elasticsearch源码分析之discovery(七)
Discovery模块概述
elasticsearch中的Discover模块,这个模块主要是发现模块负责发现集群中的节点,以及选取主节点。用作处理elasticsearch中的集群问题,是elasticsearch中比较复杂的一个模块。
discovery有几类:
- Azure discovery(类似于多播),它可作为插件使用。
- EC2 discovery,作为插件使用。
- Google Compute Engine (GCE) discovery (类似于多播),它可作为插件使用。
- zenDiscovery是elasticsearch的内置并且默认的discovery模块。 它提供unicast发现,并且扩展到支持云环境和其他形式的发现。
这里我们只分析zenDiscovery。
Discovery子模块
ZenDiscover其实是由一些其他的模块配合而成的,比如node之间的通信就是用的transport模块。ZenDiscover可以分为以下几个子模块:
Ping
这是一个节点使用发现机制来查找其他节点的过程。
Unicast
通过配置discovery.zen.ping.unicast对列表中的node单播。
单播发现需要使用的主机列表作为传播的路由器,它使用discovery.zen.ping.unicast前缀提供以下设置:
可以是数组设置或逗号分隔设置。
每个值的格式应为host:port或host(其中,port默认为9300)。 请注意,IPv6主机必须加括号。 默认为127.0.0.1,[:: 1]
unicast discovery用transport模块来执行发现。
Master Election
用作Master的选举;集群的主节点被选举或加入是ping过程的一部分。这是自动完成的。
当主节点停止或遇到问题时,群集节点再次开始ping过程,并选择一个新的主节点。这轮ping还用作对(部分)网络故障的保护,其中节点可能不正当地认为主节点已经故障。在这种情况下,节点将简单地从其他节点听到关于当前活动的主机的信息。
discovery.zen.minimum_master_nodes设置需要加入新选择的主节点的主合格节点的最小数量,以便选择完成,并且选择的节点成为masternode。相同的设置控制应作为任何活动集群的一部分的活动主机合格节点的最小数量。如果不满足此要求,活动主节点将退出,并且将开始新的主节点选择。
Fault Delection
用ping的方式来确定node是否在集群里面,有两个fault detection进程运行。 第一个nodesFD是由master去ping所有其他集群中的节点并验证他们是活着的。 第二个masterFD是每个节点ping到master以验证其是否仍然活着或者需要启动选举过程。
有如下设置使用discovery.zen.fd前缀控制fault detection过程:
ping_interval #节点被ping的频率,默认为1s。
ping_timeout #等待ping响应的时间长度,默认为30秒。
ping_retries #ping失败重试次数,默认为3。
Cluster state updates
这个只在master node上有效,用于向其他node发布集群的状态信息。
master节点是集群中可以更改集群状态的唯一节点。 master一次处理一个群集状态更新,修改更新并将更新的群集状态发布到群集中的所有其他节点。 每个节点接收发布过来的消息,更新其本地的集群状态,并且响应给主节点。主节点会等待所有节点的响应,直到一个超时时间,在这之前后面的更新请求都会排在一个队列中。 discovery.zen.publish_timeout默认设置为30秒,可以通过集群更新设置api动态更改。
No master block
要使集群完全可操作,它必须具有活动的master节点,并且运行的主节点合格节点数必须满足discovery.zen.minimum_master_nodes设置(如果设置)。
discovery.zen.no_master_block设置控制当没有活动主机时应拒绝哪些操作。
discovery.zen.no_master_block设置有两个有效选项:
all
节点上的所有操作读和写操作都将被拒绝。这也适用于api集群状态读取或写入操作,如get索引设置,put映射和集群状态api。write(默认值)
写操作将被拒绝。根据最后一个已知的集群配置,读取操作将成功。这可能导致过时数据的部分读取,因为此节点可能与群集的其余部分隔离。
discovery.zen.no_master_block设置不适用于基于节点的api(例如cluster stats、 node info and node stats)。对这些API的请求不会被阻止,并且可以在任何可用节点上运行。
ZenDiscovery代码分析
构造函数
在ZenDiscovery构造函数中,初始化一些基本的服务接口和关键参数:
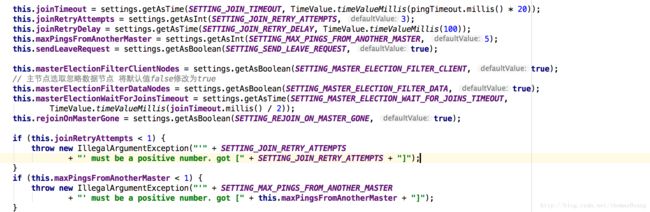
- pingTimeout: 取自discovery.zen.ping_timeout(默认为3s)允许调整选举时间来处理网络慢或拥塞的情况(更高的值确保更少的失败机会)。
- joinTimeout:取自discovery.zen.join_timeout(默认值为ping超时的20倍)。当一个新的node加入集群时,将会发个join的request到master,这个request的timeout即joinTimeout。
- joinRetryAttempts:join重试的次数,默认为3次。
- joinRetryDelay:重试的间隔,默认为100ms。
- maxPingsFromAnotherMaster:容忍其他master发出的,在强制其他或是本地master rejoin之前的次数。
- masterElectionWaitForJoinsTimeout: master选举时等待join的timeout,默认是joinTimeout的一半。
- masterElectionFilterClientNodes:取自discovery.zen.master_election.filter_client为true(默认值为true)
如果为true,则在主选举期间忽略来自客户机节点(节点node.client为true,或node.data和node.master都为false的节点)的ping。 - masterElectionFilterDataNodes: 取自discovery.zen.master_election.filter_data(默认值为false),如果为true,则在主选举期间将忽略来自非主节点数据节点(node.data=true,node.master=false)的ping。在主选举期间总是观察到来自master节点的ping。
joinRetryAttempts和maxPingsFromAnotherMaster必须大于等于1.
运行
ZenDiscovery的运行即几个子模块的运行
joinThreadControl
首先要将自己加入集群,使用joinThreadControl
1、首先是findMaster,findMaster通过pingService来实现,在这里我们只探讨unicast的ping的方式,主要的实现在sendPings这个方法里面,让我们来详细看看这个方法是怎么ping的。
确定需要ping的目标:
- 第一部分是其实是由clusterService.state().nodes()而得来,也就是拥有同一cluster.name的这些node
- 第二部分是hostsProviders自动生成的hosts列表(此处怎么来的还不清楚)
- 第三部分是所以可能作为master的node
- 第四部分是discovery.zen.ping.unicast.hosts配置的列表(主要在这里)

2、对nodesToPingSet排序,这个排序的依据是根据可能成为master的概率来的。将master node排在前面,data node排在后面;然后把第四部分的hosts加在最前面(人工配置的master,如果有的话肯定从中选择),最后在加入刚才排序的集合,这样组成新的集合nodesToPing。
3、分别对nodesToPing中的node发送ping,如果transport连接在,将会发送一个ping request到目标node,发送的逻辑是调用了TransportService,最终调用NettyTansport,tranport模块参照http://blog.csdn.net/thomas0yang/article/details/52355798。如果transport连接不在了,会先connectToNode建立连接,然后再发送ping request。
// if we find on the disco nodes a matching node by address, we are going to restore the connection
// anyhow down the line if its not connected…
// if we can’t resolve the node, we don’t know and we have to clean up after pinging. We do have
// to make sure we don’t disconnect a true node which was temporarily removed from the DiscoveryNodes
// but will be added again during the pinging. We therefore create a new temporary node
这一段解释没有看懂。。。
4、对ping之后有响应结果的集合进行过滤筛选,过滤逻辑参照上文中masterElectionFilterClientNodes和masterElectionFilterDataNodes解释。
pingMasters,即ping各个节点之后返回的各节点元数据中存储的master节点,在pingMasters列表中不能包括本地节点,否则我们可能在ZenDiscovery中没有检查其他节点,直接选举自己#innerJoinCluster(),造成脑裂。
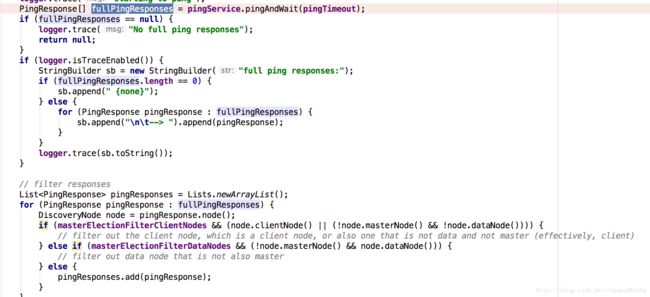
5、然后创建两个node列表,一个是activeNodes,表示所有active的node,joinedOnceActiveNodes,前者后者表示集群中之前就存在的node。
6、 如果从之前的ping中没有发现master,表示要重新选举了;首先判断active的master node是否大于配置中的minimumMasterNodes,不然是选举不了master的。如果满足minMaster,会优先从joinedOnceActiveNodes中选举出master;若选不出才会从activeNodes中去选举。选举的逻辑比较简单, 先排序,在排序时会remove掉不能作为master的node,排序完后将第一个作为master。
7、如果pingMasters不为空,表示已经有选举出的master了,但是还在pingMasters列表中进行一次选举,得到master。官方注解:lets tie break between discovered nodes。但是此时pingMasters中如果不一个master,则会出现了脑裂。
在加入集群后,node就根据自己的角色,做不同的事情。
master
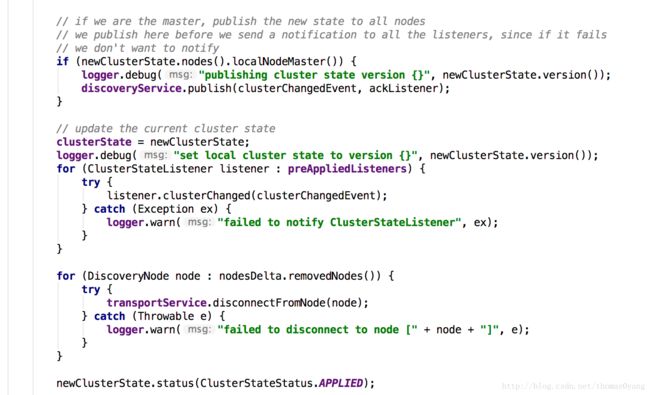
如果当前node是master,会先等待来足够的有资格成为master的节点join以完成主选举(waitToBeElectedAsMaster方法), 如果是则会通过ClusterState更新任务变为主节点。
更新任务参照
真正发布状态参照InternalClusterService.UpdateTask类的run方法,
然后会启动nodesFD,nodesFD启动一个schedulethreadPool.schedule(TimeValue.timeValueMillis(0), ThreadPool.Names.SAME, fd);去ping其他的node,相当于heartbeat,如果检测失败会被踢出集群nodesFD.remove(node, NodeFD.this)。
(上面一些代码比较凌乱,有待深入研究)
如果当前node不是master,会向master发出一个join的request,注意这里并不会开启一个master fault detection;因为这一部分在processNextPendingClusterState中实现。
publishClusterState
elasticsearch默认发送state采用diff的方式,当然你也可以通过配置来设置discovery.zen.publish_diff.enable是否使用diff。
ClusterState表示集群的当前状态。具体参照elasticsearch源码分析之Gateway(六)
集群状态对象是不可变的,除了{@link RoutingNodes}结构和和集群状态{@link #status},前者是根据{@link RoutingTable}的需求构建的,后者是在集群状态发布和应用处理期间更新。集群状态只能在主节点上更新。所有更新都由单个线程执行,由{@link InternalClusterService}控制。每次更新后,{@link DiscoveryService#publish}方法会向群集中的所有其他节点发布群集状态的新版本。实际的发布机制委托给{@link Discovery#publish}方法,并取决于发现的类型。例如,对于本地发现,它由{@link LocalDiscovery#publish} 方法。在Zen发现中,它在{@link PublishClusterStateAction#publish}方法中处理。发布机制可以被其他发现覆盖。
集群状态实现{@link Diffable}接口,以支持发布集群状态差异,而不是每次更改时的整个状态。如果此节点存在于集群状态的先前版本中,则发布机制应仅向节点发送差异。如果一个节点不存在于以前版本的集群状态,这样的节点不太可能有以前的集群状态版本,应该发送完整版本。为了确保差异应用于集群状态的正确版本,每个集群状态版本更新将生成{@link #stateUUID}唯一标识该版本的状态。此uuid由{@link ClusterStateDiff#apply}方法验证,以确保应用正确的差异。如果uuids不匹配,则{@link ClusterStateDiff#apply}方法会抛出{@link IncompatibleClusterStateVersionException},这将导致向生成此异常的节点发送一个完整版本的集群状态。
发送ClusterChangedEvent,这个类持有两个clusterstate
private final ClusterState previousState;
private final ClusterState state;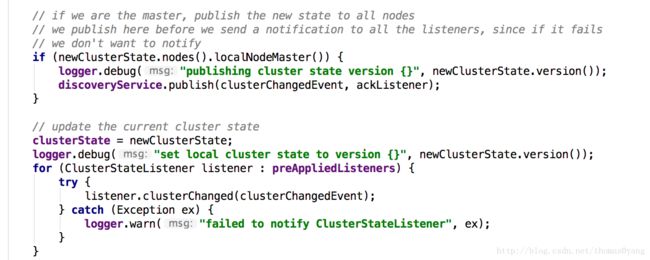
publish最终会调用tranportservice方法,发送数据。具体参照elasticsearch源码分析之Transport(五)
FaultDetection
MasterFaultDetection
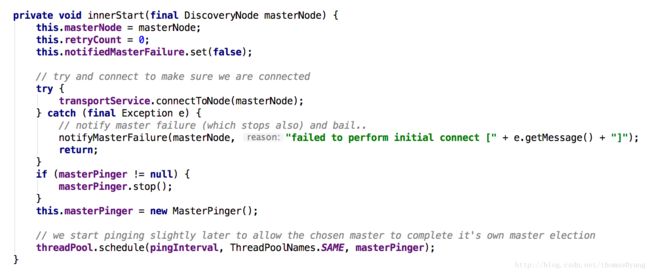
MasterFaultDetection是每个节点ping到master,进行错误检测。
启动时候连接masternode,并按照一定频率ping master。
master接收到masterping,进行一系列校验,返回空response
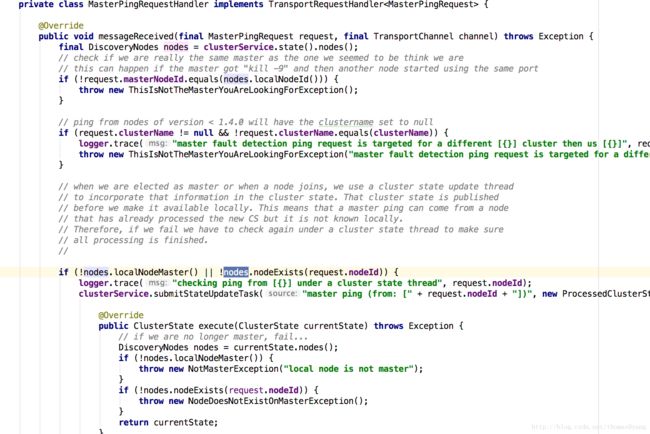
node端接收到response,

如检测到master失效,则发布master失效通知,启动重新选举
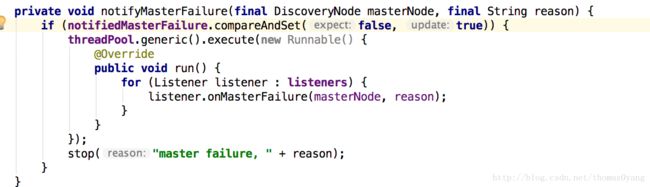
NodesFaultDetection
如果本node是master,而它又接收到来自其他node的再来看看NodesFaultDetection,则集群里有两个master,一般称之为“脑裂”。遇到这种情况时,node会比较自己的version和另外master的version;如果比别人的小,就会stop掉自己的nodesFD和masterFD,然后rejoin进集群,开始joinThreadControl干的那些事儿。如果version比别人的大,那么当前node仍然是master,它会向另一个master发出rejoin指令。
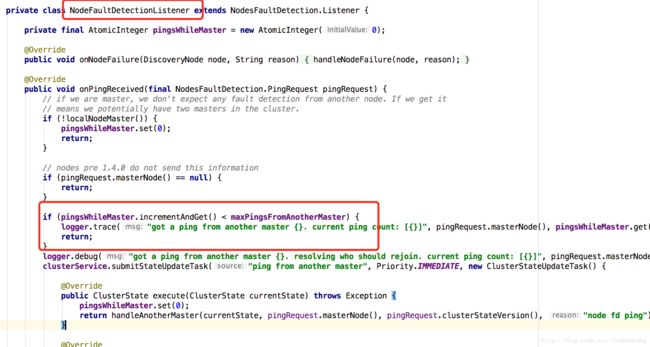
终于完了,异步跟踪查看代码比较累。
Discover的内容比较多。这个模块主要的作用是维护这个集群的状态,并负责state的下发,master的选举,配置的更新等等,是elasticsearch中较为核心的一个模块。
最后,感谢http://www.opscoder.info/es_discover.html