlbox.find('ymin').text), int(xmlbox.find('xmax').text), int(xmlbox.find('ymax').text))
list_file.write(" " + ",".join([str(a) for a in b]) + ',' + str(cls_id))
wd = getcwd()
for year, image_set in sets:
image_ids = open('/home/fengzicai/Documents/keras-yolo3/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOC%s/JPEGImages/%s.jpg'%(wd, year, image_id))
convert_annotation(year, image_id, list_file)
list_file.write('\n')
list_file.close()
至此,VOC格式的数据集就准备好了。然后将四类标签名写入model_data/coco_classes.txt和model/voc_classes.txt中。model_data/ yolo_anchors.txt填写通过K聚类得到的9个anchor。
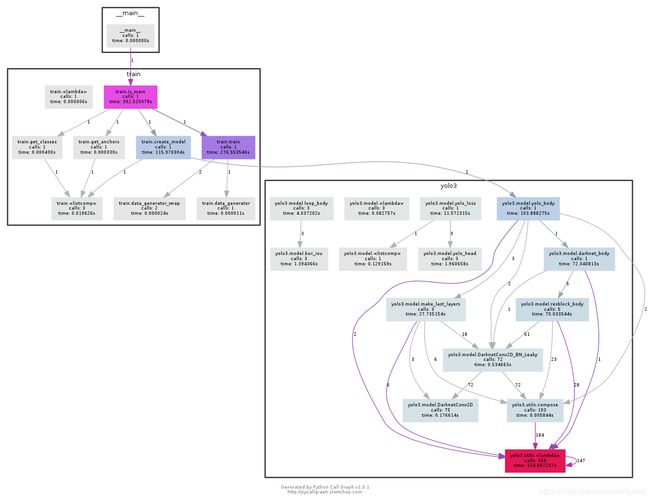
下一步开始准备训练。训练过程函数调用关系如图7.7。
"""
Retrain the YOLO model for your own dataset.
"""
import numpy as np
import keras.backend as K
from keras.layers import Input, Lambda
from keras.models import Model
from keras.callbacks import TensorBoard, ModelCheckpoint, EarlyStopping
from yolo3.model import preprocess_true_boxes, yolo_body, tiny_yolo_body, yolo_loss
from yolo3.utils import get_random_data
def _main():
annotation_path = 'train.txt'
log_dir = 'logs/000/' #保存权重文件的路径
classes_path = 'model_data/voc_classes.txt' #保存分类信息文件的路径
anchors_path = 'model_data/yolo_anchors.txt' #保存默认框信息的路径
class_names = get_classes(classes_path)
anchors = get_anchors(anchors_path)
input_shape = (416,416) # multiple of 32, hw
model = create_model(input_shape, anchors, len(class_names) )
train(model, annotation_path, input_shape, anchors, len(class_names), log_dir=log_dir)
def train(model, annotation_path, input_shape, anchors, num_classes, log_dir='logs/'):
model.compile(optimizer='adam', loss={
'yolo_loss': lambda y_true, y_pred: y_pred})
logging = TensorBoard(log_dir=log_dir)
checkpoint = ModelCheckpoint(log_dir + "ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5",
monitor='val_loss', save_weights_only=True, save_best_only=True, period=1)
batch_size = 10
val_split = 0.1
with open(annotation_path) as f:
lines = f.readlines()
np.random.shuffle(lines)
num_val = int(len(lines)*val_split)
num_train = len(lines) - num_val
print('Train on {} samples, val on {} samples, with batch size {}.'.format(num_train, num_val, batch_size))
model.fit_generator(data_generator_wrap(lines[:num_train], batch_size, input_shape, anchors, num_classes),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=data_generator_wrap(lines[num_train:], batch_size, input_shape, anchors, num_classes),
validation_steps=max(1, num_val//batch_size),
epochs=500,
initial_epoch=0)
model.save_weights(log_dir + 'trained_weights.h5')
def get_classes(classes_path):
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
def get_anchors(anchors_path):
with open(anchors_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(',')]
return np.array(anchors).reshape(-1, 2)
#该函数用于创建模型
def create_model(input_shape, anchors, num_classes, load_pretrained=False, freeze_body=False,
weights_path='model_data/yolo_weights.h5'):
K.clear_session() # get a new session
image_input = Input(shape=(None, None, 3))
h, w = input_shape
num_anchors = len(anchors)
y_true = [Input(shape=(h//{0:32, 1:16, 2:8}[l], w//{0:32, 1:16, 2:8}[l], \
num_anchors//3, num_classes+5)) for l in range(3)]
#预测每个尺度的3个框,所以对于4个边界框偏移量,1个目标性预测和4个类别预测,张量为#N×N×[3 *(4 + 1 + 4)],默认参数下:y_true[l]的shape为(batch,H,W,3,num_classes+5)
model_body = yolo_body(image_input, num_anchors//3, num_classes)
# yolo_body()函数从yolo3.model中引入
print('Create YOLOv3 model with {} anchors and {} classes.'.format(num_anchors, num_classes))
if load_pretrained:
model_body.load_weights(weights_path, by_name=True, skip_mismatch=True)
print('Load weights {}.'.format(weights_path))
if freeze_body:
# Do not freeze 3 output layers.
num = len(model_body.layers)-7
for i in range(num): model_body.layers[i].trainable = False
print('Freeze the first {} layers of total {} layers.'.format(num, len(model_body.layers)))
#生成模型损失
model_loss = Lambda(yolo_loss, output_shape=(1,), name='yolo_loss',
arguments={'anchors': anchors, 'num_classes': num_classes, 'ignore_thresh': 0.5})(
[*model_body.output, *y_true])
model = Model([model_body.input, *y_true], model_loss)
return model
#通过train.py(data_generator)生成数据
def data_generator(annotation_lines, batch_size, input_shape, anchors, num_classes):
n = len(annotation_lines)
np.random.shuffle(annotation_lines)
i = 0
while True:
image_data = []
box_data = []
for b in range(batch_size):
i %= n
image, box = get_random_data(annotation_lines[i], input_shape, random=True)
image_data.append(image)
box_data.append(box)
i += 1
image_data = np.array(image_data)
box_data = np.array(box_data)
y_true = preprocess_true_boxes(box_data, input_shape, anchors, num_classes)
yield [image_data, *y_true], np.zeros(batch_size)
def data_generator_wrap(annotation_lines, batch_size, input_shape, anchors, num_classes):
n = len(annotation_lines)
if n==0 or batch_size<=0: return None
return data_generator(annotation_lines, batch_size, input_shape, anchors, num_classes)
if __name__ == '__main__':
_main()
使用自己的数据集进行检测过程与使用官方权重文件进行检测过程相同。使用python yolo_img.py –image执行检测脚本。检测脚本yolo_img.py:
import sys
import argparse
from yolo import YOLO, detect_video
from PIL import Image
import os
import glob
def detect_img(yolo):
path = "/home/fengzicai/Documents/keras-yolo3/VOC2007/JPEGImages/*.jpg" #要读入的图片路径
outdir = "/home/fengzicai/Documents/keras-yolo3/VOC2007/SegmentationClass" #将检测的结果全保#存到outdir路径
for jpgfile in glob.glob(path):
img = Image.open(jpgfile)
img = yolo.detect_image(img) #调用yolo类中的detect_image函数,对图片进行检测,见#yolo脚本
img.save(os.path.join(outdir, os.path.basename(jpgfile)))
yolo.close_session()
FLAGS = None
if __name__ == '__main__':
# class YOLO defines the default value, so suppress any default here
parser = argparse.ArgumentParser(argument_default=argparse.SUPPRESS)
'''
Command line options
'''
parser.add_argument(
'--model', type=str,
help='path to model weight file, default ' + YOLO.get_defaults("model_path")
)
parser.add_argument(
'--anchors', type=str,
help='path to anchor definitions, default ' + YOLO.get_defaults("anchors_path")
)
parser.add_argument(
'--classes', type=str,
help='path to class definitions, default ' + YOLO.get_defaults("classes_path")
)
parser.add_argument(
'--gpu_num', type=int,
help='Number of GPU to use, default ' + str(YOLO.get_defaults("gpu_num"))
)
parser.add_argument(
'--image', default=False, action="store_true",
help='Image detection mode, will ignore all positional arguments'
)
'''
Command line positional arguments -- for video detection mode
'''
parser.add_argument(
"--input", nargs='?', type=str,required=False,default='./path2your_video',
help = "Video input path"
)
parser.add_argument(
"--output", nargs='?', type=str, default="",
help = "[Optional] Video output path"
)
FLAGS = parser.parse_args()
if FLAGS.image:
"""
Image detection mode, disregard any remaining command line arguments
"""
print("Image detection mode")
if "input" in FLAGS:
print(" Ignoring remaining command line arguments: " + FLAGS.input + "," + FLAGS.output)
detect_img(YOLO(**vars(FLAGS)))
elif "input" in FLAGS:
detect_video(YOLO(**vars(FLAGS)), FLAGS.input, FLAGS.output)
else:
print("Must specify at least video_input_path. See usage with --help.")
Yolo_img.py在执行时,导入了yolo.py脚本,包含图像和视频中YOLO v3模型检测的类定义。
"""
Class definition of YOLO_v3 style detection model on image and video
"""
import colorsys
import os
from timeit import default_timer as timer
import numpy as np
from keras import backend as K
from keras.models import load_model
from keras.layers import Input
from PIL import Image, ImageFont, ImageDraw
from yolo3.model import yolo_eval, yolo_body, tiny_yolo_body
from yolo3.utils import letterbox_image
import os
from keras.utils import multi_gpu_model
#YOLO类的初始化参数
class YOLO(object):
_defaults = {
#"model_path": 'model_data/yolo.h5',
"model_path": 'logs/001/trained_weights.h5', #训练好的模型
"anchors_path": 'model_data/yolo_anchors.txt', #有9个anchor box,从小到大排列
"classes_path": 'model_data/coco_classes.txt', #类别数目
"score" : 0.3, #score阈值
"iou" : 0.45, #iou 阈值
"model_image_size" : (416, 416), #输入图像尺寸
"gpu_num" : 1, #gpu数量
}
@classmethod
def get_defaults(cls, n):
if n in cls._defaults:
return cls._defaults[n]
else:
return "Unrecognized attribute name '" + n + "'"
def __init__(self, **kwargs):
self.__dict__.update(self._defaults) # set up default values
self.__dict__.update(kwargs) # and update with user overrides
self.class_names = self._get_class()
self.anchors = self._get_anchors()
self.sess = K.get_session()
self.boxes, self.scores, self.classes = self.generate()
def _get_class(self):
classes_path = os.path.expanduser(self.classes_path)
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
def _get_anchors(self):
anchors_path = os.path.expanduser(self.anchors_path)
with open(anchors_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(',')]
return np.array(anchors).reshape(-1, 2)
def generate(self): #yolo_img.py中调用了该函数
model_path = os.path.expanduser(self.model_path) #获取model路径
assert model_path.endswith('.h5'), 'Keras model or weights must be a .h5 file.'
#判断model是否以h5结尾
# Load model, or construct model and load weights.
num_anchors = len(self.anchors) #num_anchors = 9。yolov3有9个先验框
num_classes = len(self.class_names) #num_cliasses = 4。一共有四个类别
is_tiny_version = num_anchors==6 # default setting
try:
self.yolo_model = load_model(model_path, compile=False) #下载model
except:
self.yolo_model=tiny_yolo_body(Input(shape=(None,None,3)), num_anchors//2,
num_classes) \
if is_tiny_version else yolo_body(Input(shape=(None,None,3)), num_anchors//3, num_classes)
self.yolo_model.load_weights(self.model_path) # 确保model和anchor classes 对应
else:
assert self.yolo_model.layers[-1].output_shape[-1] == \
# model.layer[-1]:网络最后一层输出。 output_shape[-1]:输出维度的最后一维。 -> (?,13,13,27)
num_anchors/len(self.yolo_model.output) * (num_classes + 5), \
#27 = 9/3*(4+5). 9/3:每层网格对应3个anchor box 4:4个类别 5:4+1,框的4个值+1个置信度
'Mismatch between model and given anchor and class sizes'
print('{} model, anchors, and classes loaded.'.format(model_path))
# 生成绘制边框的颜色
hsv_tuples = [(x / len(self.class_names), 1., 1.)
#h(色调):x/len(self.class_names) s(饱和度):1.0 v(明亮):1.0
for x in range(len(self.class_names))]
self.colors = list(map(lambda x: colorsys.hsv_to_rgb(*x), hsv_tuples)) #hsv转换为rgb
self.colors = list(
map(lambda x: (int(x[0] * 255), int(x[1] * 255), int(x[2] * 255)),
self.colors))
#hsv取值范围在[0,1],而RBG取值范围在[0,255],所以乘上255
np.random.seed(10101) # np.random.seed():产生随机种子。固定种子为一致的颜色
np.random.shuffle(self.colors) # 调整颜色来装饰相邻的类。
np.random.seed(None) # 重置种子为默认
#为过滤的边界框生成输出张量目标。
self.input_image_shape = K.placeholder(shape=(2, )) #K.placeholder:keras中的占位符
if self.gpu_num>=2:
self.yolo_model = multi_gpu_model(self.yolo_model, gpus=self.gpu_num)
boxes, scores, classes = yolo_eval(self.yolo_model.output, self.anchors,
len(self.class_names), self.input_image_shape,
score_threshold=self.score, iou_threshold=self.iou) #yolo_eval():yolo评估函数
return boxes, scores, classes
def detect_image(self, image): # yolo_img.py中调用了该函数
start = timer()
if self.model_image_size != (None, None): #判断图片是否存在
assert self.model_image_size[0]%32 == 0, 'Multiples of 32 required'
assert self.model_image_size[1]%32 == 0, 'Multiples of 32 required'
#assert断言语句的语法格式 model_image_size[0][1]指图像的w和h,且必须是32的整数倍
boxed_image = letterbox_image(image, tuple(reversed(self.model_image_size)))
# letterbox_image()定义见附录中的yolo3.utils。输入参数(图像 ,(w=416,h=416)),
#输出一张使用填充来调整图像的纵横比不变的新图。
else:
new_image_size = (image.width - (image.width % 32),
image.height - (image.height % 32))
boxed_image = letterbox_image(image, new_image_size)
image_data = np.array(boxed_image, dtype='float32')
print(image_data.shape) #(416,416,3)
image_data /= 255. #归一化
image_data = np.expand_dims(image_data, 0) # Add batch dimension.
#添加批量维度为 (1,416,416,3),使输入网络的张量满足(bitch, w, h, c)的格式
out_boxes, out_scores, out_classes = self.sess.run(
[self.boxes, self.scores, self.classes],
#目的为了求boxes,scores,classes,具体计算方式定义在generate()函数内。在yolo.py中
feed_dict={
self.yolo_model.input: image_data, #图像数据
self.input_image_shape: [image.size[1], image.size[0]], #图像尺寸
K.learning_phase(): 0 #学习模式 0:测试模型。1:训练模式
})
print('Found {} boxes for {}'.format(len(out_boxes), 'img'))
#绘制边框,自动设置边框宽度,绘制边框和类别文字,使用pillow绘图库。
font = ImageFont.truetype(font='font/FiraMono-Medium.otf',
size=np.floor(3e-2 * image.size[1] + 0.5).astype('int32')) #设置字体
thickness = (image.size[0] + image.size[1]) // 300 #设置厚度
for i, c in reversed(list(enumerate(out_classes))):
predicted_class = self.class_names[c] #类别
box = out_boxes[i] #框
score = out_scores[i] #置信度
label = '{} {:.2f}'.format(predicted_class, score) #标签
draw = ImageDraw.Draw(image) #画图
label_size = draw.textsize(label, font) #标签文字
top, left, bottom, right = box
top = max(0, np.floor(top + 0.5).astype('int32'))
left = max(0, np.floor(left + 0.5).astype('int32'))
bottom = min(image.size[1], np.floor(bottom + 0.5).astype('int32'))
right = min(image.size[0], np.floor(right + 0.5).astype('int32'))
print(label, (left, top), (right, bottom)) #边框
if top - label_size[1] >= 0: #标签文字
text_origin = np.array([left, top - label_size[1]])
else:
text_origin = np.array([left, top + 1])
# My kingdom for a good redistributable image drawing library.
for i in range(thickness): #画边框
draw.rectangle(
[left + i, top + i, right - i, bottom - i],
outline=self.colors[c])
draw.rectangle( #文字背景
[tuple(text_origin), tuple(text_origin + label_size)],
fill=self.colors[c])
draw.text(text_origin, label, fill=(0, 0, 0), font=font)
del draw
end = timer()
print(end - start)
return image
def close_session(self):
self.sess.close()
def detect_video(yolo, video_path, output_path=""):
import cv2
vid = cv2.VideoCapture(video_path)
if not vid.isOpened():
raise IOError("Couldn't open webcam or video")
video_FourCC = int(vid.get(cv2.CAP_PROP_FOURCC))
video_fps = vid.get(cv2.CAP_PROP_FPS)
video_size = (int(vid.get(cv2.CAP_PROP_FRAME_WIDTH)),
int(vid.get(cv2.CAP_PROP_FRAME_HEIGHT)))
isOutput = True if output_path != "" else False
if isOutput:
print("!!! TYPE:", type(output_path), type(video_FourCC), type(video_fps), type(video_size))
out = cv2.VideoWriter(output_path, video_FourCC, video_fps, video_size)
accum_time = 0
curr_fps = 0
fps = "FPS: ??"
prev_time = timer()
while True:
return_value, frame = vid.read()
#frame_array = np.asarray(frame)
image = Image.fromarray(frame)
image = yolo.detect_image(image)
result = np.asarray(image)
curr_time = timer()
exec_time = curr_time - prev_time
prev_time = curr_time
accum_time = accum_time + exec_time
curr_fps = curr_fps + 1
if accum_time > 1:
accum_time = accum_time - 1
fps = "FPS: " + str(curr_fps)
curr_fps = 0
cv2.putText(result, text=fps, org=(3, 15), fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=0.50, color=(255, 0, 0), thickness=2)
cv2.namedWindow("result", cv2.WINDOW_NORMAL)
cv2.imshow("result", result)
if isOutput:
out.write(result)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
yolo.close_session()
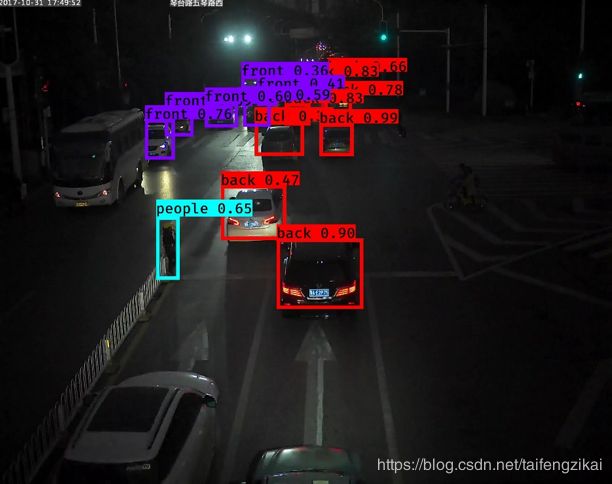
检测图片时,命令行的执行过程如图7.8。函数的调用的关系如图7.9。图片检测结果如图7.10。
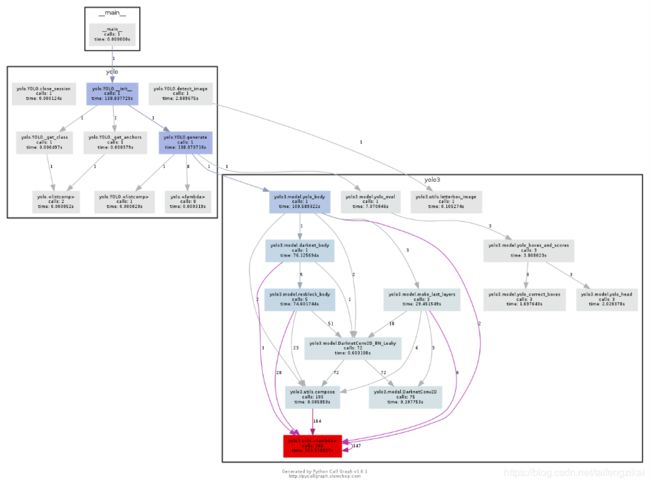
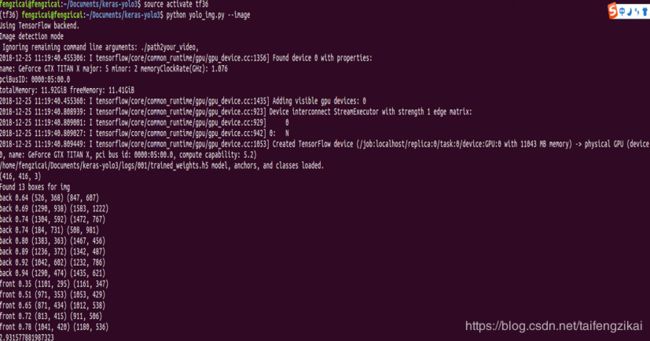
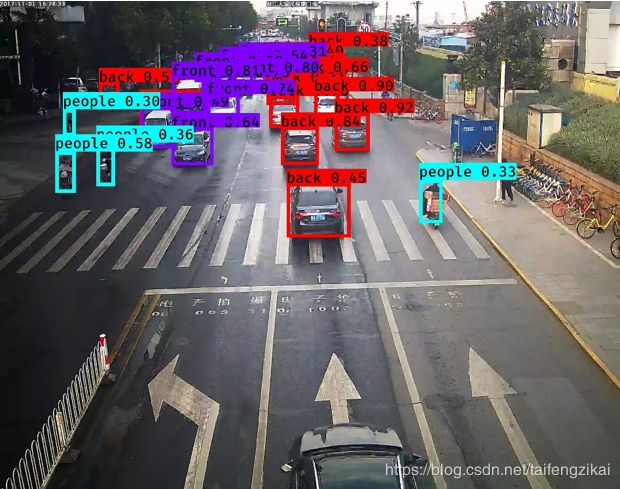

图7.10(2) 图片检测结果
[1] https://www.jianshu.com/p/3943be47fe84
[2] https://blog.csdn.net/leviopku/article/details/82660381
[3] https://github.com/qqwweee/keras-yolo3
[4] https://blog.csdn.net/Patrick_Lxc/article/details/80615433
[5] https://blog.csdn.net/lilai619/article/details/79695109
[6] https://blog.csdn.net/sum_nap/article/details/80568873#comments
[7] https://blog.csdn.net/u014380165/article/details/80202337
[8] https://blog.csdn.net/KKKSQJ/article/details/83587138
[9] https://blog.csdn.net/yangchengtest/article/details/80664415
[10] https://blog.csdn.net/Gentleman_Qin/article/details/84350496
附录A
训练和检测都导入了yolo3.model:
"""YOLO_v3 Model Defined in Keras."""
from functools import wraps
import numpy as np
import tensorflow as tf
from keras import backend as K
from keras.layers import Conv2D, Add, ZeroPadding2D, UpSampling2D, Concatenate, MaxPooling2D
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.normalization import BatchNormalization
from keras.models import Model
from keras.regularizers import l2
from yolo3.utils import compose
# DarknetConv2D(),DarknetConv2D_BN_Leaky(),resblock_body()三个函数构成了darknet_body()卷积层框#架
@wraps(Conv2D)
def DarknetConv2D(*args, **kwargs):
"""Wrapper to set Darknet parameters for Convolution2D."""
darknet_conv_kwargs = {'kernel_regularizer': l2(5e-4)}
darknet_conv_kwargs['padding'] = 'valid' if kwargs.get('strides')==(2,2) else 'same'
darknet_conv_kwargs.update(kwargs)
return Conv2D(*args, **darknet_conv_kwargs)
#注意 DARKNET卷积这里激活函数是LEAKYRELU
def DarknetConv2D_BN_Leaky(*args, **kwargs):
"""Darknet Convolution2D followed by BatchNormalization and LeakyReLU."""
no_bias_kwargs = {'use_bias': False}
no_bias_kwargs.update(kwargs)
return compose(
DarknetConv2D(*args, **no_bias_kwargs),
BatchNormalization(),
LeakyReLU(alpha=0.1))
def resblock_body(x, num_filters, num_blocks):
'''A series of resblocks starting with a downsampling Convolution2D'''
# Darknet uses left and top padding instead of 'same' mode
# Darknet使用向左和向上填充代替same模式。
#DARKNET每块之间,使用了,(1,0,1,0)的PADDING层。
x = ZeroPadding2D(((1,0),(1,0)))(x)
x = DarknetConv2D_BN_Leaky(num_filters, (3,3), strides=(2,2))(x)
for i in range(num_blocks):
y = compose(
DarknetConv2D_BN_Leaky(num_filters//2, (1,1)),
DarknetConv2D_BN_Leaky(num_filters, (3,3)))(x)
x = Add()([x,y])
return x
#创建darknet网络结构,有52层卷积层。包含五个resblock
def darknet_body(x):
'''Darknent body having 52 Convolution2D layers'''
x = DarknetConv2D_BN_Leaky(32, (3,3))(x)
x = resblock_body(x, 64, 1)
x = resblock_body(x, 128, 2)
x = resblock_body(x, 256, 8)
x = resblock_body(x, 512, 8)
x = resblock_body(x, 1024, 4)
return x
#Convs由make_last_layers函数来实现。
def make_last_layers(x, num_filters, out_filters):
'''6 Conv2D_BN_Leaky layers followed by a Conv2D_linear layer'''
x = compose(
DarknetConv2D_BN_Leaky(num_filters, (1,1)),
DarknetConv2D_BN_Leaky(num_filters*2, (3,3)),
DarknetConv2D_BN_Leaky(num_filters, (1,1)),
DarknetConv2D_BN_Leaky(num_filters*2, (3,3)),
DarknetConv2D_BN_Leaky(num_filters, (1,1)))(x)
y = compose(
DarknetConv2D_BN_Leaky(num_filters*2, (3,3)),
DarknetConv2D(out_filters, (1,1)))(x)
return x, y
def yolo_body(inputs, num_anchors, num_classes):
"""Create YOLO_V3 model CNN body in Keras."""
darknet = Model(inputs, darknet_body(inputs)) # darknet_body(inputs)创建一个darknet网络
#以下语句是特征金字塔(FPN)的具体实现。
x, y1 = make_last_layers(darknet.output, 512, num_anchors*(num_classes+5))
#compose函数,从左向右评估函数
x = compose(
DarknetConv2D_BN_Leaky(256, (1,1)),
UpSampling2D(2))(x)
x = Concatenate()([x,darknet.layers[152].output])
x, y2 = make_last_layers(x, 256, num_anchors*(num_classes+5))
x = compose(
DarknetConv2D_BN_Leaky(128, (1,1)),
UpSampling2D(2))(x)
x = Concatenate()([x,darknet.layers[92].output])
x, y3 = make_last_layers(x, 128, num_anchors*(num_classes+5))
return Model(inputs, [y1,y2,y3])
def tiny_yolo_body(inputs, num_anchors, num_classes):
'''Create Tiny YOLO_v3 model CNN body in keras.'''
x1 = compose(
DarknetConv2D_BN_Leaky(16, (3,3)),
MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='same'),
DarknetConv2D_BN_Leaky(32, (3,3)),
MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='same'),
DarknetConv2D_BN_Leaky(64, (3,3)),
MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='same'),
DarknetConv2D_BN_Leaky(128, (3,3)),
MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='same'),
DarknetConv2D_BN_Leaky(256, (3,3)))(inputs)
x2 = compose(
MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='same'),
DarknetConv2D_BN_Leaky(512, (3,3)),
MaxPooling2D(pool_size=(2,2), strides=(1,1), padding='same'),
DarknetConv2D_BN_Leaky(1024, (3,3)),
DarknetConv2D_BN_Leaky(256, (1,1)))(x1)
y1 = compose(
DarknetConv2D_BN_Leaky(512, (3,3)),
DarknetConv2D(num_anchors*(num_classes+5), (1,1)))(x2)
x2 = compose(
DarknetConv2D_BN_Leaky(128, (1,1)),
UpSampling2D(2))(x2)
y2 = compose(
Concatenate(),
DarknetConv2D_BN_Leaky(256, (3,3)),
DarknetConv2D(num_anchors*(num_classes+5), (1,1)))([x2,x1])
return Model(inputs, [y1,y2])
def yolo_head(feats, anchors, num_classes, input_shape, calc_loss=False):
"""Convert final layer features to bounding box parameters."""
num_anchors = len(anchors) #num_anchors = 3
# Reshape to batch, height, width, num_anchors, box_params.
anchors_tensor = K.reshape(K.constant(anchors), [1, 1, 1, num_anchors, 2]) #reshape ->(1,1,1,3,2)
grid_shape = K.shape(feats)[1:3] # height, width (?,13,13,27) -> (13,13)
#grid_y和grid_x用于生成网格grid,通过arange、reshape、tile的组合, 创建y轴的0~12的组合#grid_y,再创建x轴的0~12的组合grid_x,将两者拼接concatenate,就是grid;
grid_y = K.tile(K.reshape(K.arange(0, stop=grid_shape[0]), [-1, 1, 1, 1]),
[1, grid_shape[1], 1, 1])
grid_x = K.tile(K.reshape(K.arange(0, stop=grid_shape[1]), [1, -1, 1, 1]),
[grid_shape[0], 1, 1, 1])
grid = K.concatenate([grid_x, grid_y])
grid = K.cast(grid, K.dtype(feats)) #K.cast():把grid中值的类型变为和feats中值的类型一样
feats = K.reshape(
feats, [-1, grid_shape[0], grid_shape[1], num_anchors, num_classes + 5])
#将feats的最后一维展开,将anchors与其他数据(类别数+4个框值+框置信度)分离
# Adjust preditions to each spatial grid point and anchor size.
#xywh的计算公式,见边界框回归公式。
#tx、ty、tw和th是feats值,而bx、by、bw和bh是输出值
box_xy = (K.sigmoid(feats[..., :2]) + grid) / K.cast(grid_shape[::-1], K.dtype(feats)) #sigmoid:σ
box_wh = K.exp(feats[..., 2:4]) * anchors_tensor / K.cast(input_shape[::-1], K.dtype(feats))
box_confidence = K.sigmoid(feats[..., 4:5])
box_class_probs = K.sigmoid(feats[..., 5:])
# ...操作符,在Python中,“...”(ellipsis)操作符,表示其他维度不变,只操作最前或最后1维;
if calc_loss == True:
return grid, feats, box_xy, box_wh
# 将box_xy,box_xy 从OUTPUT的预测数据转为真实坐标。
return box_xy, box_wh, box_confidence, box_class_probs
def yolo_correct_boxes(box_xy, box_wh, input_shape, image_shape): #得到正确的x,y,w,h
'''Get corrected boxes'''
box_yx = box_xy[..., ::-1] #“::-1”是颠倒数组的值
box_hw = box_wh[..., ::-1]
input_shape = K.cast(input_shape, K.dtype(box_yx))
image_shape = K.cast(image_shape, K.dtype(box_yx))
new_shape = K.round(image_shape * K.min(input_shape/image_shape))
offset = (input_shape-new_shape)/2./input_shape
scale = input_shape/new_shape
box_yx = (box_yx - offset) * scale
box_hw *= scale
box_mins = box_yx - (box_hw / 2.)
box_maxes = box_yx + (box_hw / 2.)
boxes = K.concatenate([
box_mins[..., 0:1], # y_min
box_mins[..., 1:2], # x_min
box_maxes[..., 0:1], # y_max
box_maxes[..., 1:2] # x_max
])
# Scale boxes back to original image shape.
boxes *= K.concatenate([image_shape, image_shape])
return boxes
def yolo_boxes_and_scores(feats, anchors, num_classes, input_shape, image_shape):
# feats:输出的shape,->(?,13,13,27); anchors:每层对应的3个anchor box
# num_classes: 类别数(4); input_shape:(416,416); image_shape:图像尺寸
'''Process Conv layer output'''
box_xy, box_wh, box_confidence, box_class_probs = yolo_head(feats,
anchors, num_classes, input_shape)
#yolo_head():box_xy是box的中心坐标,(0~1)相对位置;box_wh是box的宽高,(0~1)相对值;
#box_confidence是框中物体置信度;box_class_probs是类别置信度;
boxes = yolo_correct_boxes(box_xy, box_wh, input_shape, image_shape)
#将box_xy和box_wh的(0~1)相对值,转换为真实坐标,输出boxes是(y_min,x_min,y_max,x_max)的#值
boxes = K.reshape(boxes, [-1, 4])
#reshape,将不同网格的值转换为框的列表。即(?,13,13,3,4)->(?,4) ?:框的数目
box_scores = box_confidence * box_class_probs
#框的得分=框的置信度*类别置信度
box_scores = K.reshape(box_scores, [-1, num_classes])
#reshape,将框的得分展平,变为(?,4); ?:框的数目
return boxes, box_scores
def yolo_eval(yolo_outputs,
#模型输出,格式如下[(?,13,13,27)(?,26,26,27)(?,52,52,27)] ?:bitch size; 13-26-52:多尺度预测; 27:预测值(3*(4+5))
anchors,
#[(10,13), (16,30), (33,23), (30,61), (62,45), (59,119), (116,90), (156,198),(373,326)]
num_classes, # 类别个数,此数据集有4类
image_shape, #placeholder类型的TF参数,默认(416, 416);
max_boxes=20,
#每张图每类最多检测到20个框同类别框的IoU阈值,大于阈值的重叠框被删除,重叠物体较多,则调高阈值,重叠物体较少,则调低阈值
score_threshold=.6,
#框置信度阈值,小于阈值的框被删除,需要的框较多,则调低阈值,需要的框较少,则调高阈值;
iou_threshold=.5):
#同类别框的IoU阈值,大于阈值的重叠框被删除,重叠物体较多,则调高阈值,重叠物体较少,则调低阈值
"""Evaluate YOLO model on given input and return filtered boxes."""
num_layers = len(yolo_outputs) #yolo的输出层数;num_layers = 3 -> 13-26-52
# 不同的欺骗对应不同的ANCHOR大小。
anchor_mask = [[6,7,8], [3,4,5], [0,1,2]] if num_layers==3 else [[3,4,5], [1,2,3]] # default setting
#每层分配3个anchor box.如13*13分配到[6,7,8]即[(116,90)(156,198)(373,326)]
input_shape = K.shape(yolo_outputs[0])[1:3] * 32
#输入shape(?,13,13,255);即第一维和第二维分别乘32,输出的图片尺寸为(416,416)
boxes = []
box_scores = []
for l in range(num_layers):
_boxes, _box_scores = yolo_boxes_and_scores(yolo_outputs[l],
# yolo_boxes_and_scores()函数见附录yolo3.model
anchors[anchor_mask[l]], num_classes, input_shape, image_shape)
boxes.append(_boxes)
box_scores.append(_box_scores)
boxes = K.concatenate(boxes, axis=0) #K.concatenate:将数据展平 ->(?,4)
box_scores = K.concatenate(box_scores, axis=0) # ->(?,)
mask = box_scores >= score_threshold
#MASK掩码,过滤小于score阈值的值,只保留大于阈值的值
max_boxes_tensor = K.constant(max_boxes, dtype='int32') #最大检测框数20
boxes_ = []
scores_ = []
classes_ = []
for c in range(num_classes):
# TODO: use keras backend instead of tf.
class_boxes = tf.boolean_mask(boxes, mask[:, c]) #通过掩码MASK和类别C筛选框boxes
class_box_scores = tf.boolean_mask(box_scores[:, c], mask[:, c])
#通过掩码MASK和类别C筛选scores
nms_index = tf.image.non_max_suppression( #运行非极大抑制
class_boxes, class_box_scores, max_boxes_tensor, iou_threshold=iou_threshold)
class_boxes = K.gather(class_boxes, nms_index)
#K.gather:根据索引nms_index选择class_boxes
class_box_scores = K.gather(class_box_scores, nms_index)
#根据索引nms_index选择class_box_score)
classes = K.ones_like(class_box_scores, 'int32') * c #计算类的框得分
boxes_.append(class_boxes)
scores_.append(class_box_scores)
classes_.append(classes)
boxes_ = K.concatenate(boxes_, axis=0)
#K.concatenate().将相同维度的数据连接在一起;把boxes_展平。 -> 变成格式:(?,4); ?:框的个#数;4:(x,y,w,h)
scores_ = K.concatenate(scores_, axis=0)
classes_ = K.concatenate(classes_, axis=0)
return boxes_, scores_, classes_
#图片缩放到固定大小之后就是生成对应的数据
#通过model.py(preprocess_true_boxes实现box框的框定
def preprocess_true_boxes(true_boxes, input_shape, anchors, num_classes):
'''Preprocess true boxes to training input format
Parameters
----------
true_boxes: array, shape=(m, T, 5)
Absolute x_min, y_min, x_max, y_max, class_id relative to input_shape.
input_shape: array-like, hw, multiples of 32
anchors: array, shape=(N, 2), wh
num_classes: integer
Returns
-------
y_true: list of array, shape like yolo_outputs, xywh are reletive value
'''
assert (true_boxes[..., 4]0
#每个图片都需要单独处理。
for b in range(m):
# Discard zero rows.
wh = boxes_wh[b, valid_mask[b]]
if len(wh)==0: continue
# Expand dim to apply broadcasting.
wh = np.expand_dims(wh, -2)
box_maxes = wh / 2.
box_mins = -box_maxes
intersect_mins = np.maximum(box_mins, anchor_mins)
intersect_maxes = np.minimum(box_maxes, anchor_maxes)
intersect_wh = np.maximum(intersect_maxes - intersect_mins, 0.)
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
box_area = wh[..., 0] * wh[..., 1]
anchor_area = anchors[..., 0] * anchors[..., 1]
iou = intersect_area / (box_area + anchor_area - intersect_area)
# Find best anchor for each true box
# 9个设定的ANCHOR去框定每个输入的BOX。
best_anchor = np.argmax(iou, axis=-1)
for t, n in enumerate(best_anchor):
for l in range(num_layers):
if n in anchor_mask[l]:
i = np.floor(true_boxes[b,t,0]*grid_shapes[l][1]).astype('int32')
j = np.floor(true_boxes[b,t,1]*grid_shapes[l][0]).astype('int32')
k = anchor_mask[l].index(n)
c = true_boxes[b,t, 4].astype('int32')
# 设定数据
# 将T个box的标的数据统一放置到3*B*W*H*3的维度上。
y_true[l][b, j, i, k, 0:4] = true_boxes[b,t, 0:4]
y_true[l][b, j, i, k, 4] = 1
y_true[l][b, j, i, k, 5+c] = 1
return y_true
def box_iou(b1, b2):
'''Return iou tensor
Parameters
----------
b1: tensor, shape=(i1,...,iN, 4), xywh
b2: tensor, shape=(j, 4), xywh
Returns
-------
iou: tensor, shape=(i1,...,iN, j)
'''
# Expand dim to apply broadcasting.
b1 = K.expand_dims(b1, -2)
b1_xy = b1[..., :2]
b1_wh = b1[..., 2:4]
b1_wh_half = b1_wh/2.
b1_mins = b1_xy - b1_wh_half
b1_maxes = b1_xy + b1_wh_half
# Expand dim to apply broadcasting.
b2 = K.expand_dims(b2, 0)
b2_xy = b2[..., :2]
b2_wh = b2[..., 2:4]
b2_wh_half = b2_wh/2.
b2_mins = b2_xy - b2_wh_half
b2_maxes = b2_xy + b2_wh_half
intersect_mins = K.maximum(b1_mins, b2_mins)
intersect_maxes = K.minimum(b1_maxes, b2_maxes)
intersect_wh = K.maximum(intersect_maxes - intersect_mins, 0.)
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
b1_area = b1_wh[..., 0] * b1_wh[..., 1]
b2_area = b2_wh[..., 0] * b2_wh[..., 1]
iou = intersect_area / (b1_area + b2_area - intersect_area)
return iou
def yolo_loss(args, anchors, num_classes, ignore_thresh=.5, print_loss=False):
'''Return yolo_loss tensor
Parameters
----------
yolo_outputs: list of tensor, the output of yolo_body or tiny_yolo_body
y_true: list of array, the output of preprocess_true_boxes
anchors: array, shape=(N, 2), wh
num_classes: integer
ignore_thresh: float, the iou threshold whether to ignore object confidence loss
Returns
-------
loss: tensor, shape=(1,)
'''
num_layers = len(anchors)//3 # default setting
yolo_outputs = args[:num_layers]
y_true = args[num_layers:]
# 不同的欺骗对应不同的ANCHOR大小。
anchor_mask = [[6,7,8], [3,4,5], [0,1,2]] if num_layers==3 else [[3,4,5], [1,2,3]]
# 根据模型返回的OUTPUT计算输入图片SHAPE以及3个LAYER下,3个切片的大小。
input_shape = K.cast(K.shape(yolo_outputs[0])[1:3] * 32, K.dtype(y_true[0]))
grid_shapes = [K.cast(K.shape(yolo_outputs[l])[1:3], K.dtype(y_true[0])) for l in range(num_layers)]
loss = 0
m = K.shape(yolo_outputs[0])[0] # batch size, tensor #m表示采样batch_size
mf = K.cast(m, K.dtype(yolo_outputs[0]))
# loss是需要三层分别计算的
for l in range(num_layers):
# 置信率
object_mask = y_true[l][..., 4:5]
# 分类
true_class_probs = y_true[l][..., 5:]
# raw_pred是yolo_outputs[l],经过yolo_head函数后,raw_pred数据并没有改变。
grid, raw_pred, pred_xy, pred_wh = yolo_head(yolo_outputs[l],
anchors[anchor_mask[l]], num_classes, input_shape, calc_loss=True)
pred_box = K.concatenate([pred_xy, pred_wh])
# Darknet raw box to calculate loss.
# Darknet原始盒子来计算损失。
raw_true_xy = y_true[l][..., :2]*grid_shapes[l][::-1] - grid
raw_true_wh = K.log(y_true[l][..., 2:4] / anchors[anchor_mask[l]] * input_shape[::-1])
raw_true_wh = K.switch(object_mask, raw_true_wh, K.zeros_like(raw_true_wh)) # avoid log(0)=-inf
box_loss_scale = 2 - y_true[l][...,2:3]*y_true[l][...,3:4]
# Find ignore mask, iterate over each of batch.
ignore_mask = tf.TensorArray(K.dtype(y_true[0]), size=1, dynamic_size=True)
object_mask_bool = K.cast(object_mask, 'bool')
# loop_body计算batch_size内最大的IOU
def loop_body(b, ignore_mask):
# tf.boolean_mask Apply boolean mask to tensor. Numpy equivalent is tensor[mask]. 根据y_true的置信度标识,来框定y_true的坐标系参数是否有效。
true_box = tf.boolean_mask(y_true[l][b,...,0:4], object_mask_bool[b,...,0])
iou = box_iou(pred_box[b], true_box)
best_iou = K.max(iou, axis=-1)
#当一张图片的最大IOU低于ignore_thresh,则认为图片内是没有目标
ignore_mask = ignore_mask.write(b, K.cast(best_iou 附录B
训练和检测都导入了yolo3.utils:
#yolo3.utils中是其他使用函数,主要用于keras-yolo数据增强的一些方法。
"""Miscellaneous utility functions."""
from functools import reduce
from PIL import Image
import numpy as np
from matplotlib.colors import rgb_to_hsv, hsv_to_rgb
def compose(*funcs):
"""Compose arbitrarily many functions, evaluated left to right.
Reference: https://mathieularose.com/function-composition-in-python/
"""
# return lambda x: reduce(lambda v, f: f(v), funcs, x)
if funcs:
return reduce(lambda f, g: lambda *a, **kw: g(f(*a, **kw)), funcs)
else:
raise ValueError('Composition of empty sequence not supported.')
def letterbox_image(image, size):
'''resize image with unchanged aspect ratio using padding'''
iw, ih = image.size
w, h = size
scale = min(w/iw, h/ih)
nw = int(iw*scale)
nh = int(ih*scale)
image = image.resize((nw,nh), Image.BICUBIC)
new_image = Image.new('RGB', size, (128,128,128))
new_image.paste(image, ((w-nw)//2, (h-nh)//2))
return new_image
def rand(a=0, b=1):
return np.random.rand()*(b-a) + a
#在utils.py(get_random_data)函数中实现数据处理
def get_random_data(annotation_line, input_shape, random=True, max_boxes=20, jitter=.3, hue=.1, sat=1.5, val=1.5, proc_img=True):
'''random preprocessing for real-time data augmentation'''
line = annotation_line.split()
image = Image.open(line[0])
iw, ih = image.size
h, w = input_shape
box = np.array([np.array(list(map(int,box.split(',')))) for box in line[1:]])
#not random的实现
if not random:
# resize image
#缩放大小
scale = min(w/iw, h/ih)
nw = int(iw*scale)
nh = int(ih*scale)
#中心点
dx = (w-nw)//2
dy = (h-nh)//2
image_data=0
if proc_img:
image = image.resize((nw,nh), Image.BICUBIC)
#背景
new_image = Image.new('RGB', (w,h), (128,128,128))
#黏贴图pain
new_image.paste(image, (dx, dy))
#归一化
image_data = np.array(new_image)/255.
# correct boxes
box_data = np.zeros((max_boxes,5))
if len(box)>0:
np.random.shuffle(box)
# 最大20个BOX。
if len(box)>max_boxes: box = box[:max_boxes]
#根据缩放大小,生成新图中的BOX位置
box[:, [0,2]] = box[:, [0,2]]*scale + dx
box[:, [1,3]] = box[:, [1,3]]*scale + dy
box_data[:len(box)] = box
return image_data, box_data
# resize image
# 随机生成宽高比
new_ar = w/h * rand(1-jitter,1+jitter)/rand(1-jitter,1+jitter)
# 随机生成缩放比例。
scale = rand(.25, 2)
# 生成新的高宽数据,可能放大2倍。
if new_ar < 1:
nh = int(scale*h)
nw = int(nh*new_ar)
else:
nw = int(scale*w)
nh = int(nw/new_ar)
image = image.resize((nw,nh), Image.BICUBIC)
# place image
# 随机水平位移
dx = int(rand(0, w-nw))
dy = int(rand(0, h-nh))
new_image = Image.new('RGB', (w,h), (128,128,128))
new_image.paste(image, (dx, dy))
image = new_image
# flip image or not
# 翻转
flip = rand()<.5
if flip: image = image.transpose(Image.FLIP_LEFT_RIGHT)
# distort image
# HSV抖动
hue = rand(-hue, hue)
sat = rand(1, sat) if rand()<.5 else 1/rand(1, sat)
val = rand(1, val) if rand()<.5 else 1/rand(1, val)
# 归一化处理
# 内部函数,通过公式转化。具体函数不介绍。
x = rgb_to_hsv(np.array(image)/255.)
x[..., 0] += hue
x[..., 0][x[..., 0]>1] -= 1
x[..., 0][x[..., 0]<0] += 1
x[..., 1] *= sat
x[..., 2] *= val
# 避免S/V CHANNEL越界
x[x>1] = 1
x[x<0] = 0
image_data = hsv_to_rgb(x) # numpy array, 0 to 1
# correct boxes
box_data = np.zeros((max_boxes,5))
if len(box)>0:
np.random.shuffle(box)
box[:, [0,2]] = box[:, [0,2]]*nw/iw + dx
box[:, [1,3]] = box[:, [1,3]]*nh/ih + dy
### 左右翻转
if flip: box[:, [0,2]] = w - box[:, [2,0]]
### 定义边界
box[:, 0:2][box[:, 0:2]<0] = 0
box[:, 2][box[:, 2]>w] = w
box[:, 3][box[:, 3]>h] = h
### 计算新的长宽
box_w = box[:, 2] - box[:, 0]
box_h = box[:, 3] - box[:, 1]
box = box[np.logical_and(box_w>1, box_h>1)] # discard invalid box
if len(box)>max_boxes: box = box[:max_boxes]
box_data[:len(box)] = box
return image_data, box_data
请各位关注公众号,回复0115,获得下载链接。更多的文章可以关注公众号查看。
