Trie树分析
Trie树
Trie树介绍
Trie,又称单词查找树或键树,是一种树形结构。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。
它有3个基本性质:
1.根节点不包含字符,除根节点外每一个节点都只包含一个字符。
2.从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
3.每个节点的所有子节点包含的字符都不相同。
Trie中每个节点有一个特殊标记作为结束符号,通过该标记可以判断当前节点是否是一个字符串的终结节点。
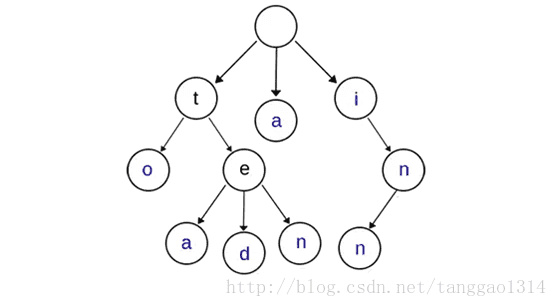
下图是一个Trie树的例子,记录了to,tea,ted,ten,a,i,in,inn这些words(以蓝色结尾)。
个人总结了如下方法:
Trie树的节点类
class Node{
//节点字符值
private char val;
//节点的子节点,即以根节点到该节点的值组成的字符串为前缀的字符串构建的节点
private Map childrens=new HashMap();
//是否为结束节点,即一个字符串是否到达末尾节点 当end>0时表示结束节点
private int end=0;
//从根节点到该结束节点组成的字符串的重复数量 即单词列表中每个单词的词频
private int dumpliNum=0;
//以到达该节点组成的子串为前缀的字符串数量
private int prexNum=0;
/**
* @return the dumpliNum
*/
public int getDumpliNum() {
return dumpliNum;
}
/**
* @param dumpliNum the dumpliNum to set
*/
public void setDumpliNum(int dumpliNum) {
this.dumpliNum = dumpliNum;
}
/**
* @return the prexNum
*/
public int getPrexNum() {
return prexNum;
}
/**
* @param prexNum the prexNum to set
*/
public void setPrexNum(int prexNum) {
this.prexNum = prexNum;
}
/**
* @return the val
*/
public char getVal() {
return val;
}
/**
* @param val the val to set
*/
public void setVal(char val) {
this.val = val;
}
/**
* @return the childrens
*/
public Map getChildrens() {
return childrens;
}
/**
* @param childrens the childrens to set
*/
public void setChildrens(Map childrens) {
this.childrens = childrens;
}
/**
* @return the end
*/
public int getEnd() {
return end;
}
/**
* @param end the end to set
*/
public void setEnd(int end) {
this.end = end;
}
} Trie树的初始化
public class Trie {
//待构建的字符串列表
private String words[];
private Node root;
public Trie(String[] words){
this.root=new Node();
this.words=words;
}
}Trie树的插入
//插入方法
public void insert(String word){
if(word==""||word==null){
return;
}
Node cur=root;
char [] chars=word.toCharArray();
for(int i=0;iTrie树的构建
public Node builtTrie(){
for (int i=0;iTrie树的查找
public boolean search(String word){
boolean flag=true;
Node cur=root;
char[] chars=word.toCharArray();
for(int i=0;i0;//并且字符串最后一个字符必须是结束节点
}
Trie树中是否包某个前缀
//以某个字符串开头 比如字符串列表中有[abb,abbb],则ab返回true
public boolean startWith(String word){
boolean flag=true;
Node cur=root;
char[] chars=word.toCharArray();
for(int i=0;i0;//并且该节点是结束节点
return flag;//和查找相比去掉了字符串最后一个字符要是结束节点
} Trie树前序遍历
// 前序遍历,获取从指定节点开始,到所有结束节点组成的字符串
Map preTraversal(Nodenode,String word){
Map m=new HashMap();
if(node!=null){
if(node!=root&&node.getEnd()>0){
m.put(word, node);
}
for(Map.Entryentry:node.getChildrens().entrySet()){
Node cur=entry.getValue();
String temp=word+String.valueOf(cur.getVal());
m.putAll(preTraversal(cur,temp));
}
}
return m;
}
获取指定前缀出现次数
//获取指定前缀出现次数
int countPrefix(String prefix){
Node cur =root;
char[] chars=prefix.toCharArray();
while(cur.getChildrens().size()>0){
for(int i=0;i
获取含有指定前缀的所有单词
//获取含有指定前缀的所有单词
MapcontainPrefixOfwords(String prefix){
Map m=newHashMap();
//找到前缀的最后一个单词的所在节点
Node cur=root;
char[] chars=prefix.toCharArray();
while(cur.getChildrens().size()>0){
for(int i=0;i 全部代码和测试类
package trie;
import java.util.HashMap;
import java.util.Map;
import java.util.Stack;
/**
*
*Trie
* Trie树
*@author: 汤高
*@date: :2018-1-8 下午4:33:44
*@version 1.0
*/
public class Trie {
//待构建的字符串列表
private String words[];
private Node root;
public Trie(String[] words){
this.root=new Node();
this.words=words;
}
public Node builtTrie(){
int index=0;
for (int i=0;i0;//并且字符串最后一个字符必须是结束节点
}
//以某个字符串开头 比如 字符串列表中有[abb,abbb],则ab返回true
public boolean startWith(String word){
boolean flag=true;
Node cur=root;
char[] chars=word.toCharArray();
for(int i=0;i0;//并且该节点是结束节点
return flag;//和查找相比去掉了 字符串最后一个字符要是结束节点
}
//前序遍历
Map preTraversal(Node node,String word){
Map m=new HashMap();
if(node!=null){
if(node!=root&&node.getEnd()>0){
m.put(word, node);
}
for(Map.Entry entry:node.getChildrens().entrySet()){
Node cur=entry.getValue();
String temp=word+String.valueOf(cur.getVal());
m.putAll(preTraversal(cur,temp));
}
}
return m;
}
//获取指定前缀出现次数
int countPrefix(String prefix){
Node cur =root;
char[] chars=prefix.toCharArray();
while(cur.getChildrens().size()>0){
for(int i=0;i containPrefixOfwords(String prefix){
Map m=new HashMap();
//找到前缀的最后一个单词的所在节点
Node cur=root;
char[] chars=prefix.toCharArray();
while(cur.getChildrens().size()>0){
for(int i=0;i stack=new Stack();
stack.push(root);
while(!stack.isEmpty()){
Node node=stack.pop();
if(node.getEnd()>0||node==root){
if(node!=root){
String word= this.words[node.getEnd()-1];
if(word.length()>result.length()||
word.length()==result.length()&&result.compareTo(word)>0){//最长的且具有最小字典序的word
result=word;
}
}
for(Node n:node.getChildrens().values()){//拿到子节点
stack.push(n);
}
}
}
return result;
}
class Node{
//节点字符值
private char val;
//节点的子节点,即以根节点到该节点的值组成的字符串为前缀的字符串构建的节点
private Map childrens=new HashMap();
//是否为结束节点,即一个字符串是否到达末尾节点 当end>0时表示结束节点
private int end=0;
//从根节点到该结束节点组成的字符串的重复数量 即单词列表中每个单词的词频
private int dumpliNum=0;
//以到达该节点组成的子串为前缀的字符串数量
private int prexNum=0;
/**
* @return the dumpliNum
*/
public int getDumpliNum() {
return dumpliNum;
}
/**
* @param dumpliNum the dumpliNum to set
*/
public void setDumpliNum(int dumpliNum) {
this.dumpliNum = dumpliNum;
}
/**
* @return the prexNum
*/
public int getPrexNum() {
return prexNum;
}
/**
* @param prexNum the prexNum to set
*/
public void setPrexNum(int prexNum) {
this.prexNum = prexNum;
}
/**
* @return the val
*/
public char getVal() {
return val;
}
/**
* @param val the val to set
*/
public void setVal(char val) {
this.val = val;
}
/**
* @return the childrens
*/
public Map getChildrens() {
return childrens;
}
/**
* @param childrens the childrens to set
*/
public void setChildrens(Map childrens) {
this.childrens = childrens;
}
/**
* @return the end
*/
public int getEnd() {
return end;
}
/**
* @param end the end to set
*/
public void setEnd(int end) {
this.end = end;
}
}
public static void main(String[] args) {
String[] words=new String[]{"ab","abb","ab","abbc","b","ba","bdd"};
Trie t=new Trie(words);
Node root=t.builtTrie();//构建trie树
System.out.println("trie树包含bdd吗? "+t.search("bdd"));
System.out.println("trie树包含bd吗? "+t.search("bd"));
System.out.println("trie树包含bd前缀吗?"+t.startWith("bd"));
System.out.println("trie树包含bdX前缀吗?"+t.startWith("bdX"));
System.out.println("根节点前序遍历,获取所有单词和它出现的次数");
for(Map.Entry en:t.preTraversal(root, "").entrySet()){
System.out.println(en.getKey()+"出现几次:"+en.getValue().dumpliNum);
}
System.out.println("以ab开头的前缀出现几次:"+t.countPrefix("ab"));
System.out.println("包含ab为前缀的所有单词");
for(Map.Entry en:t.containPrefixOfwords("ab").entrySet()){
System.out.println(en.getKey()+"单词出现几次:"+en.getValue().dumpliNum);
}
}
}
测试结果
trie树包含bdd吗? true
trie树包含bd吗? false
trie树包含bd前缀吗?true
trie树包含bdX前缀吗?false
根节点前序遍历,获取所有单词和它出现的次数
abb出现几次:1
b出现几次:1
ba出现几次:1
bdd出现几次:1
abbc出现几次:1
ab出现几次:2
以ab开头的前缀出现几次:4
包含ab为前缀的所有单词
abb单词出现几次:1
ab单词出现几次:2
abbc单词出现几次:1
转载请指明http://blog.csdn.net/tanggao1314/article/details/79004795