- Abstract
- Introduction
- 2 Programming Model
- 2.1 Example
- 2.2 Types
- 2.3 More Examples
- 3 Implementation
- 3.1 Execution Overview
- 3.2 Master Data Structures
- 3.3 Fault Tolerance
- Worker Failure (工作节点故障)
- Master Failure(主节点故障)
- Semantics in the Presence of Failures(语义可能存在的故障)
- 3.4 Locality
- 3.5 Task Granularity
- 3.6 Backup Tasks
- 4 Refinements
- 4.1 Partitioning Function
- 4.2 Ordering Guarantees
- 4.3 Combiner Function
- 4.4 Input and Output Types
- 4.5 Side-effects
- 4.6 Skipping Bad Records
- 4.7 Local Execution
- 4.8 Status Information
- 4.9 Counters
- Others
Abstract
MapReduce :
- programming model 编程模型
- an associated implementation for processing and generating large data sets.
用户只需要指定 Map(Map函数将 key/value 类型的 pair 生成中间结果的 pair) 和 Reduce 函数(Reduce 函数将所有具有相同中间结果的值组合起来)即可。
MapReduce 封装隐藏了分布式系统并行计算的细节:
- 输入数据的分割
- 计划将程序分配到一组计算机中
- 处理机器故障
- 管理集群内部的通信
程序(in functional style)分布式的运行在大型分布式的集群上,而且具有很好的可伸缩性 scalable。
Introduction
过去这些年,Google一直在寻找方法来实现处理大量数据(抓取到的文件,web日志等)的方法,通常数据量很大而且必须分散在数以千计的电脑上来进行运算。为了处理如何使计算相互关联,分配数据以及处理故障的问题,往往编写大量的复杂代码掩盖了他们,最初的简单计算的初衷却被忽略掉。
为了解决这种复杂性,抽象出了一个简单的计算模型放到一个库中,这个库隐藏了可能出现的问题:
- 并行计算
- 容错
- 数据分发
- 负载均衡
这个抽象受到了 Lisp 以及很多函数式编程语言中存在的原语 map和 reduce 的启发。
大多数并行计算都包含两个步骤:
- map:将每个逻辑记录变成
key/value的中间形式方便计算 - reduce:将所有具有相同
key的值组合到一起来进行合适的处理
我们使用一个函数式的编程模型(functional programming model)可以让处理大型的并行计算和使用重新执行作为容错的主要机制变得很简单。
这项工作的主要贡献是:提供了一个简单但是很强大的接口(interface)让自动化的并行计算和大规模计算的分发成为可能,结合该接口的实现,可以在商用机的大型集群上实现高性能。
Section2 :描述了基本的编程模型给出几个例子
Section3 :描述MapReduce 接口针对集群运算环境的实现
Section4 :一些针对该模型的细微的改良
Section5 :针对实现设计出一系列性能衡量方法
Section6 :MapReduce 在 Google 中的使用,以及使用 MapReduce 来重写生产环境的索引系统
Section7 :相关以及未来的工作
2 Programming Model
input: a set of key/value pairs
output: a set of key/value pairs
MapReduce 的用户将只会使用两个函数 Map 和 Reduce。
Map:用户编写,将输入的 pair 变成 k/v 的中间 pairs,然后 MapReduce 会把具有相同 key 的 pair 送给 Reduce 函数
Reduce: 用户编写,接受中间结果 key 和 key 的一系列值。将这些值组合起来成为更少的 k/v;通常每个 Reduce 函数只输出一个 或者 0 个值。中间结果太多无法全部放到内存中,可以通过迭代的方法来处理大量的 value
2.1 Example
设想一个需要统计文件中每个单词数量的一个问题,我们很可能编写这样的代码:
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1")
reduce(String key, String values):
// key: a word
// values: a list of counts
int result = 0
for each v in values
result += ParseInt(v)
Emit(AsString(result))
map:给每个单词添加一个属性(出现的次数,这里就是1)
reduce:给每个特定的单词加起来计算总数并且提交
此外,用户编写代码以使用输入和输出文件的名称以及可选的调整参数来填充mapreduce规范对象。然后,用户调用MapReduce函数,并将其传递给指定对象。用户代码与MapReduce库(在C ++中实现)链接在一起。
2.2 Types
尽管前面伪代码使用 string 来写的输入输出,但是从概念上说,是由用户来指定 map 和 reduce 的类型
map (k1, v1) -> list(k2, v2)
map (k2, list(v2)) -> list(v2)
输入值和中间值来自不同的域,中间值和输出值来自相同的域
C ++实现在用户定义的函数之间来回传递字符串,并将其留给用户代码以在字符串和适当的类型之间进行转换
2.3 More Examples
这有一些可以使用 MapReduce 简化的计算:
Distributed Grep: 分布式的匹配,map 函数提交一个符合匹配的 line, reduce 的作用只是复制中间结果到输出
Count of URL Access Frequency: 网页访问计数,map 处理网页请求并且输出中间结果为
Reverse Web-Link Graph: 翻转网络链接图, map 输出
Term-Vector per Host: 术语向量是出现在一篇文章中最重要的术语集合列表
Invert Index:map函数解析每个文档,并发出一系列<单词,文档ID>对。 reduce函数接受给定单词的所有对,对相应的文档ID进行排序,并发出一个“单词,列表(文档ID)”对。setofall输出对形成一个简单的倒排索引。易于扩展此计算以跟踪单词位置。
Distributed Sort: 分布式排序,map函数功能从每个记录中提取键,并发出一个
3 Implementation
MapReduce 可以有很多不同的实现,正确实现是根据你自己所在的环境来进行实现,例如某个实现可能很适合一个共享内存的小机器,某个实现可能是在NUMA多处理器的环境下,也可能是在一个大的网络连接的集群的机器中。
NUMA Non-uniform memory access
非统一内存访问架构是一种为多处理器的电脑设计的内存架构,内存访问时间取决于内存相对于处理器的位置。在NUMA下,处理器访问它自己的本地内存的速度比非本地内存快一些。 非统一内存访问架构的特点是:被共享的内存物理上是分布式的,所有这些内存的集合就是全局地址空间
这节描述的是 Google 云计算环境下广泛使用的,下面是 Google 的配置:
- 机器,都是典型的Linux系统,运行在基于x86的双处理器上,每台机器 2-4GB 内存
- 网络,使用商品网络硬件,在机器级别通常为100Mb/s或1Gb/s,但平均平均对分带宽要小得多
- 集群中有上百或者上千个机器,所以机器故障出现很正常
- 存储,使用廉价的 IDE 硬盘直接保存每个机器自己的数据,开发出的分布式文件系统来管理这些磁盘上的文件。文件系统使用复制来在不可靠的硬件上提供可用性和可靠性。
- 用户通过一个任务调度系统提交任务。每个工作包含一系列的任务,使用任务调度器来分配到集群中可用的机器上
3.1 Execution Overview
Map 调用分布在多个机器上,自动将输入数据分配成 M 组,输入的分割可以并行的发生在不同的机器上。 Reduce 调用也是分布式的,通过将中间值的key使用一个分割函数(例如:hash(key) mod R)来将任务分配到不同的机器上。分区数量 R 的取值和分区数量也是通过用户来指定的。
下面这个图说明了 MapReduce 执行的完整流程:
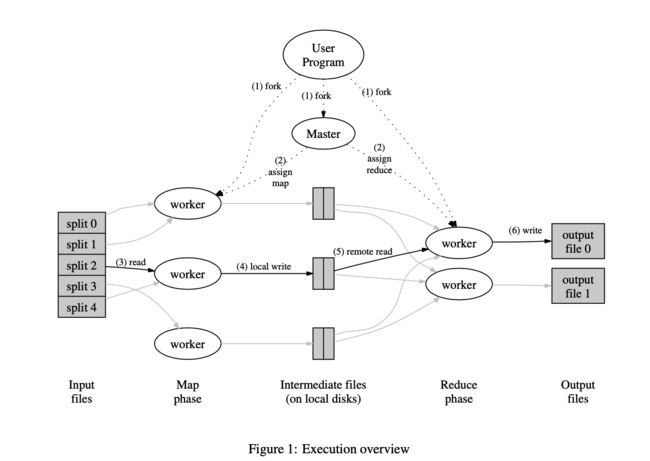
- 用户程序中的 MapReduce 库首先将输入文件分成 M 份(每份 16MB - 64 MB),然后开始在集群中复制很多拷贝
- 程序中有一份拷贝是特殊的(master)。剩下的 worker 来被分配工作,有 M 个map任务和 R 个 reduce 任务来分配给不同的 worker。master 来挑选空闲的 worker 分配给他们每个一个 map task 或者 reduce task
- 一个被分配到 map 工作的 worker 将会从对应的分割的内容中读取。它会解析
k/vpair 到输入数据并且传给到用户定义的 map 函数。Map 函数产生的中间key/value数据将会被保存在内存的缓存中 - 缓存中的 pair 会被周期性的写入到本地磁盘上,通并且过分割函数将该文件分成的 R 个区域。这些缓冲对的位置在本地磁盘上被传递回主服务器,该主服务器负责将这些位置转发给reduce worker。
- 当一个 reduce worker 被 master 告知这些存储的区域,reduce worker 将使用远程过程调用来从 map workers 的本地磁盘以及缓存中读取 pair 对。当一个 reduce worker 读取了所有的中间数据,它将会跟配相同的 key 来进行排序。排序是必需的因为通常会有很多不同的 key 映射到同一个 reduce 任务。如果中间数据太大来放到内存中排序,外排序就会被使用
- reduce worker 迭代排过序的中间数据,对于每个独特的中间值 key,它会传递这个 key 和对应中间值到用户定义的 reduce 函数中来处理。Reduce函数的输出将附加到此reduce分区的最终输出文件中
- 当所有的 map task 和 reduce task 都被完成之后,master 唤醒用户程序。这个时候,MapReduce 的调用返回到用户的代码逻辑中
在成功的完成之后,mapreduce执行的输出将会在 R 个输出文件中(每个reduce task 都会被用户指定文件的名称)。通常来说,用户不会将 R 个输出文件合并成一个,而是将这个文件作为另一个 MapReduce 的输入。或者把他们当成另外的分布式程序的输入
3.2 Master Data Structures
master 保存一些数据结构。对于每个 map 和 reduce 任务,它会保存状态(idle,in-progress,completed),以及识别每个 worker machine(非空闲任务)。
master 是处于 map 任务发送到 reduce 任务中间的导管,master 会保存中间文件区域的位置。因此,对于每个完成的 map 任务, master 保存 R 个由map任务产生的中间文件的大小和位置。当 map 任务完成之后,会更新这些文件的位置和大小。这些信息将逐渐被推送到已经在工作的 reduce 任务。
3.3 Fault Tolerance
由于 MapReduce 是用来在大量机器上处理大量数据的一个库,所以这个库必需能够有很好的容错能力。
Worker Failure (工作节点故障)
master 节点周期性的 ping 每个 worker 节点。如果在一个特定的时间内没有收到回复,那么 master 节点就会将这个 worker 标记为失败。完成 map 任务的 worker 节点将会被重置为 idle 空闲状态,然后就可以被其他 worker 节点安排。相似的,如果一个节点上的 map 或者 reduce 任务在执行过程中失败了,那么这个任务将会被重置然后分配然后重新分配。
如果一个 map 任务的节点在完成任务之后出现故障,那么就需要重新执行这个任务,因为这个节点变得不可访问。但是如果是 reduce 任务完成之后节点出现故障,不需要重新执行,这是因为 reduce 任务的输出被保存到一个全局文件系统中。
当一个 map 任务首先在节点 A 上执行之后在节点 B 上执行时,所有正在执行的 reduce 节点将会被告知这次重新执行过程。所有还没有从 worker A 读取数据的 reduce 任务将会 worker B 读取。
MapReduce 可以处理大规模的 worker 节点故障。例如在一次 MapReduce 任务中,一个由80台计算机组成的集群由于网络问题无法访问,MapReduce 的 master 节点只是简单的让那些不能正常执行任务的工作节点再次执行任务,然后继续向前执行任务直到完成 MapReduce 操作。
Master Failure(主节点故障)
让 master 节点周期性的上述master节点的数据结构的检查点。如果 master task 失败了,可以从上一个检查点的拷贝恢复。但是如果只有一个主节点,那么出现故障的可能性非常小,因此如果主节点出现故障,我们的当前的实现就中止了此次 MapReduce 任务。客户端可以检查到这种情况,然后可以选择是否重试 MapReduce 操作。
Semantics in the Presence of Failures(语义可能存在的故障)
当用户指定的 map 和 reduce 操作对于他们的输入输出都确定好了之后,分布式的实现将会产生一个类似于线性执行过程任务执行的结果。
我们依赖于 map 和 reduce 任务的 原子性 commit 作为这个特性的保证。每个执行过程中的任务都会将把他的输出保存到一个私有的临时文件中。一个 reduce 任务产生一个这样的文件,但是一个 map 任务将会产生 R 个这样的文件。当一个 map 任务完成之后, worker 节点发送包含这 R 个文件名的消息到 master 节点。如果这个节点已经接收到完成的消息,那么将会忽略这个消息,否则将会把这些文件名保存到 master 节点的数据结构中。
当一个 reduce 任务完成的时候,reduce worker 将会原子性的将它的临时文件重命名成一个输出文件。如果有以个 reduce 任务在多个机器上同时完成,那么这个重命名的操作将会对于一个输出文件多次执行。我们依赖于基础文件系统提供的原子重命名操作,以确保最终文件系统状态仅包含一次执行reduce任务所产生的数据。
map 和 reduce 操作绝大部分都是确定性的,事实上我们的语义将会和线性顺序执行的程序的结果一致,这样很容易分析程序的行为。当 map/reduce 操作是不确定的时候,我们提供弱化但是可信的语义。例如在一个不确定的语义中,一个特定 reduce 任务的输出和这个任务顺序执行的结果一致。然而,用于不同reduce任务R2的输出可以对应于由不确定性程序的不同顺序执行所产生的用于R2的输出。(这里保留疑问,没有太懂什么意思,指的是有可能是线性结果一致的意思吗?)
考虑有一个 map 任务 M,和两个 reduce 任务 R1,R2,e(Ri)是 Ri提交的结果,弱一点的语义指的是,e(R1) 可能读取的 M 的一个执行的结果而 e(R2) 可能读取的是 R 执行输出的另外一个结果。
3.4 Locality
网络带宽是在云计算环境中比较稀缺的资源(尽量少用)。通过将输入文件(由GFS保管)保存到本地磁盘上来减少网络带宽的使用。GFS 将每个文件分成 64 MB的块,然后将每块保存几个副本(通常为3份)在不同的机器上。MapReduce 尽量将这些位置信息保存下来然后尽量将含有某个文件主机的任务分配给它,这样就可以减少网络的传递使用。如果失败,那么将会尝试从靠近输入数据的一个副本主机去启动这个任务。当在一个集群上执行大型的 MapReduce 操作的时候,输入数据一般都是本地读取,减少网络带宽的使用。
3.5 Task Granularity
我们将一个 map 任务分成 M 块,然后 reduce 会处理最后输出成 R 块。
理想情况下,M 和 R 应该远远大于集群中的 worker 节点数量。让每个节点执行不同的任务将会有利于动态的负载均衡,同时会加速当一个 worker 节点故障之后的恢复,map 任务完成之后可以分配到所有的其他节点上。
R 和 M 在实现过程中会有边界,因为 schedule 决策需要 O(M + R)的时间,保存这个信息到内存中需要 O(M*R)的复杂度(常数内存很小)。
R 通常是由用户指定的,这是由于每个 reduce 任务的输出将会输出到单独的文件中。在实际中,通常 M 被选择到每个单独的任务输入数据将会是 16MB ~ 64MB,让 R 要比我们使用的机器的数目的小几倍。
例如,M =20,000,R = 5,000,worker machines = 2000
3.6 Backup Tasks
让整个 MapReduce 任务时间延长的原因主要有 “拖延者”:某一个机器在 map/reduce 任务上花费了太多的时间。导致这个 “拖延者” 的原因可能有很多,比如一块读写速度超级慢的硬盘 1MB/s(其他的是 30MB/s)比如集群在这个机器上也分配了其他任务,这些任务竞争使用 CPU、硬盘网络等等。我们最近遇到的一个问题是机器初始化代码中的一个错误,该错误导致禁用了处理器缓存:受影响机器的计算速度降低了一百倍。
4 Refinements
尽管上面说的够用了,但是我们还是找到一些可以优化的点。
4.1 Partitioning Function
用户将会指定输出文件的数量 R。输入数据将会根据中间值来把这些数据分区。一个默认的分区函数就是 hash函数(hash(key) mod R) 。通常情况下这样很好,但是在某些情况下不是很好。例如,输出数据是 URL key,我们希望具有相同主机 hostname 的 URL 在一起,这样,MapReduce 提供了用户自己制定 分区函数的方式,例如可以写为(hash(Hostname(urlkey))),这样具有相同的 hostname 的URL将会在一个相同的输出文件中。
4.2 Ordering Guarantees
我们保证了在某个给定的分区中,中间值的 k/v pair 将会按照增序排列,这样在某些需要有序的场景下是很有用的。
4.3 Combiner Function
在某些情况下,最终的输出文件reduce是需要根据中间值来合并的。例如在2.1的 word count 中,需要统计每个单词的数目,我们输出的是
在每个执行 map task 的机器都会执行 conbine 函数。
combine 和 reduce 的唯一区别:
- combine 输出是到中间值文件中
- reduce 输出到一个最终的输出文件中
4.4 Input and Output Types
MapReduce 库提供了几种输入的类型。
例如,在 “text” 模式下输入将每一个行当作 k/v pair,这行的偏移量当作 key,这行的内容当作 value。
用户可以通过实现 reader 接口在实现自己的输入类型,尽管大多数用户都只使用预定义的类型。
reader 不一定要从文件中读取数据,也可以从数据库中读取数据,或者从内存中的某个的某个数据结构中获取数据。
同样的,输出也可以自定义。
4.5 Side-effects
在某些情况下,用户需要产生一些额外的输出文件在reduce 的输出结果中。我们依靠这个应用程序自己的编写者来使此类副作用成为原子和幂等的。通常应用程序将会写入一个临时文件中,然后当它完成的时候将会原子性的重命名这个文件。
我们不提供原子性的两节点提交由一个任务产生的多个输出文件。因此,产生多个输出的结果的任务应该是确定性的。
4.6 Skipping Bad Records
在处理大量数据的时候,由于用户的 map/reduce 函数的错误在处理某些数据的时候产生bug,这个时候可以选择跳过这些 bug。有的时候我们可以查找到bug所在的地方,但是有的时候我们找不到bug,因为可能是第三方的库导致的错误,我们提供了一种可选的执行模式来跳过这些可能出现错误的记录。
每个 worker 进程都会有一个监听段错误和总线错误的处理器。在执行用户的 map/reduce 函数之前,mapreduce 将会在一个全局变量中保存顺序编号。如果用户代码产生了一个 signal,那么就会发送一个 UDP包到 MapReduce 的 master 节点上。当 master 节点发现在某个几点上出现了很多次故障的时候,之后就会跳过这个记录。
4.7 Local Execution
在 Map/Reduce 中debug需要一些 trick,因为在分布式系统中执行可能是在几千台机器中,工作分配也是动态的。MapReduce 提供了一个另外的本地MapReduce 的本地实现(顺序执行),这样就可以在本地来进行 debug了。
4.8 Status Information
master 节点通过 HTTP 服务器提供一个显示当前状态的网页。这个界面显示了多少任务完成了,多少任务还在执行,中间数据有多少字节等,还包含了错误的标准输出文件的链接等,用户可以通过这个界面预估还有多久可以完成任务。当执行很慢的时候,可以通过这个界面来查找原因。
另外,top-level 的状态信息还会显示哪些 worker 节点有故障,哪些任务失败了。
4.9 Counters
提供一个全局的计数器来统计某些数据,例如统计大写单词的出现次数。
Counter* uppercase;
uppercase = GetCounter("uppercase");
map(String name, String contents):
for each word w in contents:
if (IsCapitalized(w)):
uppercase->Increment();
EmitIntermediate(w, "1");
计数器的值会从每个节点周期性的发送到master节点,主节点统计计数器的值并且在 状态页面显示。
有些值MapReduce 会自己去统计。
计数器功能对于完整性检查MapReduce操作的行为很有用。例如,在某些MapReduce操作中,用户代码可能想要确保所生成的输出对的数量完全等于所处理的输入对的数量,或者所处理的德语文档的比例在该比例之内。
Others
shuffle:将所有具有相同 key 的value 发送个单个的 reduce 进程,在网络上传输数据,是MapReduce代价最大的部分