一起来学k8s 16.flannel
Flannel
Flannel 项目是 CoreOS 公司主推的容器网络方案。事实上,Flannel 项目本身只是一个框架,真正为我们提供容器网络功能的,是 Flannel 的后端实现。目前,Flannel 支持三种后端实现,分别是:
- UDP
- Vxlan
- Host-gw
环境
192.168.48.101 master01
192.168.48.201 node01
192.168.48.202 node02
UDP
UDP 模式,是 Flannel 项目最早支持的一种方式,却也是性能最差的一种方式。所以,这个模式目前已经被弃用。不过,Flannel 之所以最先选择 UDP 模式,就是因为这种模式是最直接、也是最容易理解的容器跨主网络实现。
所以,在今天这篇文章中,我会先从 UDP 模式开始,来为你讲解容器“跨主网络”的实现原理。
在这个例子中,我有两台宿主机。
- 宿主机 Node 1 上有一个容器 container-1,它的 IP 地址是 100.96.1.2,对应的 docker0 网桥的地址是:100.96.1.1/24。
- 宿主机 Node 2 上有一个容器 container-2,它的 IP 地址是 100.96.2.3,对应的 docker0 网桥的地址是:100.96.2.1/24。
我们现在的任务,就是让 container-1 访问 container-2。
这种情况下,container-1 容器里的进程发起的 IP 包,其源地址就是 100.96.1.2,目的地址就是 100.96.2.3。由于目的地址 100.96.2.3 并不在 Node 1 的 docker0 网桥的网段里,所以这个 IP 包会被交给默认路由规则,通过容器的网关进入 docker0 网桥(如果是同一台宿主机上的容器间通信,走的是直连规则),从而出现在宿主机上。
这时候,这个 IP 包的下一个目的地,就取决于宿主机上的路由规则了。此时,Flannel 已经在宿主机上创建出了一系列的路由规则,以 Node 1 为例,如下所示:
# 在 Node 1 上
$ ip route
default via 10.168.0.1 dev eth0
100.96.0.0/16 dev flannel0 proto kernel scope link src 100.96.1.0
100.96.1.0/24 dev docker0 proto kernel scope link src 100.96.1.1
10.168.0.0/24 dev eth0 proto kernel scope link src 10.168.0.2
可以看到,由于我们的 IP 包的目的地址是 100.96.2.3,它匹配不到本机 docker0 网桥对应的 100.96.1.0/24 网段,只能匹配到第二条、也就是 100.96.0.0/16 对应的这条路由规则,从而进入到一个叫作 flannel0 的设备中。
而这个 flannel0 设备的类型就比较有意思了:它是一个 TUN 设备(Tunnel 设备)。
在 Linux 中,TUN 设备是一种工作在三层(Network Layer)的虚拟网络设备。TUN 设备的功能非常简单,即:在操作系统内核和用户应用程序之间传递 IP 包。
以 flannel0 设备为例:
像上面提到的情况,当操作系统将一个 IP 包发送给 flannel0 设备之后,flannel0 就会把这个 IP 包,交给创建这个设备的应用程序,也就是 Flannel 进程。这是一个从内核态(Linux 操作系统)向用户态(Flannel 进程)的流动方向。
反之,如果 Flannel 进程向 flannel0 设备发送了一个 IP 包,那么这个 IP 包就会出现在宿主机网络栈中,然后根据宿主机的路由表进行下一步处理。这是一个从用户态向内核态的流动方向。
所以,当 IP 包从容器经过 docker0 出现在宿主机,然后又根据路由表进入 flannel0 设备后,宿主机上的 flanneld 进程(Flannel 项目在每个宿主机上的主进程),就会收到这个 IP 包。然后,flanneld 看到了这个 IP 包的目的地址,是 100.96.2.3,就把它发送给了 Node 2 宿主机。
等一下,flanneld 又是如何知道这个 IP 地址对应的容器,是运行在 Node 2 上的呢?
这里,就用到了 Flannel 项目里一个非常重要的概念:子网(Subnet)。
事实上,在由 Flannel 管理的容器网络里,一台宿主机上的所有容器,都属于该宿主机被分配的一个“子网”。在我们的例子中,Node 1 的子网是 100.96.1.0/24,container-1 的 IP 地址是 100.96.1.2。Node 2 的子网是 100.96.2.0/24,container-2 的 IP 地址是 100.96.2.3。
而这些子网与宿主机的对应关系,正是保存在 Etcd 当中,如下所示:
$ etcdctl ls /coreos.com/network/subnets
/coreos.com/network/subnets/100.96.1.0-24
/coreos.com/network/subnets/100.96.2.0-24
/coreos.com/network/subnets/100.96.3.0-24
所以,flanneld 进程在处理由 flannel0 传入的 IP 包时,就可以根据目的 IP 的地址(比如 100.96.2.3),匹配到对应的子网(比如 100.96.2.0/24),从 Etcd 中找到这个子网对应的宿主机的 IP 地址是 10.168.0.3,如下所示:
$ etcdctl get /coreos.com/network/subnets/100.96.2.0-24
{"PublicIP":"10.168.0.3"}
而对于 flanneld 来说,只要 Node 1 和 Node 2 是互通的,那么 flanneld 作为 Node 1 上的一个普通进程,就一定可以通过上述 IP 地址(10.168.0.3)访问到 Node 2,这没有任何问题。
所以说,flanneld 在收到 container-1 发给 container-2 的 IP 包之后,就会把这个 IP 包直接封装在一个 UDP 包里,然后发送给 Node 2。不难理解,这个 UDP 包的源地址,就是 flanneld 所在的 Node 1 的地址,而目的地址,则是 container-2 所在的宿主机 Node 2 的地址。
当然,这个请求得以完成的原因是,每台宿主机上的 flanneld,都监听着一个 8285 端口,所以 flanneld 只要把 UDP 包发往 Node 2 的 8285 端口即可。
通过这样一个普通的、宿主机之间的 UDP 通信,一个 UDP 包就从 Node 1 到达了 Node 2。而 Node 2 上监听 8285 端口的进程也是 flanneld,所以这时候,flanneld 就可以从这个 UDP 包里解析出封装在里面的、container-1 发来的原 IP 包。
而接下来 flanneld 的工作就非常简单了:flanneld 会直接把这个 IP 包发送给它所管理的 TUN 设备,即 flannel0 设备。
根据我前面讲解的 TUN 设备的原理,这正是一个从用户态向内核态的流动方向(Flannel 进程向 TUN 设备发送数据包),所以 Linux 内核网络栈就会负责处理这个 IP 包,具体的处理方法,就是通过本机的路由表来寻找这个 IP 包的下一步流向。
而 Node 2 上的路由表,跟 Node 1 非常类似,如下所示:
# 在 Node 2 上
$ ip route
default via 10.168.0.1 dev eth0
100.96.0.0/16 dev flannel0 proto kernel scope link src 100.96.2.0
100.96.2.0/24 dev docker0 proto kernel scope link src 100.96.2.1
10.168.0.0/24 dev eth0 proto kernel scope link src 10.168.0.3
由于这个 IP 包的目的地址是 100.96.2.3,它跟第三条、也就是 100.96.2.0/24 网段对应的路由规则匹配更加精确。所以,Linux 内核就会按照这条路由规则,把这个 IP 包转发给 docker0 网桥。
接下来的流程,就如同我在上一篇文章《浅谈容器网络》中和你分享的那样,docker0 网桥会扮演二层交换机的角色,将数据包发送给正确的端口,进而通过 Veth Pair 设备进入到 container-2 的 Network Namespace 里。
而 container-2 返回给 container-1 的数据包,则会经过与上述过程完全相反的路径回到 container-1 中。
需要注意的是,上述流程要正确工作还有一个重要的前提,那就是 docker0 网桥的地址范围必须是 Flannel 为宿主机分配的子网。这个很容易实现,以 Node 1 为例,你只需要给它上面的 Docker Daemon 启动时配置如下所示的 bip 参数即可:
$ FLANNEL_SUBNET=100.96.1.1/24
$ dockerd --bip=$FLANNEL_SUBNET ...
以上,就是基于 Flannel UDP 模式的跨主通信的基本原理了。我把它总结成了一幅原理图,如下所示。
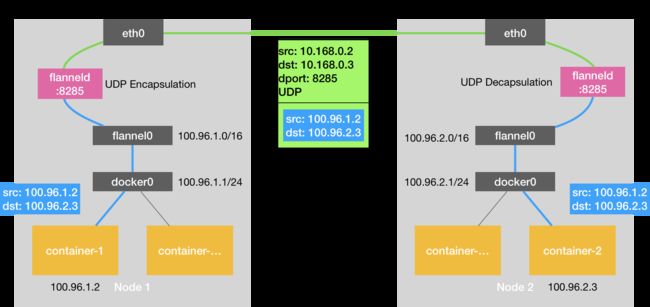
图 1 基于 Flannel UDP 模式的跨主通信的基本原理
可以看到,Flannel UDP 模式提供的其实是一个三层的 Overlay 网络,即:它首先对发出端的 IP 包进行 UDP 封装,然后在接收端进行解封装拿到原始的 IP 包,进而把这个 IP 包转发给目标容器。这就好比,Flannel 在不同宿主机上的两个容器之间打通了一条“隧道”,使得这两个容器可以直接使用 IP 地址进行通信,而无需关心容器和宿主机的分布情况。
我前面曾经提到,上述 UDP 模式有严重的性能问题,所以已经被废弃了。通过我上面的讲述,你有没有发现性能问题出现在了哪里呢?
实际上,相比于两台宿主机之间的直接通信,基于 Flannel UDP 模式的容器通信多了一个额外的步骤,即 flanneld 的处理过程。而这个过程,由于使用到了 flannel0 这个 TUN 设备,仅在发出 IP 包的过程中,就需要经过三次用户态与内核态之间的数据拷贝,如下所示:
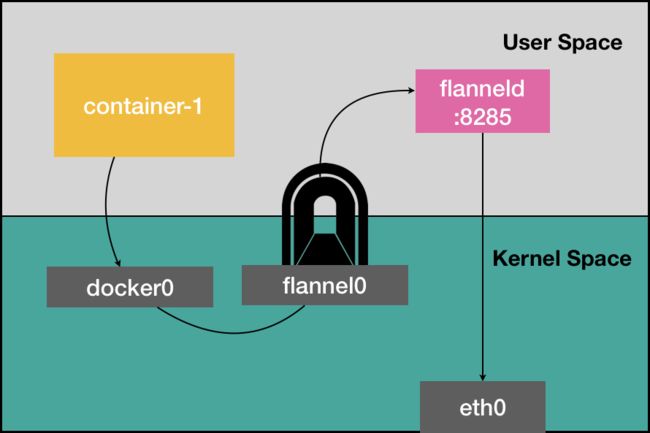
图 2 TUN 设备示意图
我们可以看到:
第一次:用户态的容器进程发出的 IP 包经过 docker0 网桥进入内核态;
第二次:IP 包根据路由表进入 TUN(flannel0)设备,从而回到用户态的 flanneld 进程;
第三次:flanneld 进行 UDP 封包之后重新进入内核态,将 UDP 包通过宿主机的 eth0 发出去。
此外,我们还可以看到,Flannel 进行 UDP 封装(Encapsulation)和解封装(Decapsulation)的过程,也都是在用户态完成的。在 Linux 操作系统中,上述这些上下文切换和用户态操作的代价其实是比较高的,这也正是造成 Flannel UDP 模式性能不好的主要原因。
所以说,我们在进行系统级编程的时候,有一个非常重要的优化原则,就是要减少用户态到内核态的切换次数,并且把核心的处理逻辑都放在内核态进行。这也是为什么,Flannel 后来支持的VXLAN 模式,逐渐成为了主流的容器网络方案的原因。
Vxlan
VXLAN,即 Virtual Extensible LAN(虚拟可扩展局域网),是 Linux 内核本身就支持的一种网络虚似化技术。所以说,VXLAN 可以完全在内核态实现上述封装和解封装的工作,从而通过与前面相似的“隧道”机制,构建出覆盖网络(Overlay Network)。
VXLAN 的覆盖网络的设计思想是:在现有的三层网络之上,“覆盖”一层虚拟的、由内核 VXLAN 模块负责维护的二层网络,使得连接在这个 VXLAN 二层网络上的“主机”(虚拟机或者容器都可以)之间,可以像在同一个局域网(LAN)里那样自由通信。当然,实际上,这些“主机”可能分布在不同的宿主机上,甚至是分布在不同的物理机房里。
而为了能够在二层网络上打通“隧道”,VXLAN 会在宿主机上设置一个特殊的网络设备作为“隧道”的两端。这个设备就叫作 VTEP,即:VXLAN Tunnel End Point(虚拟隧道端点)。
而 VTEP 设备的作用,其实跟前面的 flanneld 进程非常相似。只不过,它进行封装和解封装的对象,是二层数据帧(Ethernet frame);而且这个工作的执行流程,全部是在内核里完成的(因为 VXLAN 本身就是 Linux 内核中的一个模块)。
上述基于 VTEP 设备进行“隧道”通信的流程,我也为你总结成了一幅图,如下所示:
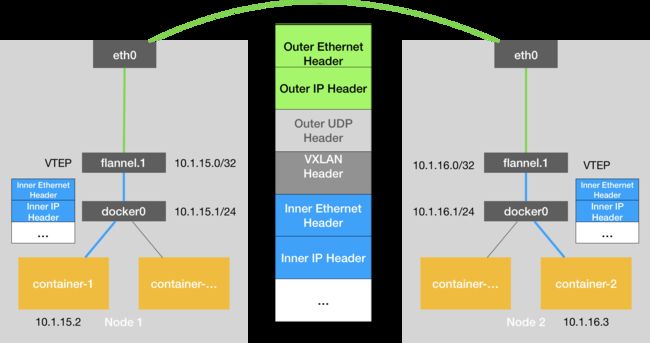
图 3 基于 Flannel VXLAN 模式的跨主通信的基本原理
可以看到,图中每台宿主机上名叫 flannel.1 的设备,就是 VXLAN 所需的 VTEP 设备,它既有 IP 地址,也有 MAC 地址。
现在,我们的 container-1 的 IP 地址是 10.1.15.2,要访问的 container-2 的 IP 地址是 10.1.16.3。
那么,与前面 UDP 模式的流程类似,当 container-1 发出请求之后,这个目的地址是 10.1.16.3 的 IP 包,会先出现在 docker0 网桥,然后被路由到本机 flannel.1 设备进行处理。也就是说,来到了“隧道”的入口。为了方便叙述,我接下来会把这个 IP 包称为“原始 IP 包”。
为了能够将“原始 IP 包”封装并且发送到正确的宿主机,VXLAN 就需要找到这条“隧道”的出口,即:目的宿主机的 VTEP 设备。
而这个设备的信息,正是每台宿主机上的 flanneld 进程负责维护的。
比如,当 Node 2 启动并加入 Flannel 网络之后,在 Node 1(以及所有其他节点)上,flanneld 就会添加一条如下所示的路由规则:
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
...
10.1.16.0 10.1.16.0 255.255.255.0 UG 0 0 0 flannel.1
这条规则的意思是:凡是发往 10.1.16.0/24 网段的 IP 包,都需要经过 flannel.1 设备发出,并且,它最后被发往的网关地址是:10.1.16.0。
从图 3 的 Flannel VXLAN 模式的流程图中我们可以看到,10.1.16.0 正是 Node 2 上的 VTEP 设备(也就是 flannel.1 设备)的 IP 地址。
为了方便叙述,接下来我会把 Node 1 和 Node 2 上的 flannel.1 设备分别称为“源 VTEP 设备”和“目的 VTEP 设备”。
而这些 VTEP 设备之间,就需要想办法组成一个虚拟的二层网络,即:通过二层数据帧进行通信。
所以在我们的例子中,“源 VTEP 设备”收到“原始 IP 包”后,就要想办法把“原始 IP 包”加上一个目的 MAC 地址,封装成一个二层数据帧,然后发送给“目的 VTEP 设备”(当然,这么做还是因为这个 IP 包的目的地址不是本机)。
这里需要解决的问题就是:“目的 VTEP 设备”的 MAC 地址是什么?
此时,根据前面的路由记录,我们已经知道了“目的 VTEP 设备”的 IP 地址。而要根据三层 IP 地址查询对应的二层 MAC 地址,这正是 ARP(Address Resolution Protocol )表的功能。
而这里要用到的 ARP 记录,也是 flanneld 进程在 Node 2 节点启动时,自动添加在 Node 1 上的。我们可以通过 ip 命令看到它,如下所示:
# 在 Node 1 上
$ ip neigh show dev flannel.1
10.1.16.0 lladdr 5e:f8:4f:00:e3:37 PERMANENT
这条记录的意思非常明确,即:IP 地址 10.1.16.0,对应的 MAC 地址是 5e:f8:4f:00:e3:37。
可以看到,最新版本的 Flannel 并不依赖 L3 MISS 事件和 ARP 学习,而会在每台节点启动时把它的 VTEP 设备对应的 ARP 记录,直接下放到其他每台宿主机上。
有了这个“目的 VTEP 设备”的 MAC 地址,Linux 内核就可以开始二层封包工作了。这个二层帧的格式,如下所示:

图 4 Flannel VXLAN 模式的内部帧
可以看到,Linux 内核会把“目的 VTEP 设备”的 MAC 地址,填写在图中的 Inner Ethernet Header 字段,得到一个二层数据帧。
需要注意的是,上述封包过程只是加一个二层头,不会改变“原始 IP 包”的内容。所以图中的 Inner IP Header 字段,依然是 container-2 的 IP 地址,即 10.1.16.3。
但是,上面提到的这些 VTEP 设备的 MAC 地址,对于宿主机网络来说并没有什么实际意义。所以上面封装出来的这个数据帧,并不能在我们的宿主机二层网络里传输。为了方便叙述,我们把它称为“内部数据帧”(Inner Ethernet Frame)。
所以接下来,Linux 内核还需要再把“内部数据帧”进一步封装成为宿主机网络里的一个普通的数据帧,好让它“载着”“内部数据帧”,通过宿主机的 eth0 网卡进行传输。
我们把这次要封装出来的、宿主机对应的数据帧称为“外部数据帧”(Outer Ethernet Frame)。
为了实现这个“搭便车”的机制,Linux 内核会在“内部数据帧”前面,加上一个特殊的 VXLAN 头,用来表示这个“乘客”实际上是一个 VXLAN 要使用的数据帧。
而这个 VXLAN 头里有一个重要的标志叫作VNI,它是 VTEP 设备识别某个数据帧是不是应该归自己处理的重要标识。而在 Flannel 中,VNI 的默认值是 1,这也是为何,宿主机上的 VTEP 设备都叫作 flannel.1 的原因,这里的“1”,其实就是 VNI 的值。
然后,Linux 内核会把这个数据帧封装进一个 UDP 包里发出去。
所以,跟 UDP 模式类似,在宿主机看来,它会以为自己的 flannel.1 设备只是在向另外一台宿主机的 flannel.1 设备,发起了一次普通的 UDP 链接。它哪里会知道,这个 UDP 包里面,其实是一个完整的二层数据帧。这是不是跟特洛伊木马的故事非常像呢?
不过,不要忘了,一个 flannel.1 设备只知道另一端的 flannel.1 设备的 MAC 地址,却不知道对应的宿主机地址是什么。
也就是说,这个 UDP 包该发给哪台宿主机呢?
在这种场景下,flannel.1 设备实际上要扮演一个“网桥”的角色,在二层网络进行 UDP 包的转发。而在 Linux 内核里面,“网桥”设备进行转发的依据,来自于一个叫作 FDB(Forwarding Database)的转发数据库。
不难想到,这个 flannel.1“网桥”对应的 FDB 信息,也是 flanneld 进程负责维护的。它的内容可以通过 bridge fdb 命令查看到,如下所示:
# 在 Node 1 上,使用“目的 VTEP 设备”的 MAC 地址进行查询
$ bridge fdb show flannel.1 | grep 5e:f8:4f:00:e3:37
5e:f8:4f:00:e3:37 dev flannel.1 dst 10.168.0.3 self permanent
可以看到,在上面这条 FDB 记录里,指定了这样一条规则,即:
发往我们前面提到的“目的 VTEP 设备”(MAC 地址是 5e:f8:4f:00:e3:37)的二层数据帧,应该通过 flannel.1 设备,发往 IP 地址为 10.168.0.3 的主机。显然,这台主机正是 Node 2,UDP 包要发往的目的地就找到了。
所以接下来的流程,就是一个正常的、宿主机网络上的封包工作。
我们知道,UDP 包是一个四层数据包,所以 Linux 内核会在它前面加上一个 IP 头,即原理图中的 Outer IP Header,组成一个 IP 包。并且,在这个 IP 头里,会填上前面通过 FDB 查询出来的目的主机的 IP 地址,即 Node 2 的 IP 地址 10.168.0.3。
然后,Linux 内核再在这个 IP 包前面加上二层数据帧头,即原理图中的 Outer Ethernet Header,并把 Node 2 的 MAC 地址填进去。这个 MAC 地址本身,是 Node 1 的 ARP 表要学习的内容,无需 Flannel 维护。这时候,我们封装出来的“外部数据帧”的格式,如下所示:

图 5 Flannel VXLAN 模式的外部帧
这样,封包工作就宣告完成了。
接下来,Node 1 上的 flannel.1 设备就可以把这个数据帧从 Node 1 的 eth0 网卡发出去。显然,这个帧会经过宿主机网络来到 Node 2 的 eth0 网卡。
这时候,Node 2 的内核网络栈会发现这个数据帧里有 VXLAN Header,并且 VNI=1。所以 Linux 内核会对它进行拆包,拿到里面的内部数据帧,然后根据 VNI 的值,把它交给 Node 2 上的 flannel.1 设备。
而 flannel.1 设备则会进一步拆包,取出“原始 IP 包”。接下来就回到了我在上一篇文章中分享的单机容器网络的处理流程。最终,IP 包就进入到了 container-2 容器的 Network Namespace 里。
以上,就是 Flannel VXLAN 模式的具体工作原理了。
Host-gw
它的工作原理非常简单,我用一张图就可以和你说清楚。为了方便叙述,接下来我会称这张图为“host-gw 示意图”。

图 1 Flannel host-gw 示意图
假设现在,Node 1 上的 Infra-container-1,要访问 Node 2 上的 Infra-container-2。
当你设置 Flannel 使用 host-gw 模式之后,flanneld 会在宿主机上创建这样一条规则,以 Node 1 为例:
$ ip route
...
10.244.1.0/24 via 10.168.0.3 dev eth0
这条路由规则的含义是:
目的 IP 地址属于 10.244.1.0/24 网段的 IP 包,应该经过本机的 eth0 设备发出去(即:dev eth0);并且,它下一跳地址(next-hop)是 10.168.0.3(即:via 10.168.0.3)。
所谓下一跳地址就是:如果 IP 包从主机 A 发到主机 B,需要经过路由设备 X 的中转。那么 X 的 IP 地址就应该配置为主机 A 的下一跳地址。
而从 host-gw 示意图中我们可以看到,这个下一跳地址对应的,正是我们的目的宿主机 Node 2。
一旦配置了下一跳地址,那么接下来,当 IP 包从网络层进入链路层封装成帧的时候,eth0 设备就会使用下一跳地址对应的 MAC 地址,作为该数据帧的目的 MAC 地址。显然,这个 MAC 地址,正是 Node 2 的 MAC 地址。
这样,这个数据帧就会从 Node 1 通过宿主机的二层网络顺利到达 Node 2 上。
而 Node 2 的内核网络栈从二层数据帧里拿到 IP 包后,会“看到”这个 IP 包的目的 IP 地址是 10.244.1.3,即 Infra-container-2 的 IP 地址。这时候,根据 Node 2 上的路由表,该目的地址会匹配到第二条路由规则(也就是 10.244.1.0 对应的路由规则),从而进入 cni0 网桥,进而进入到 Infra-container-2 当中。
可以看到,host-gw 模式的工作原理,其实就是将每个 Flannel 子网(Flannel Subnet,比如:10.244.1.0/24)的“下一跳”,设置成了该子网对应的宿主机的 IP 地址。
也就是说,这台“主机”(Host)会充当这条容器通信路径里的“网关”(Gateway)。这也正是“host-gw”的含义。
当然,Flannel 子网和主机的信息,都是保存在 Etcd 当中的。flanneld 只需要 WACTH 这些数据的变化,然后实时更新路由表即可。
注意:在 Kubernetes v1.7 之后,类似 Flannel、Calico 的 CNI 网络插件都是可以直接连接 Kubernetes 的 APIServer 来访问 Etcd 的,无需额外部署 Etcd 给它们使用。
而在这种模式下,容器通信的过程就免除了额外的封包和解包带来的性能损耗。根据实际的测试,host-gw 的性能损失大约在 10% 左右,而其他所有基于 VXLAN“隧道”机制的网络方案,性能损失都在 20%~30% 左右。
当然,通过上面的叙述,你也应该看到,host-gw 模式能够正常工作的核心,就在于 IP 包在封装成帧发送出去的时候,会使用路由表里的“下一跳”来设置目的 MAC 地址。这样,它就会经过二层网络到达目的宿主机。
所以说,Flannel host-gw 模式必须要求集群宿主机之间是二层连通的。
需要注意的是,宿主机之间二层不连通的情况也是广泛存在的。比如,宿主机分布在了不同的子网(VLAN)里。但是,在一个 Kubernetes 集群里,宿主机之间必须可以通过 IP 地址进行通信,也就是说至少是三层可达的。否则的话,你的集群将不满足上一篇文章中提到的宿主机之间 IP 互通的假设(Kubernetes 网络模型)。当然,“三层可达”也可以通过为几个子网设置三层转发来实现。
例子
kubeadm + flannel 安装,默认的flannel是vxlan模式
默认网络划分
--pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12
[root@master01 ~]# kubectl get pod -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-fb8b8dccf-h6cqs 1/1 Running 0 4h52m 10.244.0.2 master01
coredns-fb8b8dccf-kqn4g 1/1 Running 0 4h52m 10.244.0.3 master01
etcd-master01 1/1 Running 0 4h51m 192.168.48.101 master01
kube-apiserver-master01 1/1 Running 0 4h52m 192.168.48.101 master01
kube-controller-manager-master01 1/1 Running 0 4h52m 192.168.48.101 master01
kube-flannel-ds-amd64-gbkfh 1/1 Running 0 4h49m 192.168.48.202 node02
kube-flannel-ds-amd64-j7znj 1/1 Running 0 4h50m 192.168.48.201 node01
kube-flannel-ds-amd64-jjqx9 1/1 Running 0 4h50m 192.168.48.101 master01
kube-proxy-b6x8j 1/1 Running 0 4h50m 192.168.48.201 node01
kube-proxy-c7xlr 1/1 Running 0 4h52m 192.168.48.101 master01
kube-proxy-rkqtk 1/1 Running 0 4h49m 192.168.48.202 node02
kube-scheduler-master01 1/1 Running 0 4h51m 192.168.48.101 master01
flannel 在每台节点上都有专门的隧道接口cni0 ,flannel.1
[root@master01 ~]# ifconfig
cni0: flags=4163 mtu 1450
inet 10.244.0.1 netmask 255.255.255.0 broadcast 0.0.0.0
inet6 fe80::2b:70ff:fe5c:2cee prefixlen 64 scopeid 0x20
ether 02:2b:70:5c:2c:ee txqueuelen 1000 (Ethernet)
RX packets 97927 bytes 6131162 (5.8 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 75081 bytes 22728727 (21.6 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
docker0: flags=4099 mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
ether 02:42:e3:0e:8b:83 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens33: flags=4163 mtu 1500
inet 192.168.48.101 netmask 255.255.255.0 broadcast 192.168.48.255
inet6 fe80::4446:4f12:39dd:db1 prefixlen 64 scopeid 0x20
ether 00:0c:29:31:54:e9 txqueuelen 1000 (Ethernet)
RX packets 891341 bytes 1158757479 (1.0 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 344080 bytes 75342553 (71.8 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
flannel.1: flags=4163 mtu 1450
inet 10.244.0.0 netmask 255.255.255.255 broadcast 0.0.0.0
inet6 fe80::58e1:c1ff:fe11:c810 prefixlen 64 scopeid 0x20
ether 5a:e1:c1:11:c8:10 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 8 overruns 0 carrier 0 collisions 0
lo: flags=73 mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10
loop txqueuelen 1000 (Local Loopback)
RX packets 1843433 bytes 321870936 (306.9 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1843433 bytes 321870936 (306.9 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
veth5837dfb1: flags=4163 mtu 1450
inet6 fe80::860:33ff:fe6a:dd61 prefixlen 64 scopeid 0x20
ether 0a:60:33:6a:dd:61 txqueuelen 0 (Ethernet)
RX packets 60694 bytes 4443145 (4.2 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 37567 bytes 11366174 (10.8 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
veth99f8c9a4: flags=4163 mtu 1450
inet6 fe80::18d2:45ff:feb4:5148 prefixlen 64 scopeid 0x20
ether 1a:d2:45:b4:51:48 txqueuelen 0 (Ethernet)
RX packets 37233 bytes 3058995 (2.9 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 37544 bytes 11364653 (10.8 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
编写2个测试pod
vim demo-pod01.yaml
apiVersion: v1
kind: Pod
metadata:
name: demo-pod01
namespace: default
labels:
app: myapp
type: pod
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
ports:
- name: http
containerPort: 80
vim demo-pod02.yaml
apiVersion: v1
kind: Pod
metadata:
name: demo-pod02
namespace: default
labels:
app: myapp
type: pod
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
ports:
- name: http
containerPort: 80
[root@master01 ~]# kubectl apply -f demo-pod01.yaml
pod/demo-pod01 created
[root@master01 ~]# kubectl apply -f demo-pod02.yaml
pod/demo-pod02 created
[root@master01 ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
demo-pod01 1/1 Running 0 2m19s 10.244.1.2 node01
demo-pod02 1/1 Running 0 3m11s 10.244.2.3 node02
所有节点安装抓包工具,查看节点绑定的网桥
yum -y install bridge-utils
yum -y install tcpdump
[root@node01 ~]# brctl show cni0
bridge name bridge id STP enabled interfaces
cni0 8000.6ab56e9a8272 no veth74476771
[root@node02 ~]# brctl show cni0
bridge name bridge id STP enabled interfaces
cni0 8000.027898e96c3d no veth58583bcc
ping 测试
[root@master01 ~]# kubectl exec -it demo-pod01 -- /bin/sh
/ # ip a
1: lo: mtu 65536 qdisc noqueue state UNKNOWN qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
3: eth0@if6: mtu 1450 qdisc noqueue state UP
link/ether 8e:f6:24:92:97:13 brd ff:ff:ff:ff:ff:ff
inet 10.244.1.2/24 scope global eth0
valid_lft forever preferred_lft forever
/ # ping 10.244.2.3
PING 10.244.2.3 (10.244.2.3): 56 data bytes
64 bytes from 10.244.2.3: seq=0 ttl=62 time=0.781 ms
64 bytes from 10.244.2.3: seq=1 ttl=62 time=0.433 ms
64 bytes from 10.244.2.3: seq=2 ttl=62 time=0.814 ms
64 bytes from 10.244.2.3: seq=3 ttl=62 time=0.497 ms
64 bytes from 10.244.2.3: seq=4 ttl=62 time=0.375 ms
64 bytes from 10.244.2.3: seq=5 ttl=62 time=0.429 ms
64 bytes from 10.244.2.3: seq=6 ttl=62 time=0.441 ms
64 bytes from 10.244.2.3: seq=7 ttl=62 time=0.438 ms
[root@master01 ~]# kubectl exec -it demo-pod02 -- /bin/sh
/ # ip a
1: lo: mtu 65536 qdisc noqueue state UNKNOWN qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
3: eth0@if7: mtu 1450 qdisc noqueue state UP
link/ether 32:84:c7:77:37:e0 brd ff:ff:ff:ff:ff:ff
inet 10.244.2.3/24 scope global eth0
valid_lft forever preferred_lft forever
/ # ping 10.244.1.2
PING 10.244.1.2 (10.244.1.2): 56 data bytes
64 bytes from 10.244.1.2: seq=0 ttl=62 time=0.570 ms
64 bytes from 10.244.1.2: seq=1 ttl=62 time=0.540 ms
64 bytes from 10.244.1.2: seq=2 ttl=62 time=0.341 ms
抓包测试下,node01 -> node02, demo-pod01 ping demo-pod02
[root@master01 ~]# kubectl exec -it demo-pod01 -- /bin/sh
/ # ping 10.244.2.3
PING 10.244.2.3 (10.244.2.3): 56 data bytes
64 bytes from 10.244.2.3: seq=0 ttl=62 time=0.650 ms
64 bytes from 10.244.2.3: seq=1 ttl=62 time=0.444 ms
64 bytes from 10.244.2.3: seq=2 ttl=62 time=0.449 ms
抓取node01 cni0接口
[root@node01 ~]# tcpdump -i cni0 -nn icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on cni0, link-type EN10MB (Ethernet), capture size 262144 bytes
17:52:05.551169 IP 10.244.1.2 > 10.244.2.3: ICMP echo request, id 6400, seq 8, length 64
17:52:05.551508 IP 10.244.2.3 > 10.244.1.2: ICMP echo reply, id 6400, seq 8, length 64
17:52:06.552030 IP 10.244.1.2 > 10.244.2.3: ICMP echo request, id 6400, seq 9, length 64
17:52:06.552626 IP 10.244.2.3 > 10.244.1.2: ICMP echo reply, id 6400, seq 9, length 64
17:52:07.552885 IP 10.244.1.2 > 10.244.2.3: ICMP echo request, id 6400, seq 10, length 64
17:52:07.554106 IP 10.244.2.3 > 10.244.1.2: ICMP echo reply, id 6400, seq 10, length 64
再抓取flannel.1的接口
[root@node01 ~]# tcpdump -i flannel.1 -nn icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on flannel.1, link-type EN10MB (Ethernet), capture size 262144 bytes
17:53:40.020058 IP 10.244.1.2 > 10.244.2.3: ICMP echo request, id 6656, seq 15, length 64
17:53:40.020508 IP 10.244.2.3 > 10.244.1.2: ICMP echo reply, id 6656, seq 15, length 64
17:53:41.020724 IP 10.244.1.2 > 10.244.2.3: ICMP echo request, id 6656, seq 16, length 64
17:53:41.021333 IP 10.244.2.3 > 10.244.1.2: ICMP echo reply, id 6656, seq 16, length 64
17:53:42.021624 IP 10.244.1.2 > 10.244.2.3: ICMP echo request, id 6656, seq 17, length 64
17:53:42.022158 IP 10.244.2.3 > 10.244.1.2: ICMP echo reply, id 6656, seq 17, length 64
17:53:43.022830 IP 10.244.1.2 > 10.244.2.3: ICMP echo request, id 6656, seq 18, length 64
17:53:43.023515 IP 10.244.2.3 > 10.244.1.2: ICMP echo reply, id 6656, seq 18, length 64
最后封装走ens接口,默认走的叠加网络
[root@node01 ~]# tcpdump -i ens33 -nn host 192.168.48.202
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
17:55:46.093597 IP 192.168.48.101.6443 > 192.168.48.202.33868: Flags [P.], seq 3399032508:3399032996, ack 3928462408, win 1432, options [nop,nop,TS val 29446837 ecr 29231170], length 488
17:55:46.093657 IP 192.168.48.202.33868 > 192.168.48.101.6443: Flags [.], ack 488, win 1424, options [nop,nop,TS val 29232216 ecr 29446837], length 0
17:55:46.448220 IP 192.168.48.201.37857 > 192.168.48.202.8472: OTV, flags [I] (0x08), overlay 0, instance 1
IP 10.244.1.2 > 10.244.2.3: ICMP echo request, id 6912, seq 72, length 64
17:55:46.448579 IP 192.168.48.202.39818 > 192.168.48.201.8472: OTV, flags [I] (0x08), overlay 0, instance 1
IP 10.244.2.3 > 10.244.1.2: ICMP echo reply, id 6912, seq 72, length 64
17:55:47.012918 IP 192.168.48.101.6443 > 192.168.48.202.33868: Flags [P.], seq 488:958, ack 1, win 1432, options [nop,nop,TS val 29447756 ecr 29232216], length 470
17:55:47.013087 IP 192.168.48.202.33868 > 192.168.48.101.6443: Flags [.], ack 958, win 1424, options [nop,nop,TS val 29233135 ecr 29447756], length 0
17:55:47.448693 IP 192.168.48.201.37857 > 192.168.48.202.8472: OTV, flags [I] (0x08), overlay 0, instance 1
IP 10.244.1.2 > 10.244.2.3: ICMP echo request, id 6912, seq 73, length 64
17:55:47.448975 IP 192.168.48.202.39818 > 192.168.48.201.8472: OTV, flags [I] (0x08), overlay 0, instance 1
flannel默认走的是叠加网络。开启direct routing 同一网络节点走网卡 不同网络节点走叠加网络
先把原来的flannel网络卸载了
[root@master01 ~]# rm -rf /etc/cni/net.d/*
[root@master01 ~]# wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
--2019-05-01 18:01:49-- https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 151.101.228.133
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|151.101.228.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 12306 (12K) [text/plain]
Saving to: ‘kube-flannel.yml’
100%[===========================================================================================>] 12,306 28.2KB/s in 0.4s
2019-05-01 18:01:53 (28.2 KB/s) - ‘kube-flannel.yml’ saved [12306/12306]
[root@master01 ~]# kubectl delete -f kube-flannel.yml
podsecuritypolicy.extensions "psp.flannel.unprivileged" deleted
clusterrole.rbac.authorization.k8s.io "flannel" deleted
clusterrolebinding.rbac.authorization.k8s.io "flannel" deleted
serviceaccount "flannel" deleted
configmap "kube-flannel-cfg" deleted
daemonset.extensions "kube-flannel-ds-amd64" deleted
daemonset.extensions "kube-flannel-ds-arm64" deleted
daemonset.extensions "kube-flannel-ds-arm" deleted
daemonset.extensions "kube-flannel-ds-ppc64le" deleted
daemonset.extensions "kube-flannel-ds-s390x" deleted
编辑kube-flannel.yml 添加"Directrouting": true
[root@master01 ~]# vim kube-flannel.yml
...
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan",
"Directrouting": true
}
}
...
重新加载flannel
[root@master01 ~]# kubectl apply -f kube-flannel.yml
podsecuritypolicy.extensions/psp.flannel.unprivileged created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.extensions/kube-flannel-ds-amd64 created
daemonset.extensions/kube-flannel-ds-arm64 created
daemonset.extensions/kube-flannel-ds-arm created
daemonset.extensions/kube-flannel-ds-ppc64le created
daemonset.extensions/kube-flannel-ds-s390x created
[root@master01 ~]# kubectl get pod -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-fb8b8dccf-h6cqs 0/1 Running 1 5h49m 10.244.0.5 master01
coredns-fb8b8dccf-kqn4g 0/1 Running 1 5h49m 10.244.0.4 master01
etcd-master01 1/1 Running 2 5h47m 192.168.48.101 master01
kube-apiserver-master01 1/1 Running 2 5h48m 192.168.48.101 master01
kube-controller-manager-master01 1/1 Running 2 5h48m 192.168.48.101 master01
kube-flannel-ds-amd64-4xfz9 1/1 Running 0 6s 192.168.48.202 node02
kube-flannel-ds-amd64-vk2g2 1/1 Running 0 6s 192.168.48.201 node01
kube-flannel-ds-amd64-z7sbs 1/1 Running 0 6s 192.168.48.101 master01
kube-proxy-b6x8j 1/1 Running 1 5h46m 192.168.48.201 node01
kube-proxy-c7xlr 1/1 Running 2 5h49m 192.168.48.101 master01
kube-proxy-rkqtk 1/1 Running 1 5h46m 192.168.48.202 node02
kube-scheduler-master01 1/1 Running 2 5h48m 192.168.48.101 master01
[root@master01 ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
demo-pod01 1/1 Running 1 45m 10.244.1.3 node01
demo-pod02 1/1 Running 1 46m 10.244.2.4 node02
查看路由 发现 10.244.0.0/24 via 192.168.48.101 dev ens33 10.244.2.0/24 via 192.168.48.202 dev ens33
[root@node01 ~]# ip route show
default via 192.168.48.2 dev ens33 proto static metric 100
10.244.0.0/24 via 192.168.48.101 dev ens33
10.244.1.0/24 dev cni0 proto kernel scope link src 10.244.1.1
10.244.2.0/24 via 192.168.48.202 dev ens33
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
192.168.48.0/24 dev ens33 proto kernel scope link src 192.168.48.201 metric 100
ping测试
[root@master01 ~]# kubectl exec demo-pod01 -it -- /bin/sh
/ # ping 10.244.2.4
PING 10.244.2.4 (10.244.2.4): 56 data bytes
64 bytes from 10.244.2.4: seq=0 ttl=62 time=0.849 ms
64 bytes from 10.244.2.4: seq=1 ttl=62 time=0.355 ms
64 bytes from 10.244.2.4: seq=2 ttl=62 time=0.373 ms
64 bytes from 10.244.2.4: seq=3 ttl=62 time=0.408 ms
64 bytes from 10.244.2.4: seq=4 ttl=62 time=0.280 ms
node01 ens接口抓包
[root@node01 ~]# tcpdump -i ens33 -nn icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
18:24:15.577234 IP 10.244.1.3 > 10.244.2.4: ICMP echo request, id 3072, seq 2, length 64
18:24:15.577474 IP 10.244.2.4 > 10.244.1.3: ICMP echo reply, id 3072, seq 2, length 64
18:24:16.577673 IP 10.244.1.3 > 10.244.2.4: ICMP echo request, id 3072, seq 3, length 64
18:24:16.577963 IP 10.244.2.4 > 10.244.1.3: ICMP echo reply, id 3072, seq 3, length 64
18:24:17.578002 IP 10.244.1.3 > 10.244.2.4: ICMP echo request, id 3072, seq 4, length 64
18:24:17.578186 IP 10.244.2.4 > 10.244.1.3: ICMP echo reply, id 3072, seq 4, length 64