【再论深度学习必死】马库斯回应14大质疑,重申深度学习怀疑论

新智元编译
作者:Gary Marcus
翻译:新智元编辑部
深度学习论战再起,NYT心理学家Gary Marcus如约写了一篇偏技术的文章,回应对他此前提出的深度学习问题的质疑。无监督学习适用于什么问题?为什么不说深度学习更好的方面?马库斯说,尽管他提出了所有这些问题,但他并不是认为我们需要放弃深度学习。相反,我们需要重新定义它:不是作为一种通用的方法,而是作为众多工具中的一种。
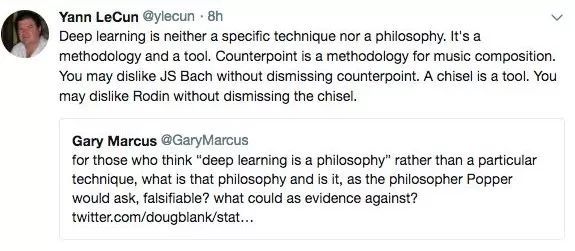
马库斯和LeCun的深度学习论战从未停止。
新年伊始,纽约大学认识心理学家马库斯发文,列出深度学习十大局限,引发广泛讨论。
很快,LeCun、AAAI前主席Thomas Dietterich等人都加入到讨论中。LeCun更有甚至还抛出“深度学习已死”的言论。马库斯此前回应,他会写一篇偏技术的文章回应种种质疑。现在,这篇文章来了——
“任何真理都要经历三个阶段:第一,被嘲笑;第二,被激烈反对;最后,被理所当然地普遍接受。”
——叔本华
我在最近一篇评价深度学习的文章(Marcus,2018)中,概括了深度学习的十大挑战,并提出深度学习本身虽然有用,但它不可能实现通用人工智能。我建议把深度学习视为“一种非普遍的解决方法,而只是一种工具。”
相比纯粹的深度学习,我呼吁混合模型,不仅包括深度学习的监督形式,还包括其他技术,例如符号处理(symbol-manipulation),以及无监督学习(它本身也可能被重新概念化)。我也敦促社区考虑将更多的内在结构纳入AI系统。
在这篇文章发表之后,几天之内,成千上万的人在推特上发表了自己对这个问题的看法,有些人热情支持我的论点(例如,“这是我多年来读到的有关深度学习和AI的最好的观点),有些相反(例如,“有思考......但大部分都是错误的”)。
我认为澄清这些问题非常重要,因此我编了一份14个常见问题的列表。无监督学习适用于什么问题?为什么我不说深度学习更好的方面?最初是什么让我有权利去讨论这个问题?问一个神经网络从偶数到奇数的泛化是怎么回事?等等,还有更多问题,在这里我没能全部列出,但我尽量做到有代表性。
1. 什么是通用智能?
机器学习领域的著名教授Thomas Dietterich的评论是我迄今为止看到的最全面、最清晰的,他给出了一个很好的答案:
“通用智能”是一个可以在广泛的目标和环境中智能地行动的系统。例如,参见Russell和Norvig的教科书,他们对智能的定义是“理性行事”。
2. 马库斯对深度学习的看法不友好。他应该对深度学习取得的巨大成就多说一些好话。但他将深度学习的其他成就最小化了。
Dietterich提出了这两点,他写道:
Gary Marcus 的文章令人失望。他几乎绝口不提深度学习取得的成就(例如自然语言翻译),并且最大限度地贬低了其他的成就(例如说有 1000 个类别 ImageNet“非常有限”)。
前半部分说的没错,我确实可以说更多积极的东西。但并不是我“绝口不提”。我也没有不提Dietterich说的这些例子。我在文章的第一页就提到了:
自那以后,深度学习在语音识别、图像识别、语言翻译等领域取得了许多最先进的成果,并在当前AI的广泛应用中起着重要作用。
在文章后面的部分,我引用了几篇优秀的文章和优秀的博客,提到了无数的例子。不过,这些例子大部分都不算是AGI(通用人工智能),这是我的论文的主要关注点。(例如,谷歌翻译固然非常令人印象深刻,但它不是通用的;它不能回答关于它所翻译的内容的问题,而人类译者能。)
Dietterich的批评的后半部分更具实质性。1000个类别真的“非常有限”吗?是的,与人类认知的灵活性相比,这非常有限。认知科学家通常把一个人所知道的原子概念(atomic concept)的数量定为5万个,我们可以很容易地把这些概念组合成为数量更多的复杂想法。这5万个概念中,“宠物”和“鱼类”可能算在里面,但“宠物鱼”可能就没有算进去。而且我们可以很容易地理解“患上白点病的宠物鱼”这个概念,或者意识到“刚买了一只宠物鱼,就发现它感染了白点病,这非常令人失望”这样的概念(这是儿时的经历,现在仍然感到不满)。我能表达多少种想法呢? 比1000要多得多。
我不是很确定一个人能够识别多少视觉类别,但我认为这个数字大致是差不多的。你可以试试在谷歌图像搜索“宠物鱼”,结果会不错;然后你再试试搜索“佩戴护目镜的宠物鱼”,你会发现出来的大部分图片是戴着护目镜的狗,误报率超过80%。
机器在辨别狗的品种的任务上准确率超过了非专业的人类,但在解释复杂场景时,人类大幅领先,例如解释一个背着背包而不是背着降落伞的跳伞运动员会发生什么。
在我看来,把机器学习的领域集中在1000个类别块上,本身就是一种伤害。这是为了一种短期的成功,因为它避开了更困难、更开放的问题(例如场景和句子理解),而这些问题最终是必须解决的。相对于我们人类可以看到和理解的句子和场景的基本上是无限范围相比,1000个类别真的非常小。[另见文末注释2]
3. 马库斯说,深度学习毫无用处,但对于很多事情来说已经很好了
当然,深度学习是有用的,我从没说过它毫无用处,只是(a)在目前的监督形式下,深度学习可能正在接近极限,(b)这些极限将不能完全符合通用人工智能——除非我们开始合一些其他的方法,比如符号处理和固有性(innateness)。
我的核心论点是:
尽管我提出了所有这些问题,但我并不是认为我们需要放弃深度学习。
相反,我们需要重新定义它:不是作为一种通用的方法,而是作为众多工具中的一种;如果将深度学习比喻为一个功能强大的螺丝刀,那么我们还需要锤子、扳手和钳子,以及凿子和钻头、电压表、逻辑探针和示波器。
4. “我不理解的一点是,GaryMarcus说DL对分层结构不好,但在LeCun在他发表在《自然》的评论文章中说DL特别适合于开发这样的层次结构。”
这是Ram Shankar的提出一个敏锐的问题,我本应该更清楚地回答这个问题:我们考虑的层级(hierarchy)有许多不同的类型。深度学习是非常好的,可能是目前为止最好的,就像LeCun所说的那样,我通常称之为分层特征检测(hierarchical feature detection)。你可以用像素来构建线条,用线条表示字母,用字母表示单词,等等。Kurzweil和Hawkins也强调了这一点,这可以追溯到Hubel和Wiesel的神经科学实验(1959),以及福岛邦彦的AI实验(Fukushima, Miyake, & Ito, 1983)。福岛在他的“新认知机”(Neocognitron)模型中,手工连接了更多抽象特征的层次结构; LeCun等许多人的研究显示(至少在某些情况下),不必手工设计。
但是,你不必跟踪一路上遇到的子组件(subcomponents)。顶层系统不需要对整个输出的结构进行显式的编码,这是为什么一个深度系统可以被欺骗的部分原因,例如它会认为黑色和黄色条纹的组合是一辆校车。(Nguyen,Yosinski,&Clune,2014)。这些条纹样式与校车的输出单元的激活紧密相关,这又与一系列低级特征相关联,但是在典型的图像识别深度网络中,没有由车轮、底盘、窗户等组成的完全实现校车表征。实际上,几乎所有有关欺骗的文献都提到这些情况。 [注3]
我在讨论中提到的层级结构的概念是不同的,聚焦在能够进行明确推理的系统周围。一个经典的例子是乔姆斯基提出的层次结构,他认为一个句子是由越来越复杂的语法单元组成的。例如,一个片语:“男人将他的汉堡误认为是热狗”(“the man who mistook his hamburger for a hot dog”),或一个更长的句子:“女演员坚持说她不会被那个把汉堡包当成热狗的人所超越”(The actress insisted that she would not be outdone by the man who mistook his hamburger for a hot dog)。我不认为深度学习在这方面能做得很好(例如,辨别女演员、男人和被误认的热狗之间的关系),尽管已经有这方面的研究。
即使在视觉领域,问题也没有完全得到解决。例如,Hinton最近提出的capsule的工作(Sabour, Frosst, & Hinton, 2017)试图通过使用更多结构化的网络来构建更可靠的图像识别的部分整体方向(part-whole direction)。我认为这是一种很好的趋势,也是一种试图解决欺骗问题的潜在方法,但同时也反映了标准的深度学习方法的局限。
5. “在通用人工智能的背景下讨论深度学习很奇怪。 通用人工智能不是深度学习的目标!”
来自魁北克大学教授Daniel Lemire在推特上对此做了很好的回应:“哦!Come on! Hinton,Bengio ......正在公开展示一个人类智慧的模型。”
Google的数学博士Jeremy Kun反驳了“通用人工智能不是深度学习的目标”这个可疑的说法。“如果这是真的,那么深度学习专家肯定会让大家相信这是没有经过改正的。”
吴恩达最近在《哈佛商业评论》上的文章暗示,深度学习可以在一秒之内做一个人可以做的任何事情。 Thomas Dietterich的推文,部分表示:“很难说,DL是有限制的”。 Jeremy Howard担心,深度学习被过度炒作的想法本身可能就被夸大了,然后表示每一个已知的限制都被反驳。
DeepMind最近的AlphaGo论文的定位有些类似,Silver等人满怀热情地报告说:
“我们的研究结果全面地证明,一个纯粹的深度强化学习方法是完全可行的,即使在最具挑战性的领域。”
在那篇论文的结论性讨论中,没有提到任何一个我的文章中提出的的10个深度学习挑战。(正如我将在即将发表的一篇论文中所讨论的那样,这实际上并不是一个纯粹的深度学习系统,这是另外一件事儿。)
人们不断对AI系统进行人类基准测试的主要原因正是因为AGI是目标。
6. 马库斯说的是监督学习,而不是深度学习。
Yann LeCun在我的Facebook页面发表了以下评论:
我没有时间做出适当的回应,但总之:(1)我认为大部分都是错误的,如果所有“深度学习”的实例都被“监督学习”所取代,那么错误就会大大减少。 (2)找到拓展无监督学习和推理的深度学习概念的方法,正是我过去两年半来一直倡导的。我不是一直在鼓吹这个,实际上我一直在努力......你对这件事很了解,但是它不会在你的论文中发生。
关于我所谓的不承认LeCun最近的工作的部分是很奇怪的。诚然,我找不到一篇好的总结文章来引用(当我问LeCun,他通过电子邮件告诉我目前还没有这样一篇文章),但是我明确地提到了他的兴趣:
深度学习的先驱Geoff Hinton和Yann LeCun最近都指出,无监督学习是超越受监督的,数据饥渴的深度学习的一个关键方式。
我还提到:
要清楚的是,深度学习和无监督学习并不是逻辑对立的。深度学习主要用于有标记数据的监督环境,但是有一些方法可以以无监督的方式使用深度学习。
我的结论也是积极的。尽管我对目前建立无监督系统的方法表示保留,但我对此却很乐观。
如果我们能够在这个更加抽象的层面建立能够设定自己的目标并进行推理和解决问题的无监督的系统,那么重大进展可能会很快出现。
LeCun的评论确实正确的是,我所提到的许多问题是监督式学习的一个普遍问题,而不是深度学习所特有的问题。我可以更清楚地了解这一点。许多其他的监督学习技术面临类似的挑战,如泛化的问题和对海量数据集的依赖;我所说的相对较少是深度学习所独有的。我的文章中忽略了这一点。
但是,其他监督式学习技术在同一条船上并不能真正帮助深度学习。如果有人能以非监督的方式提出一个真正令人印象深刻的深度学习方式,可能需要重新评估。但是我没有看到那种无监督的学习,至少是目前所追求的,尤其是对于我所提出的挑战,例如在推理,层级表示,迁移,健壮性和可解释性方面的补救。 [注5]
正如波特兰州立大学和圣达菲研究所教授Melanie Mitchell所说的那样,
... LeCun说马库斯的文章是“全部错误”的,但是如果限制在监督学习,那么并没有太多错误。我很乐意听到(现有的)非监督学习项目的例子来证明马库斯的论点错误的。
我也会。
同时,我认为没有原则的理由相信,无监督学习能够解决我所提出的问题,除非我们首先增加更抽象的符号表征。
7. 深度学习不仅仅是卷积网络,它本质上是一种新的编程形式 - “可微分编程”
7. 深度学习不仅仅是卷积网络(Marcus批评的那种),它本质上是一种新的编程形式 - “可微分编程” - 而且这个领域正试图用这种风格来制定可重用的构造。我们有一些:卷积,池化,LSTM,GAN,VAE,memory单元,routing单元等,Tom Dietterich认为。
这似乎(在Dietterich的更长的一系列推文中)被提出来作为一种批评,但我对此感到困惑,因为我是喜欢可微分编程。也许重要的是,深度学习可以采取更广泛的方式。
在任何情况下,我都不会将深度学习和可微分编程(例如,我所引用的像神经图灵机和神经编程这样的方法)等同起来。深度学习是许多可区分系统的组成部分。但是这样的系统也完全构建了我自己的符号处理元素,并且一直在敦促这个领域整合(Marcus,2001; Marcus,Marblestone,&Dean,2014a; Marcus,Marblestone,&Dean,2014b)包括内存单元和变量操作,以及其他系统,比如最近的两篇论文强调的routing单元。如果把所有这些东西融入到深度学习之中,那么我们能够把它带到AGI,那么我的结论将会变成:
大脑可能被视为由“广泛的”组成。可重用计算原语的数组的基本单位。处理类似于套基本。在一个微处理器中的指令 - 可能并行连接在一起,就像我在其他地方(Marcus,Marblestone,&Dean,2014)所论证的那样,在被称为现场可编程门阵列的可重新配置的集成电路类型中,丰富了指令集其中我们的计算系统建成只能是一件好事。
8. 现在和未来。也许深度学习现在不起作用,但它的不断迭代会让我们达到AGI。
有可能。我认为深度学习可能会使我们加入AGI,如果一些关键的东西(许多还没有被发现)被首先添加的话。
但是,我们补充说的是,将未来的系统称为深度学习本身,还是更为明智地称为“深度学习的某种特定的系统”,这取决于深度学习在哪里适合最终的解决方案。也许,例如,在真正充分的自然语言理解系统中,符号处理将扮演深度学习同样重要的角色,或者更重要的角色。
这里的部分问题当然是术语。最近一位很好的朋友问我,为什么我们不能称符号处理为深度学习?对此我作出回应:为什么不把包含符号处理的所有东西称为包含深度学习的东西呢?
基于梯度的优化应该得到应有的效果,符号处理也应该是这样,它是系统地表示和实现高级抽象的唯一已知工具,它基本上覆盖了世界上所有复杂的计算机系统,从电子表格到编程环境到操作系统。
最后,我猜想,信用也将归结于两者之间的不可避免的联姻,混合系统是20世纪50年代初期发展起来的,将符号处理和神经网络这两个伟大思想结合在一起。其它尚未发明的新工具也可能至关重要。
对于一个真正的深度学习的辅助者来说,任何东西都是深度学习,无论它是如何融合的,不管它与现在的技术有什么不同。如果用一个神经元代替经典的符号微处理器中的每个晶体管,但是保持芯片的逻辑完全不变,一个真正的深度学习辅助者仍然会宣告胜利。但是,如果我们把所有的东西放在一起,我们就不会理解推动(最终)成功的原则。 [注6]
9.没有机器可以推断。期望一个神经网络从偶数推断到奇数是不公平的。
这是一个用二进制数字表示的函数。
f(110) = 011;
f(100) = 001;
f(010) = 010.
f(111)是什么?
如果你是一个普通人,你可能会猜答案是111.如果你是我讨论过的那种神经网络,你可能不会。
如果你多次被告知神经网络中的“抽象函数”隐藏层,你可能会有点惊讶。
如果你是一个人,你可能会想到这个函数就像“反转”一样,很容易用一行计算机代码来表示。如果你是某种神经网络的话,很难从这种情况下学习反转的抽象概念。但真的不可能吗?如果你有一个先前的整数概念,则是有可能的。再试一次,这次在十进制:f(4)= 8; f(6)= 12.f(5)是什么?
当然,这个函数不像其他所有的函数那样,是由稀少的例子决定的。但是大多数人会回答f(5)= 10。
同样有趣的是,大多数标准多层感知器(代表二进制数字的数字)不会这样回答。除了François Chollet之外,神经网络社区的许多人都不愿意接受这种想法。
重要的是,认识到一个规则适用于任何整数是大致相同的一种泛化,使人们能够认识到一个新名词可以用于其他各种各样的上下文中。从我第一次听到blicket这个词被用作宾语,我猜到它会适合各种各样的框架。而且我也可以生成和解释这样的句子,而不需要进一步的训练。blicket是否与我所听到的其他词语的音韵类似,或者我将这个词作为主语或宾语都不重要。如果大多数机器学习范式都存在这种问题,那么我们应该在大多数ML范式中遇到问题。
我是否“公平”?是,也不是。的确,我正在要求神经网络做一些违背假设的事情。
例如,一个神经网络倡导者可能会说,“嘿,等一下,在你的逆向例子中,你的输入空间有三个维度,代表左边的二进制数字,中间的二进制数字和最右边的二进制数字。最右边的二进制数字在训练中仅为零;当你到达那个位置时,网络无法知道该做什么。”
例如,康奈尔大学博士后Vincent Lostenlan说:“我不明白你在3.11.上试图证明什么。f是在输入空间中的(n-1)维超立方体的顶点上训练的恒等函数。你怎么会对DNN,甚至是任何ML模式没有“泛化”到第n个dim而感到惊讶呢?
Dietterich基本上提出了同样的观点,更为简洁:“马库斯抱怨DL不能推断,但没有任何方法可以推断。”
尽管对深度学习来说,odds-and-evens很难实现,这种情况下二人的观点都是都是正确的。但对于更大的问题来说,他们的观点是是错误的,原因有三。
首先,人不可能无法推断。
对于那些深深地沉浸在当代机器学习中的人来说,我的几率问题似乎是不公平的,因为某个维度(包含最右边数字1的那个维度)在培训体系中没有被说明。但是,当你作为一个人,看看我上面的例子,你将不会受到训练数据中的这个特定差距的阻碍。你甚至不会注意到它,因为你的注意力是在更高层次的规则。
人们经常按照我所描述的方式进行推断,比如从上面给出的三个训练样例中识别字符串反转。从技术上讲,这是外推,而你刚刚做到了。在《Algebraic Mind》中,我将这种特定的外推法称为在训练样例空间之外推广普遍量化的一对一映射。在一个领域,如果我们要赶上人类学习,即使这意味着要改变我们的假设,我们迫切需要解决这个挑战。
现在可以合理地反对,这不是一个公平的战斗:人类在推广这样的映射时显然依赖于先验知识。
但从某种意义上说,神经网络并没有一个好方法,把正确的先验知识结合到这个地方。正是因为这些网络没有一种方法来结合诸如“无限类的所有元素的许多概括”等先验知识,那些缺乏变量操作的神经网络会失败。正确的先验知识将允许神经网络获取并表示普遍量化的一对一映射。除了某些有限的方式,标准神经网络不能代表这种映射。
其次,现在的深度学习或其他方式不能用我所描述的方式进行外推;其他的架构可能再次处于波涛汹涌的水中,但这并不意味着我们不应该试图游到岸边。如果想要达到通用人工智能,我们必须解决这个问题。
第三,目前没有任何进行推断的系统被证明是错误的。已经有ML系统可以推断出我所描述的至少一些功能,你可能自己就有一个:Microsoft Excel,它的Flash Fill功能(Gulwani,2011)。由一个与机器学习非常不同的方法支持,它可以做一些外推,例如,尝试输入一系列(十进制)数字1,11,21,看看是否系统可以通过Flash Fill推断到序列(101)中的第十一项。
扰乱警报,即使在百位数字的训练维度中没有正面的例子,它也可以完全如您所愿。系统从例子中学习你想要的功能并推断它。这简直是小菜一碟。任何深度学习系统都可以通过三个训练实例来做到这一点。
只有那些可能这样做的也许是在变量上运行的混合体,这与大多数人认为与深度学习相关的那种典型卷积神经网络是完全不同的。
把所有这一切做得非常不同,一个粗略的方法就是考虑我们今天大多数ML系统的位置(注7),它们的目的并不是为了“思考”。人类比当代人工智能更擅长思考问题,我不认为有人会质疑这一点。
但是,如果微软能够在狭窄的语境下进行这种推断,而没有机器可以处理类似人类的广度,那么想要达到AGI,机器学习工程师真正应该去做的就是要去解决这个问题。
10. 领域里每个人都已经知道这一点了。没有什么新东西
很显然不是每个人都知道,如前所述,有很多批评者认为我们还不知道深度学习的局限性,还有些人认为深度学习可能会有一些局限,但目前我们还没有发现。
但话说回来,我从来没有说过我的观点是全新的,我提出的几乎所有论点,都引用了其他学者,他们独立地得出了类似的结论。
这一点确实如此;文献综述是不完整的。我没能引用Shanahan的深度符号强化(Garnelo,Arulkumaran,&Shanahan,2016);我也无法相信,我竟然忘了Richardson和Domingos(2006)的马尔科夫逻辑网络。要是我当时引用Evans和Edward Grefenstette(2017)就好了,那是DeepMind的一篇很好的论文。此外,还有Smolensky的张量微积分工作(Smolensky等,2016),以及Noah Goodman(Goodman,Mansinghka,Roy,Bonawitz &Tenenbaum,2012)各种形式的归纳编程(Gulwani等,2015)和概率编程。所有这些努力都将规则和网络联系在一起。
还有乔丹·波拉克(Jordan Pollack)等先驱(Smolensky et al.,2016),Forbus和Gentner(Falkenhainer,Forbus &Gentner,1989),以及Hofstadter和Mitchell(1994)的类比工作,还有其他许多人。我相信我还有更多的东西可以引用。
总的来说,我试图做到有代表性而不是全面,但我原本可以做得更好。
我很犹豫要不要提出这一点,但是有很多人都提到了这个问题,包括一些知名的专业人士。正如Ram Shankar所说:“作为一个社区,我们必须把批评限制在科学和基于贡献的讨论之内。”真正重要的不是我的资格(我相信事实上我确实有资格写),而是论证的有效性。
我的论点要么是对的,要么不是。
13、回复:Socher的树RNN(Tree-RNN)又如何?
我已经写信给他,希望能对当前状况有更好的理解。我也在私下里推动几个团队尝试Lake和Baroni(2017)提出的方法。
Pengfei等人(2017)也提出了一些很有意思的讨论。
14、你应该更批判地审视深度学习
并没有很多人提到这一点,话也不是这样说的,但是,有些人在私下里跟我提过,与上述观点十分类似。
有一位同事向我指出,关于未来预测,现在或许存在一些严重的问题
现在有种感觉是,成功的速度会呈指数级快速增长……更有可能的情况是,我们身处一个宽阔的平台,看见很多低垂的果实,但是一旦这些果实消失,向深层推理的进展将会变慢。此外,现在我们能以95%的精确度识别猫,但还不清楚为什么凭此人们就该认为,我们可以很容易地实现AGI,解决道德,伦理等难题。前一类问题可能存在于更为复杂的空间中。
同时,这位同事还补充说:
研究人员在某些领域过于急切地宣布成果。例如图像处理:我们已经发现了一类问题,计算机十分擅长,但同时计算机使用的算法可能遭到对抗性攻击。而且,当计算机出错的时候,往往错得莫名其妙,现实与结果大相径庭。而人类则不同,在街上行驶时,我可能会把一棵树错看成一个灯柱,但我错得不会太离谱(因为我深深地理解了意义和场景)。确实,这些局限性经常得到报道,但也有这样一个基本观点:由于ImageNet的结果,计算机在图像识别方面比人更加厉害。
机器学习研究者和作家Pedro Domingos也指出,现在的深度学习还存在另一些我之前没有提到的局限:
像其他灵活的监督式学习方法一样,深度学习系统可能是不稳定的,因为稍微改变训练数据,就可能导致最终模型的巨大变化。
系统可能需要大量的数据,哪怕实际上少一些也足够。(特别是数据增强,是非常昂贵的,人类并不需要这一点。)
系统可能很脆弱:对数据的小改动就会导致灾难性的失败。例如,在数字数据集中翻转黑白)(Hosseini,Xiao,Jaiswal &Poovendran,2017)。
Ribeiro,Singh和Guestrin(2016)发现,从ImageNet提取的数据集中,狼与狗之间的高度准确的区分结果是检测狼的图像中的白色雪块得到的。因此,系统并不像我们想象的那样准确。
在机器学习历史上,到目前为止,每一种占据主导地位的范式(比如上世纪80年代的神经网络,90年代的贝叶斯学习和2000年代的Kernel方法),都倾向于主导大约十年的时间。
正如Domingos指出的那样,谁也不能保证类似的流行和衰退不会重演。神经网络先后几次起起落落,最早从1957年罗森布拉特的第一个感知机那时起。我们不应该把周期性的热度解读为解决智能的完整方案,至少在我看来,要解决智能还需要几十年的时间。
如果想要实现AGI,我们更应随时要求自己,敏锐地意识到我们所面临的挑战。
原文链接:https://medium.com/@GaryMarcus/in-defense-of-skepticism-about-deep-learning-6e8bfd5ae0f1



点击下方“阅读原文”了解燃气报警云平台 ↓↓↓