【大数据平台技术(二)】—— 使用Docker搭建Hadoop分布式集群
使用Docker搭建Hadoop分布式集群
背景
搭建Hadoop分布式集群通常容易想到的两种方法如下:
(1) 采用多太机器构建分布式集群;
(2) 在一台机器上安装多个虚拟机,每个虚拟机上运行一个Hadoop节点。
但是,上述两种方式都有缺点。如果采用第一种方法,通常需要多台机器,对于很多大数据学习者而言,通常难以找到多台机器用于构建分布式实验环境;如果采用第二种方法,通常对于单台机器的配置要求很高,否则在一台机器上同时运行多个虚拟机会非常卡且非常慢。
而随着虚拟化技术的发展,尤其是Docker容器技术的诞生,使得人们有了第3种搭建Hadoop分布式集群的方法——使用Docker搭建Hadoop分布式集群。
一、安装Docker
安装Docker之前,必须首先保证机器上安装的是64位Linux系统;其次,内核版本必须大于3.10。可以用如下命令来检测机器上以及安装好了的Ubuntu系统的内核版本:
uname –r
效果如下:

然后需要先更新apt,安装CA证书,因为访问Docker使用的是HTTPS协议,命令如下:
sudo apt-get update
sudo apt-get install apt-transport-https ca-certificates
接着执行如下命令添加新的GPG key
sudo apt-key adv \ --keyserver hkp://ha.pool.sks-keyservers.net:80 \ --recv-keys 58118E89F3A912897C070ADBF76221572C52609D
执行效果如下: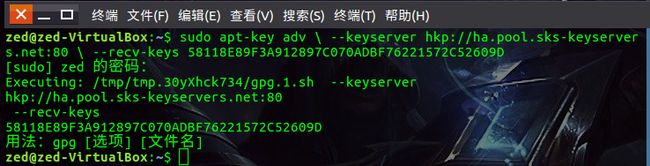
执行如下命令位Ubuntu系统添加Docker安装源(也就是可以获得Docker安装包的地方):
echo deb https://apt.dockerproject.org/repo ubuntu-xenial main | sudo tee /etc/apt/sources.list.d/docker.list
效果如下:

接着可以用如下命令验证一下是否正确地从仓库拉取到了安装包:
apt-cache policy docker-engine
如果有类似于下面的输出,则说明从仓库中正确地获取到了包:

接下来可以直接安装Docker,命令如下:
sudo apt-get install docker-engine
当这个安装过程结束后,即表示Docker安装完成,可以通过如下命令开启Docker服务:
sudo service docker start
然后可以运行Docker官方提供的hello-world程序来检测Docker是否能够顺利运行程序:
sudo docker run hello-world
这一部分的过程如下:
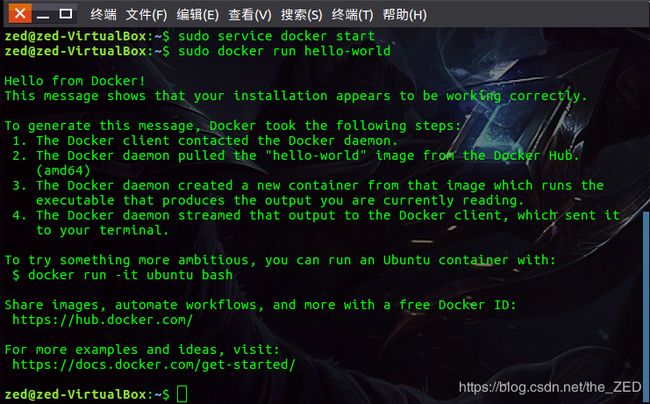
若能出现这些信息,即表示安装完成。
对于Docker而言,默认情况下只有root用户才能执行Docker命令,因此,还需要添加用户权限。首先需要使用如下命令创建Docker用户组:
sudo groupadd docker
然后添加当前用户(zed)到Docker用户组,命令如下:
sudo usermod -aG docker zed
二、在Docker上安装Ubuntu系统
在安装好Docker之后,接下来就要在Docker上安装Ubuntu。可以直接从Docker上下载Ubuntu镜像文件,命令如下:
docker pull ubuntu
docker pull命令表示从Docker hub上拉取Ubuntu镜像到本地。执行该命令以后,可以再执行下面的命令看是否安装成功:
docker images
该命令表示列出Docker上所有的镜像。镜像也是一堆文件,如果输出类似如下信息则表示安装成功:

然后需要在Docker上开启Ubuntu系统,也就是启动Ubuntu镜像。在启动Ubuntu镜像之前,需要先在当前登陆用户的用户目录下创建一个子目录,用于向Docker内部的Ubuntu系统传输文件,这时候需要在本地Ubuntu系统(不是Docker中的Ubuntu系统)中执行如下命令:
mkdir ~/build
现在就可以在Docker上启动运行Ubuntu系统了,在本地Ubuntu系统中执行如下命令:
docker run -it -v /home/zed/build:/root/build --name ubuntu ubuntu
此命令的含义如下:
① docker run表示运行一个镜像文件
② -i表示开启交互模式;-t表示分配一个tty(可以理解为一个控制台);因此-it可以理解为在当前终端上与Docker内部的Ubuntu系统进行交互。
③ -v表示Docker内部的Ubuntu系统中的/root/build目录与本地的/home/zed/build目录共享,这样就可以很方便地将本地文件上传到Docker内部的Ubuntu系统中。
④ --name ubuntu表示镜像启动名称,如果没有指定,那么Docker将会随机分配一个名字。
⑤ 最后的ubuntu表示docker run启动的镜像文件。
当此命令执行成功时,会出现以下界面:

三、Docker中Ubuntu系统的初始化
刚安装好的Ubuntu系统是一个纯净的系统,很多软件是没有安装的,所以需要先更新一下Ubuntu系统的软件源并安装一些必备的软件。
(1)更新系统软件源
apt-get update
(2)安装vim编辑器
apt-get install vim
(3)安装和配置sshd
因为在开启分布式Hadoop时,需要用到SSH连接Slave机器,在Docker上的Ubuntu系统中执行如下命令:
apt-get install ssh
然后在Docker上的Ubuntu系统中运行如下脚本即可开启sshd服务器:
/etc/init.d/ssh start
但是这样在每次启动镜像的时候,都需要手动开启sshd服务,因此可以把启动命令写进bashrc文件,从而在每次登陆Ubuntu系统时,都能自动启动sshd服务。用vim编辑器打开~/.bashrc文件,在该文件的最后一行添加如下内容:
/etc/init.d/ssh start
安装好ssh之后,需要配置SSH无密码连接本地sshd服务,在Docker上的Ubuntu系统中执行如下命令:
ssh-keygen -t rsa #一直按Enter键即可
cd ~/.ssh
cat id_rsa.pub >> authorized_keys
执行完上述命令之后,即可无密码访问本地sshd服务了。
(4)安装java
因为Hadoop需要使用Java环境,因此,需要安装JDK。可以在Docker上的Ubuntu系统中直接输入以下命令来安装JDK:
apt-get install default-jdk
这个命令会安装较多的库,需要消耗较长时间。等到这个命令运行结束之后,JDK安装就顺利完成了。然后,需要配置环境变量,打开~/.bashrc文件,在文件的最开始位置增加如下内容:
export JAVA_HOME=/usr
export PATH=$PATH:$JAVA_HOME/bin
接着在Docker上的Ubuntu系统中执行以下命令使~/.bashrc配置文件立即生效:
source ~/.bashrc
(5)保存镜像文件。
在Docker内部对容器的修改是不会自动保存到镜像中的,也就是说,上面尽管对容器进行了大量配置,但是一旦把容器关闭,然后重新开启容器,之前的全部设置都将全部消失。因此需要保存当前的容器配置。
为了达到复用容器的配置信息,在每个步骤完成之后,都应该保存成一个新的镜像,首先需要到Docker官网(http://hub.docker.com/)注册一个账号,账号注册成功后,在本地Ubuntu系统(而不是Docker中的Ubuntu系统)中新建一个账号,输入如下命令:
docker login
然后会有下面的提示信息,输入你在注册时的用户名和密码即可:
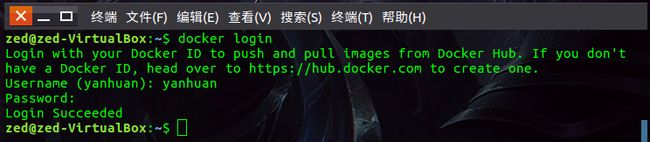
登陆之后,首先在本地的Ubuntu系统中使用如下命令查看当前运行的容器的信息:
docker ps
输出结果如下:

从上面的结果信息可以看出,当前运行的Ubuntu镜像的ID是44a215d5c68b。然后在本地Ubuntu系统中输入以下指令,把修改后的容器保存成为一个新的镜像,新镜像的名称是ubuntu/jdkinstalled,表示该镜像中以及包含了JDK:
docker commit 44a215d5c68b ubuntu/jdkinstalled
其中,docker commit后面的44a215d5c68b是当前运行Ubuntu镜像的ID。输出结果如下:

最后在本地Ubuntu系统的另一个终端中使用如下命令查看所有镜像,确认新的镜像是否保存成功:
docker images
输出结果如下:

从上面输出结果可以看出,目前系统中已经有两个镜像:一个是ubuntu镜像;另一个是刚才新建的镜像ubuntu/jdkinstalled。
四、安装Hadoop
下面开始安装Hadoop。需要首先在本地Ubuntu系统中启动之前保存的镜像ubuntu/jdkinstalled,命令如下:
docker run -it -v /home/zed/build:/root/build --name ubuntu-jdkinstalled ubuntu/jdkinstalled
效果如下:

可以在本地Ubuntu系统中的另一个终端中使用如下命令查看启动的容器:
docker ps
输出结果如下:

启动容器之后,在这个容器中就运行了Ubuntu系统(包含JDK)。我们需要先下载一个Hadoop安装文件,然后把这个安装文件放到本地Ubuntu系统的共享目录/home/zed/build下面;然后在Docker内部Ubuntu系统的/root/build目录即可获取到该Hadoop安装文件。
实际上,在Docker内部的Ubuntu系统上安装Hadoop的过程和之前介绍的单机模式安装Hadoop是一样的,在此就不再赘述。
五、配置Hadoop集群
这个配置过程其实就是一个修改配置文件的过程,下面给出需要修改的文件列表:
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
- yarn-site.xml
如下图:

下面给出具体的修改过程:
首先是修改hadoop-env.sh配置文件,先输入以下指令:
cd /usr/local/hadoop
接着用vim打开该文件(vim etc/hadoop/hadoop-env.sh),然后在该文件的最前面增加如下内容:
export JAVA_HOME=/usr
如下:

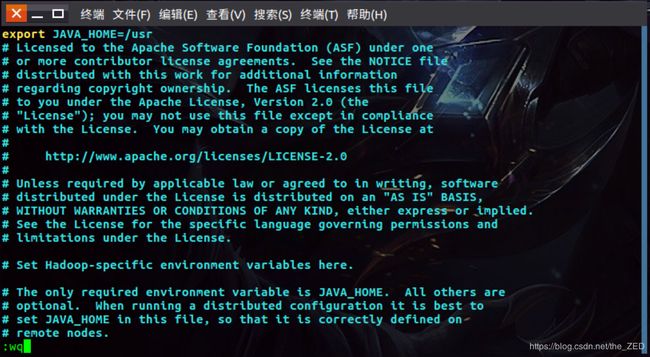
然后退出并保持,如上图所示。
类似的,修改core-site.xml文件,在其中输入以下内容:
hadoop.tmp.dir</name>
file:/usr/local/hadoop/tmp</value>
</property>
fs.defaultFS</name>
hdfs://master:9000</value>
</property>
</configuration>
如下图所示:

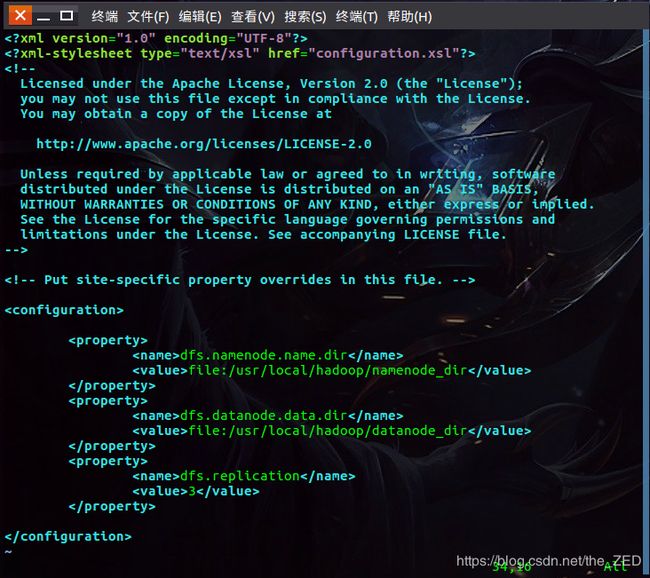
修改hdfs-site.xml文件,在其中输入以下内容:
dfs.namenode.name.dir</name>
file:/usr/local/hadoop/namenode_dir</value>
</property>
dfs.datanode.data.dir</name>
file:/usr/local/hadoop/datanode_dir</value>
</property>
dfs.replication</name>
3</value>
</property>
</configuration>
如下图所示:
然后是修改mapred-site.xml文件,在其中输入以下内容:
mapreduce.framework.name</name>
yarn</value>
</property>
</configuration>

最后是修改yarn-site.xml文件,在其中输入以下内容:
<!-- Site specific YARN configuration properties -->
yarn.nodemanager.aux-services</name>
mapreduce_shuffle</value>
</property>
yarn.resourcemanager.hostname</name>
master</value>
</property>
</configuration>
如下图所示:

至此,Hadoop集群配置顺利结束(建议在这里也将这个镜像保存下来,并命名为ubuntu/hadoopinstalled)。
接下来在本地Ubuntu系统中(不是Docker内部的Ubuntu系统)打开3个终端窗口,每个终端上分别启动一个容器运行ubuntu/hadoopinstalled镜像。分别表示Hadoop集群中的Master、Slave01和Slave02:
在第一个终端中执行以下命令:
docker run -it -h master --name master ubuntu/hadoopinstalled
在第二个终端中执行以下命令:
docker run -it -h master --name slaver01 ubuntu/hadoopinstalled
在第三个终端中执行以下命令
docker run -it -h master --name slaver02 ubuntu/hadoopinstalled
如下:
接着需要配置Master、Slave01和Slave02的地址信息,使得它们可以找到彼此。在三个终端中分别打开/etc/hosts文件,可以查看本机的IP和主机名信息,如下:
最后得到三个IP和主机地址信息如下:
172.18.0.2 Master
172.18.0.3 Slaver01
172.18.0.4 Slaver02
最后把上述三个地址信息分别复制到Master、Slave01和Slave02的/etc/hosts文件中,也就是复制到各自Docker容器内部的Ubuntu系统的/etc/hosts文件中。如下:
然后,可以在作为Master节点的Docker容器内部的Ubuntu系统的终端中,使用如下命令来检测一下Master是否可以成功连上Slave01和Slave02:
ssh slave01
ssh slave02
最后还需要打开Master节点上的slaves文件,输入两个Slave节点的主机名。步骤如下:到文件存放的指定位置并打开该文件:
cd /usr/local/hadoop
vim etc/hadoop/slaves
执行上面的指令后便打开了slaves文件,接下来需要修改该文件的配置,把文件中的localhost替换成两个Slave节点的主机名,分别存放在两行上,最终使得该文件的内容如下:
slave01
slave02
至此,Hadoop集群已经配置完成,现在可以启动集群,在Master节点的终端中执行以下命令:
cd /usr/local/hadoop
bin/hdfs namenode -format
sbin/start-all.sh
这时Hadoop集群就已经启动,可以在Master、Slave01和Slave02这三个节点上分别执行命令jps查看运行结果,如下图所示:
如果能得到类似上述的结果则说明启动集群成功。
六、运行Hadoop程序实例
至此我们已经采用容器的方式成功启动了Hadoop分布式集群,接下来可以利用Hadoop自带的grep实例进行测试。因为要用到HDFS,所以,需要先在HDFS上创建一个目录,在Master节点的终端中执行如下命令:
cd /usr/local/hadoop
./bin/hdfs dfs -mkdir -p /user/hadoop/input
然后将/usr/local/hadoop/etc/hadoop目录下的所有文件复制到HDFS中,需要在Master节点的终端中继续执行如下命令:
./sbin/hdfs dfs -put ./etc/hadoop/*.xml /user/hadoop/input
然后通过ls命令查看下是否正确将文件上传到HDFS,需要在Master节点的终端里继续执行如下命令:
./bin/hdfs dfs -ls /user/hadoop/input
输出结果如下:

如果能得到类似上述的结果则说明在Hadoop分布式集群中顺利执行了grep程序。