近期学习了网络爬虫相关知识,打算将学习知识更新出来,一方面,完善自己的知识体系,另一方面,分享给大家共同学习。
网络爬取流程主要有以下3部分构成:
一、网址处理器,用来提供抓取网址对象
本文目标抓取网页为:https://movie.douban.com/subject_search?start=%22+str(15*(i))+%22&search_text=%E7%83%82%E7%89%87&cat=1002 图1:

在抓取网址对象前,需要对待抓取对象分析,有两种情况(1)静态数据(2)动态数据。静态数据比较容易抓取,可直接通过源代码找到所需要的数据,然后,提取标签内数据即可。动态数据在源代码找不到,是ajax生成的,需要分析ajax请求过程,找到所需要的数据,然后抓取。本文以静态数据获取为研究对象,后期会逐步更新动态数据抓取文章。
找到需要抓取网页后,下面开始:
1.右击“检查”,分析数据形式
右击检查,选择network,点击response(response储存http请求返回的数据),查看里面是否我们所需要的数据,通过查看,确实保存着我们所需数据。图2 ,

可知我们所需要的数据为静态数据。
2.分析网页结构
确定好待抓取数据后,需要分析网页结构,找到数据存储位置。图3 ,
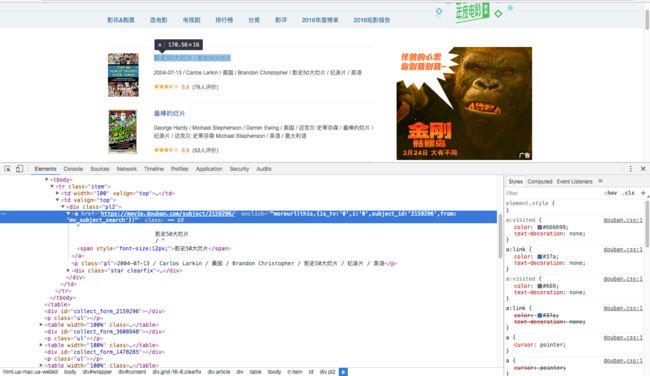
可以看出数据储存在标签内,由于标签没有唯一性(没有办法通过class、id等直接定位所需要的标签),可通过找父节点div(class=pl2),通过class 确定了其唯一性。分析好网页结构后,下一步解析网页找到我们所需要的数据。
3.如何抓取全部数据
抓取全部数据前,需要分析URL结构(有关url知识,可参考:http://kb.cnblogs.com/page/130970/#urlexplain),豆瓣电影烂片第一页:URL:https://movie.douban.com/subject_search?start=0%22+%22&search_text=%E7%83%82%E7%89%87&cat=1002 第二页:https://movie.douban.com/subject_search?start=15&search_text=%E7%83%82%E7%89%87&cat=1002以此类推,get请求方式下,请求参数 start,按照15倍数依次进行,因此,可构建新的模型请求url:https://movie.douban.com/subject_search?start="+str(15*(i))+"&search_text=烂片&cat=1002。
二、网页解析器,用来提取网页中我们所需要的数据
网页解析方面,beautifulsoul功能较强大且应用较广泛(链接:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html)。上文确定了需要抓取的标签,可以用find_all方法抓取所需要标签数据,抓取结果返回一个list。图4

确定好list后,下一步需要分析list,list[0],list[1],list[2]....等都是一条条div,下一步就是分析div,其实把div也可以当成一个list,发现需要抓取的数据在div-list第二个数值,也就是div-list[1],确定好需要抓取的数据后,最后写一个for循环,遍历一下。
三、存储数据
通过遍历出所需要的数据后,下一步就是存储数据,由于数据近4000条,数据量较少,本文采取txt文本存储。在存储数据时,本文建议用with open() as f: f.write( )形式存储,可以保证数据不会丢失。此外,在open( )时,python2和python 3不同,python 3需要在加上enconding="utf-8"编码,python2 不需要,一般在write( ) 加上encode("utf-8")
以上书数据抓取-解析-存储流程过程。具体见源代码:
#!/usr/bin/python
# -*- coding: utf-8-*-
importrequests;
frombs4importBeautifulSoup;
# 获取待解析的网页
foriinrange(0,1):
url ="https://movie.douban.com/subject_search?start="+str(15*(i))+"&search_text=烂片&cat=1002"
response = requests.get(url).text
# 解析网页,找出需要的数据
bsobject = BeautifulSoup(response,"html.parser");
re = bsobject.find_all("div",class_="pl2");
printre;
foriinre:
j = i.contents[1].text.strip("\n").replace(" ","") +"\n"
withopen("a.txt","a+")asf:
f.write(j.encode("utf-8"))
注:近期51python社区博客网站即将上线,会分享python、PHP、mysql等方面的知识,4月中旬,产品类、运营类相关公众号也即将上线,欢迎关注。
END
如果,您喜欢我的文章或者有什么疑问,都可以加我微信:15005417866,也可以关注我
