Cgroup分析之cpu、cpuacct
1 组调度
1.1 进程调度基础
操作系统为了协调多个进程的同时运行,最基本的手段就是给进程设定优先级,如果有多个进程处于可执行状态,那么优先级高的进程先被调度执行。
Linux内核将进程分为两种级别,普通进程和实时进程,实时进程的优先级高于普通进程,另外他们的调度策略也不同。
实时进程的调度
1、如果一个进程是实时进程,只要它是可执行状态的,内核就一直让它执行,以尽可能满足它对cpu的需要,直到进程执行完成,睡眠或退出(不可执行状态)。
2、如果有多个进程一直处于可执行状态,则内核会先满足优先级最高的实时进程对cpu的需求,直到这个进程执行完成变成非可执行状态。
这样,如果高优先级的实时进程一直处于可执行状态,低优先级的实时进程就一直不能得到cpu;只要一直有实时进程处于可执行状态,普通进程就一直不能得到cpu。明显不能达到多任务的效果。
所以内核中通过/proc/sys/kernel/sched_rt_runtime_us和/proc/sys/kernel/sched_rt_period_us两个参数来控制在sched_rt_period_us为周期的时间内,实时进程最多只能运行sched_rt_runtime_us这么多时间,这样留给普通进程一定的运行时间。
3、如果有多个相同优先级的实时进程处于可执行状态,有两种调度策略可以选择
SCHED_FIFO:先进先出。直到先被执行的进程变为非可执行状态,后来的进程才被调度执行。在这种策略下,先来的进程可以执行sched_yield系统调用,自愿放弃CPU,以让权给后来的进程;
SCHED_RR:轮转调度。内核为实时进程分配时间片,在时间片用完时,让下一个进程使用CPU;
实时进程的调度是比较简单的,进程的优先级和调度策略都由用户设定,内核总是选择优先级最高的实时进程来调度执行。在选择具有相同优先级的实时进程时,要考虑两种调度策略。
普通进程的调度
普通进程没有实时的需求,调度器力图让每个处于可执行状态的进程平分cpu时间,从而让用户认为这些进程是同时进行的。
普通进程的调度中,内核要关注动态调整进程的优先级和进程调度的公平性两方面。
1、动态调整优先级
进程按照行为可以分为交互式进程和批处理进程,交互式进程较批处理进程有较高的优先级。但系统正常运行场景下,用户并不会完全设置交互式进程和批处理进程的优先级。于是内核中通过调度程序来区分这些进程的优先级,调度程序关注进程近一段时间内的表现(主要是检查其睡眠时间和运行时间),根据一些经验性的公式,判断它现在是交互式的还是批处理的?程度如何?最后决定给它的优先级做一定的调整。
进程的优先级被动态调整后,就出现了两个优先级:
1)、用户程序设置的优先级(如果未设置,则使用默认值),称为静态优先级。这是进程优先级的基准,在进程执行的过程中往往是不改变的;
2)、优先级动态调整后,实际生效的优先级。这个值是可能时时刻刻都在变化的;
2、调度公平性
在支持多进程的系统中,理想情况下,各个进程应该是根据其优先级公平地占有CPU。而不会出现“谁运气好谁占得多”这样的不可控的情况。
linux实现公平调度基本上是两种思路:
1)、给处于可执行状态的进程分配时间片(按照优先级),用完时间片的进程被放到“过期队列”中。等可执行状态的进程都过期了,再重新分配时间片;
2)、动态调整进程的优先级。随着进程在CPU上运行,其优先级被不断调低,以便其他优先级较低的进程得到运行机会;
后一种方式有更小的调度粒度,并且将“公平性”与“动态调整优先级”两件事情合而为一,大大简化了内核调度程序的代码。
1.2 相关数据结构
总体关联图

1、 rq
每个cpu(一个核)对应一个全局变量per cpu runqueues,其数据结构是struct rq,该变量为调度的最顶层的数据结构。在该数据结构中包含了structcfs_rq cfs,cfs就是该cpu上cfs调度的顶级结构,或者说是调度的入口点。同时该数据结构中也包含了struct rt_rq rt,作为实时进程调度的顶级结构。
rq的定义如下:
![]()
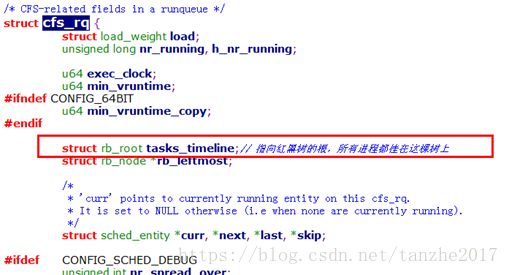
2、 cfs_rq
struct cfs_rq中存放的运行队列中rq中cfs相关的一些字段值,是该cpu上cfs调度的入口点。
cfs_rq中的struct rb_root tasks_timeline指向红黑树的根,所有进程都挂在这棵红黑树上。
3、 sched_entity
调度的对象包括进程(task)和进程组(task_group)两种,所以需要一个抽象的结构来表示他们,调度实体sched_entity就是用来表示他们的。这个调度实体可以是一个进程,也可以是组调度中的一个组。
调度实体结构中的structrb_node run_node指向红黑树上的一个节点,表示当前调度实体在红黑树上的位置。调度实体通过该节点挂到红黑树上,在选择需要调度的进程时,内核将搜索这个红黑树,找到虚拟运行时间小的进程,并把该进程从树上摘下,同时会把切换出的长时间运行的进程重新挂到红黑树上。
结构如下:
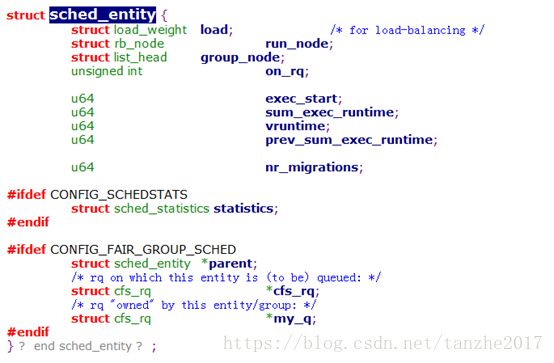
如果这个调度实体表示一个组,则实体中的struct cfs_rq *cfs_rq指向调度这个实体的cpu上的cfs_rq,而struct cfs_rq *my_q指向task_group中与这个实体所对应的cfs_rq。
如果调度实体只表示一个进程,其cfs_rq也指向调度该实体的cpu上的cfs_rq,但其my_q则为null。
4、 task_group
task_group是组调度中关键的一个结构,用来控制管理组调度的组,所有的task_group组成一个树状结构。
一个task_group中可以包含具有任意调度类别的进程(具体的说包括实时进程和普通进程),所以task_group中需要为每一种调度策略提供一组调度结构,这样的调度结构包括两部分,调度实体和运行队列,这两个都是每cpu一份的。调度实体会被添加到运行队列中,对于一个task_group,它的调度实体会被添加到其父task_group的运行队列。
task_group中的struct sched_entity **se是这个组中在所有cpu上存在的调度实体的指针数组,如果这个组中在某个cpu上有可运行的进程,则组在该cpu上的调度实体就会挂到该cpu的cfs_rq的红黑树上。
与**se对应的是struct cfs_rq **cfs_rq,这是与每个调度实体se对应的cfs_rq,通过se中的my_q就可以找到这个cfs_rq。这个cfs_rq中的tasks_timeline同样指向一个该调度队列的红黑树的root节点。
结构如下:

1.3 组调度策略
组调度策略根据具体的调度类别不同而不同。具体的说就是rt(实时调度)和cfs(完全公平调度)两种类别。
1.3.1 普通进程的组调度
普通进程的组调度没有那么复杂。进程组被看作是跟进程几乎完全相同的实体,它拥有自己的静态优先级、调度程序也动态地调整它的优先级。对于一个组来说,组内进程的优先级并不影响组的优先级,只有这个组被调度程序选中时,这些进程的优先级才被考虑。
为了设置组的优先级,每个task_group都有一个shares参数(跟前面提到的sched_rt_runtime_us和sched_rt_period_us两个参数并列)。shares并不是优先级,而是调度实体的权重,这个权重和优先级是有一一对应的关系的。普通进程的优先级也会被转换成其对应调度实体的权重,所以可以说shares就代表了优先级。
shares的默认值跟普通进程默认优先级对应的权重是一样的。所以在默认情况下,组和进程是平分CPU的。
1.3.2 实时进程的组调度
实时进程是对CPU有着实时性要求的进程,它的优先级是跟具体任务相关的,完全由用户来定义。调度器总是选择优先级最高的实时进程来运行。
在组调度中,组的优先级被定义为组内最高优先级的进程所拥有的优先级。
Linux系统中通过两个proc文件:/proc/sys/kernel/sched_rt_period_us和/proc/sys/kernel/sched_rt_runtime_us来规定在以sched_rt_period_us为一个周期的时间内,所有实时进程的运行时间之和不超过sched_rt_runtime_us。这两个文件的默认值是1s和0.95s,表示每秒种为一个周期,在这个周期中,所有实时进程运行的总时间不超过0.95秒,剩下的至少0.05秒会留给普通进程。也就是说,实时进程占有不超过95%的CPU。而在这两个文件出现之前,实时进程的运行时间是没有限制的,如果一直有处于TASK_RUNNING状态的实时进程,则普通进程会一直不能得到运行。相当于sched_rt_runtime_us等于sched_rt_period_us。
在实时进程的组调度中,就将这两个文件的概念扩展了,每个task_group都有自己的sched_rt_runtime_us和sched_rt_period_us,保证自己组内的进程在以sched_rt_period_us为周期的时间内,最多只能运行sched_rt_runtime_us这么多时间。CPU占有比为sched_rt_runtime_us/sched_rt_period_us。每一个task_group的rt_runtime_us和rt_period_us通过cpu子系统的cpu.rt_period_us和cpu. rt_runtime_us来设定和修改。
对于根节点的task_group,它的sched_rt_runtime_us和sched_rt_period_us就等于上面两个proc文件中的值。而对于一个task_group节点来说,假设它下面有n个调度子组和m个TASK_RUNNING状态的进程,它的CPU占有比为A、这n个子组的CPU占有比为B,则B必须小于等于A,而A-B剩下的CPU时间将分给那m个TASK_RUNNING状态的进程。(这里讨论的是CPU占有比,因为每个调度组可能有着不同的周期值。)
为了实现sched_rt_runtime_us和sched_rt_period_us的逻辑,内核在更新进程的运行时间的时候(比如由周期性的时钟中断触发的时间更新)会给当前进程的调度实体及其所有祖先节点都增加相应的runtime。如果一个调度实体达到了sched_rt_runtime_us所限定的时间,则将其从对应的运行队列中剔除,并将对应的rt_rq置throttled状态。在这个状态下,这个rt_rq对应的调度实体不会再次进入运行队列。而每个rt_rq都会维护一个周期性的定时器,定时周期为sched_rt_period_us。每次定时器触发,其对应的回调函数就会将rt_rq的runtime减去一个sched_rt_period_us单位的值(但要保持runtime不小于0),然后将rt_rq从throttled状态中恢复回来。
1.4 带宽控制
Cgroup提供cpu子系统实现对普通进程调度的CPU带宽控制,可以设置。
可以通过给一个group来设定quota和period来设定带宽。表示在给定的period(以微秒计)的时间周期内,允许这个group最多能占用多少quota(微秒)的的cpu时间。
当这个group占用的cpu带宽到达限制时,这个group中的进程在下一个周期到来前将不再被执行。
通过cgroup文件系统中的cpu.cfs_period_us和cpu.cfs_quota_us设定了period和quota后,内核会读取这两个文件的值,然后将值赋给cfs_bandwidth结构体实例的quota和period两个字段。组调度的task_group结构体中包含当前group的带宽控制结构体struct cfs_bandwidthcfs_bandwidth。这样,每一个task_group就能找到其对应的period和quota的限制值。这个带宽是一个全局的值,每task_group一个,限制当前task_group。
本地的bandwidth按每个cfs_rq来跟踪,表示从每一个task_group的带宽中已分配到的带宽。
2 Cpu子系统
2.1 简介
Linux内核实现了control group功能,支持将进程分组,然后按组来划分各种资源,这些资源包括cpu、memory、IO。
Cpu子系统主要使用调度程序为cgroup任务提供cpu的访问,用来控制进程和进程组使用cpu资源。
对进程组和进程的控制通过组调度来实现。
2.2 用户态接口
Cpu子系统可以通过以下的用户态接口文件来实现对cpu资源访问的控制,每个文件都独立存在在cgroup虚拟文件系统的伪文件中。
Cfs带宽控制参数
cpu.cfs_period_us
以微秒为单位指定一个period的长度。
cpu.cfs_quota_us
以微秒为单位指定一个period中可用运行时间。
cpu.stat
当前nr_periods、nr_throttled、throttled_time的状态值。
nr_periods:已执行完的period数。
nr_throttled:当前cgroup中所有进程超过限制值的次数。
throttled_time:当前cgroup中所有进程超过限制值的持续时间。
普通组调度参数
cpu.shares
包含用来指定在cgroup中的任务可用的相对共享cpu时间的整数值。
例如:在两个cgroup中都将cpu.shares设定为1的任务将有相同的cpu时间,但在cgroup中将cpu.shares设定为2的任务可使用的cpu时间是在cgroup中将cpu.shares设定为1的任务可使用的cpu时间的两倍。
Rt组调度参数
cpu.rt_period_us
以微秒(μs,这里以"us"代表)为单位指定在某个时间段中cgroup对cpu资源访问重新分配的频率。如果某个cgroup中的任务应该每5秒钟有4秒时间可访问cpu资源,则请将cpu.rt_runtime_us设定为4000000,并将cpu.rt_period_us设定为5000000。
cpu.rt_runtime_us
以微秒(μs,这里以"us"代表)为单位指定在某个时间段中cgroup中的任务对cpu资源的最长连续访问时间。建立这个限制是为了防止一个cgroup中的任务独占cpu时间。如果cgroup中的任务应该可以每5秒中可有4秒时间访问cpu资源,请将cpu.rt_runtime_us设定为4000000,并将cpu.rt_period_us设定为5000000。
3 Cpuacct子系统
3.1 简介
Cpuacct主要是根据内核现有的一些接口对cpu使用状况做统计,并自动生成cgroup中进程所使用的CPU资源报告,实现比较简单。
3.2 用户态接口
Cpuacct子系统生成cgroup中任务所使用的资源报告,包括子组中的资源使用情况。
三个文件为:
Cpuacct.stat
报告当前cgroup和子组的所有任务使用用户模式和系统模式消耗的CPU周期数(单位由系统中user_hz定义)。
Cpuacct.usage
统计这个cgroup中所有任务消耗的总cpu时间(纳秒)。
Cpuacct.usage_percpu
统计这个cgroup中所有任务在每一个cpu上分别消耗的cpu时间(纳秒)。
3.3 主要实现
我们先看下cpuacct子系统中用到的主要数据结构;
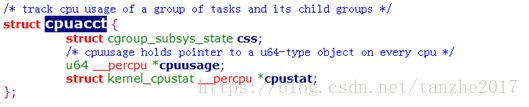
结构体内容很简单,包括一个css结构,用来和cgroup关联。一个cpuusage指针,执行一个u64类型的percpu对象。以及一个kernel_cpustat 类型的percpu cpustat数组。这个kernel_cpustat数组用来存放子系统需要统计的cpu相关数据,定义如下:

这个kernel_cpustat中的信息的统计是内核中已有的功能,这里直接使用这些信息。
1、stat
子系统定义了cpuacct_stats_show函数,实现对cpu周期数的统计。
代码如下:

在当前cgroup下,遍历每个cpu通过定义一个per_cpu的kernel_cpustat对象kcpustat,直接读取数组中的CPUTIME_USER和CPUTIME_NICE之和作为cpu.stat中user的时间值。(CPUTIME_USER:cpu运行用户进程的时间,CPUTIME_NICE:cpu花费在被nice改变过优先级的进程的时间)。
同样的,通过统计CPUTIME_SYSTEM、CPUTIME_IRQ和CPUTIME_SOFTIRQ之和作为cpu.stat中systerm的时间值。
(CPUTIME_SYSTEM:cpu执行kernel的时间,CPUTIME_IRQ:cpu花费在硬中断的时间,CPUTIME_SOFTIRQ:cpu花费在软中断的时间)
2、usage
Usage的信息存放在cpuacct结构体中的cpuusage字段中,文件显示信息就是通过从每cpu中读取cpuusage求总和得到的。数据获取和显示类似上面stat的过程。
每个进程执行时,在update_curr中都会调用cpuacct子系统的cpuacct_charge函数将每个进程的执行时间统计到cpuacct子系统中,这样每个group的cpuacct中就包含了其所有进程使用cpu的使用统计。
cpuacct_charge函数的实现如下:

通过获取当前的进程所在cpu,定义一个当前对应当前cpu的cpuusage,并找到进程对应的cgroup的cpuacct,将cputime添加到其cpuusage中。
3、usage_percpu
Percpu的usage报告直接通过cpuacct_cpuusage_read读到每cpu的usage,并打印。其过程类似上面的usage,只不过这里是按照cpu单独报告,上面的是将每cpu的数据加在一起报告。