Mongdb分片实战三(性能和优化)
插入、查询和更新
插入:MongoDB会根据片键和conifg中的信息写入到指定的分片上。
读取:以下内容摘抄自《深入学习MongoDB》

关于读取:上一节故障恢复中已经有所验证。
更新:如果要更新单个文档一定要在片键中使用片键(update的第一个参数)。我们现在OSSP10.bizuser(已经在_id上进行哈希分片)中插入一条记录:
1. mongos> use OSSP10 2. switched to db OSSP10 3. mongos> db.bizuser.insert({"Uid":10001,"Name":"zhanjindong","Age":23}) 4. db.bizuser.find({"Name":"zhanjindong"}) 5. { "_id" : ObjectId("5160dd378bc15cdb61a131fc"), "Uid" : 10001, "Name" : "zhanjindong", "Age" : 23 }
尝试根据Name来更新这个文档会得到一个错误:
1. mongos> db.bizuser.update({"Name":"zhanjindong"},{"$set":{"Sex":0}}) 2. For non-multi updates, must have _id or full shard key ({ _id: "hashed" }) in query
根据片键来更新则不会有任何问题:
1. mongos> db.bizuser.update({"_id":ObjectId("5160dd378bc15cdb61a131fc")},{"$set":{"Sex":0}}) 2. mongos> db.bizuser.find({"Name":"zhanjindong"}) 3. { "Age" : 23, "Name" : "zhanjindong", "Sex" : 0, "Uid" : 10001, "_id" : ObjectId("5160dd378bc15cdb61a131fc") }
但是批量更新中可以用任何条件:
1. mongos> db.bizuser.insert({"Uid":10002,"Name":"dsfan","Age":23}) 2. mongos> db.bizuser.insert({"Uid":10003,"Name":"junling","Age":25}) 3. mongos> db.bizuser.update({"Age":23},{"$set":{"Sex":1}},false,true) 4. mongos> db.bizuser.find({"Age":23}) 5. { "Age" : 23, "Name" : "zhanjindong", "Sex" : 1, "Uid" : 10001, "_id" : ObjectId("5160dd378bc15cdb61a131fc") } 6. { "Age" : 23, "Name" : "dsfan", "Sex" : 1, "Uid" : 10002, "_id" : ObjectId("5160e2af8bc15cdb61a131fd") }
之所以更新单个文档会有这个强制限制是因为如果不指定片键,MongoDB会将更新操作路由到所有分片上,则无法保证更新操作在整个集群中只操作了一次(不同的分片上可能存在相同Uid的数据),指定片键后,更新操作只会路由到某一个分片上,MongoDB能保证只会更新在这个分片找到的第一个符合条件的文档。下面提到的唯一索引问题和这个问题本质是一样的。批量更新没有这个限制很好理解。
排序:在需要调用sort()来查询排序后的结果的时候,以分片Key的最左边的字段为依据,Mongos可以按照预先排序的结果来查询最少的分片,并且将结果信息返回给调用者。这样会花最少的时间和资源代价。 相反,如果在利用sort()来排序的时候,排序所依据的字段不是最左侧(起始)的分片Key,那么Mongos将不得不并行的将查询请求传递给每一个分片,然后将各个分片返回的结果合并之后再返回请求方。这个会增加Mongos的额外的负担。
片键和索引

所有分片的集合在片键上都必须建索引,这是MongoDB自动执行的,所以如果选择某个字段作为片键但是基本不在这个字段做查询那么等于浪费了一个索引,而增加一个索引总是会使得插入操作变慢。
唯一索引问题 如果集群在_id上进行了分片,则无法再在其他字段上建立唯一索引:

1. mongos> db.bizuser.ensureIndex( { "Uid": 1 }, { unique: true } ) 2. { 3. "err" : "can't use unique indexes with sharding ns:OSSP10.bizuser key: { Uid: 1.0 }", 4. "code" : 10205, 5. "n" : 0, 6. "ok" : 1 7. }
之所以出现这个错误是因为MongoDB无法保证集群中除了片键以外其他字段的唯一性(验证了CAP理论),能保证片键的唯一性是因为文档根据片键进行切分,一个特定的文档只属于一个分片,MongoDB只要保证它在那个分片上唯一就在整个集群中唯一。
如果实现分片集群上的文档唯一性一种方法是在创建片键的时候指定它的唯一性:
1. mongos> use admin 2. switched to db admin 3. mongos> db.runCommand({"enablesharding":"test"}) 4. mongos> db.runCommand({"shardcollection":"test.users","key":{"Uid":1},unique:true}) 5. mongos> use test 6. switched to db test 7. mongos> db.users.insert({"Uid":1001}) 8. mongos> db.users.insert({"Uid":1001}) 9. E11000 duplicate key error index: test.users.$Uid_1 dup key: { : 1001.0 }
事实上就是建立了一个唯一索引:
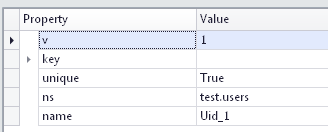
Note:更多关于分片集群上唯一索引问题参见《MongoDB Manual》page468。
哈希索引:



哈希索引支持使用任何单个字段包括内嵌文档,但是不能使用复合的字段,因此创建哈希索引的时候也只能指定一个字段:
1. mongos> db.runCommand({"shardcollection":"mydb.mycollection","key":{"Uid":"hashed","Name":"hashed"}}) 2. { 3. "ok" : 0, 4. "errmsg" : "hashed shard keys currently only support single field keys" 5. }
片键的选择
片键的选择对于整个分片集群的性能至关重要,上一节对分片集群中的读、写和更新操作已经做了说明,选择片键的时候要考虑到读自身应用的读写模式和新增分片的情况。

小基数片键:如果某个片键一共只有N个值,那最多只能有N个数据块,也最多只有个N个分片。则随着数据量的增大会出现非常大的但不可分割的chunk。如果打算使用小基数片键的原因是需要在那个字段上进行大量的查询,请使用组合片键,并确保第二个字段有非常多的不同值。
1. mongos> db.runCommand({"enablesharding":"mydb"}) 2. db.runCommand({"shardcollection":"mydb.mycollection","key":{"x":1}}) 3. mongos> use mydb 4. switched to db mydb 5. mongos> var arrayObj = new Array("A","B","C") 6. mongos> for(i=0;i<333333;i++){ db.mycollection.insert({"x":arrayObj[i%3],"y":"zhanjindong2","Age":13,"Date":new Date()}); }
无论再插入多少条数据,我们查看一下config.chunks会发现只会有三个块,三个块最多只能使用三个分片:
1. { "_id" : "mydb.mycollection-x_MinKey", "lastmod" : { "t" : 2, "i" : 0 }, "lastmodEpoch" : ObjectId("51613a843999888c2cd63f41"), "ns" : "mydb.mycollection", "min" : { "x" : { "$minKey" : 1 } }, "max" : { "x" : "A" }, "shard" : "shard0001" } 2. { "_id" : "mydb.mycollection-x_\"A\"", "lastmod" : { "t" : 3, "i" : 0 }, "lastmodEpoch" : ObjectId("51613a843999888c2cd63f41"), "ns" : "mydb.mycollection", "min" : { "x" : "A" }, "max" : { "x" : "C" }, "shard" : "shard0002" } 3. { "_id" : "mydb.mycollection-x_\"C\"", "lastmod" : { "t" : 3, "i" : 1 }, "lastmodEpoch" : ObjectId("51613a843999888c2cd63f41"), "ns" : "mydb.mycollection", "min" : { "x" : "C" }, "max" : { "x" : { "$maxKey" : 1 } }, "shard" : "shard0000" }
递增的片键:使用递增的分片的好处是数据的“局部性”,使得将最新产生的数据放在一起,对于大部分应用来说访问新的数据比访问老的数据更频繁,这就使得被访问的数据尽快能的都放在内存中,提升读的性能。这类的片键比如时间戳、日期、ObjectId、自增的主键(比如从sqlserver中导入的数据)。但是这样会导致新的文档总是被插入到“最后”一个分片(块)上去,这种片键创造了一个单一且不可分散的热点,不具有写分散性。
随机片键:随机片键(比如MD5)最终会使数据块均匀分布在各个分片上,一般观点会以为这是一个很好的选择,解决了递增片键不具有写分散的问题,但是正因为是随机性会导致每次读取都可能访问不同的块,导致不断将数据从硬盘读到内存中,磁盘IO通常会很慢。
举个例子:比如mydb.mycollection集合记录下面这样的用户信息,Uid是一个比较随机的值:
{ Uid:12313477994, Name:zhanjindong, Age:23, CreatedTime:2013-04-08 15:23:24.122 }
如果我们对Uid进行分片,那么同一分钟创建的用户信息可能被写入到了不同的块上(通常在不同的分片上),这有很好的分散性。但如果我们想根据时间来查找这一分钟产生的所有新用户,则mongos必须将查询操作路由给所有的分片的多个块上。但如果我们根据时间进行分片,那么这一分钟内新增用户可能都写入到一个块中,那么上面的查询操作只需要路由给一个分片上的一个块就完成了。
组合片键:一个理想的片键是同时拥有递增片键和随即片键的优点,这点很难做到关键是要理解自己的数据然后做出平衡。通常需要组合片键达到这种效果:
准升序键加搜索键 {coarselyAscending:1,search:1}
其中coarselyAscending每个值最好能对应几十到几百个数据块(比如以月为单位或天为单位),serach键应当是应用程序中通常都会依据其进行查询的字段,比如GUID。
注意:serach字段不能是升序字段,不然整个复合片键就下降为升序片键。这个字段应该具备非升序、分布随机基数适当的特点。
事实上,上面这种复合片键中的第一个字段保证了拥有数据局部性,第二字段则保证了查询的隔离性。同时因为第二个字段具备分布随机的特性因此又一定程度的拥有随机片键的特点。
哈希片键:对于哈希片键的选择官方文档中有很明确的说明:

选择哈希分片最大好处就是使得数据在各个节点分布比较均匀。2.2.5 Hased Shaeding一节对哈希片键的使用有简单的测试。
注意:建立哈希片键的时候不能指定唯一:
1. mongos> db.runCommand({"shardcollection":"OSSP10.Devices","key":{"DeviceId":"hashed"},unique:true}) 2. { "ok" : 0, "errmsg" : "hashed shard keys cannot be declared unique." }
基于范围vs基于哈希
什么时候选择基于范围的分片,什么时候选择基于哈希的分片呢?官方文档的说明很少:

基于哈希的分片通常可以使得集群中数据分布的更加均匀。但是考虑具体应用情况可能有所不同,下面是引用10gen的产品市场总监Kelly Stirman的一段话:
当使用基于范围的分片,如果你的应用程序基于一个分片键范围请求数据,那么这些查询会被路由到合适的分片,通常只有一个分片,特殊情况下可能有一些分片。在一个使用了基于哈希分片的系统中,同样的查询会将请求路由到更多的分片,可能是所有的分片。理想情况下,我们希望查询会被路由到一个单独的分片或者尽可能少的分片,因为这样的扩展能力要比将所有的查询路由到所有的分片好。因此,如果你非常理解自己的数据和查询,那么基于范围的分片可能是最好的选择。
出处:http://www.infoq.com/news/2013/03/mongodb-2-4
总结:对MongoDB 单条记录的访问比较随机时,可以考虑采用哈希分片,否则范围分片可能会更好。

Balancer
小的chunkSize能保证各个分片数据分布更均匀,但导致迁移更频繁。MongoDB为了尽量减少对性能的影响对块迁移的算法有很多的优化措施:2.2.2节对Migration Threshold有简单的说明,另外balancer进程能聪明的避开整个集群高峰时期。
可以定时的执行数据迁移:
1. use config 2. db.settings.update({ _id : "balancer" }, { $set : { activeWindow : { start : "23:00", stop: "6:00"
删除定时数据迁移设置:
1. use config 2. db.settings.update({ _id : "balancer" }, { $unset : { activeWindow : true } })
开启和关闭balancer:
1. sh.startBalancer() 2. sh.stopBalancer()
如果正在有数据进行迁移的话,stopBalancer会等待迁移结束,可以通过下面的方式查看当前是否有迁移在进行:
1. use config 2. while( db.locks.findOne({_id: "balancer"}).state ) { 3. print("waiting..."); sleep(1000);
Note:更多关于balancer信息参见《MongoDB-Manual》page 455
手动分片
MongoDB自动分片都是先从一个分片上的一个块开始的,然后通过不断的分裂和迁移来达到数据的切分和平衡,依赖机器自动执行的好处是简单,但是代价就是性能(虽然balancer已经做了很多优化)。因此MongoDB允许进行手动切分,手动切分有下面两个步骤(官方示例):
1、用split命令对空集合进行手动的切分。
1. mongos> use admin 2. switched to db admin 3. mongos> db.runCommand({"enablesharding":"myapp"}) 4. mongos> db.runCommand({"shardcollection":"myapp.users","key":{"email":1}}) 5. for ( var x=97; x<97+26; x++ ){ 6. for( var y=97; y<97+26; y+=6 ) { 7. var prefix = String.fromCharCode(x) + String.fromCharCode(y); 8. db.runCommand( { split : "myapp.users" , middle : { email : prefix } } ); 9. } 10. }
注意:

最好只对一个空的集合进行预分割,如果对存在数据的集合进行预分割,MongoDB会先进行自动分割,然后在尝试进行手动的分割。这可能导致大规模的分割和低效的平横。
2、利用moveChunk命令手动的移动分割的块:
1. var shServer = [ "sh0.example.net", "sh1.example.net", "sh2.example.net", "sh3.example.net", "sh4.example.net" ]; 2. for ( var x=97; x<97+26; x++ ){ 3. for( var y=97; y<97+26; y+=6 ) { 4. var prefix = String.fromCharCode(x) + String.fromCharCode(y); 5. db.adminCommand({moveChunk : "myapp.users", find : {email : prefix}, to : shServer[(y-97)/6]}) 6. } 7. }
或者利用balancer自动平衡。
要很好进行手动的切分必须了解片键的范围,如果片键是一个随机值比如哈希分片,则很难进行手动的预分割,其次及时进行了预分割随后插入数据块分裂和迁移(没关闭balancer)依然会存在。
结论:预分割和手动分片适合于将片键范围确定的数据初始化到分片集群中。
其他
journal
如果机器是32位的话在配置分片集群启动shard的时候跟上—journal参数。因为64位默认是开启journal的,32位没有。
NUMA CPU架构问题
NUMA是多核心CPU架构中的一种,其全称为Non-Uniform MemoryAccess,简单来说就是在多核心CPU中,机器的物理内存是分配给各个核的。2.1.1的表中可以看到192.168.71.43这台机器的CPU架构正是NUMA。
在NUMA架构的机器上启动mongodb进程需要特别注意。我们先以正常的方式启动mongodb,然后登录,如下:
3. ./bin/mongod --dbpath data/ --logpath log/mongodb.log –fork 4. ./bin/mongo
你会看到类似下面的警告信息:
1. . Server has startup warnings: 2. Mon Apr 1 20:49:25.900 [initandlisten] 3. Mon Apr 1 20:49:25.900 [initandlisten] ** WARNING: You are running on a NUMA machine. 4. Mon Apr 1 20:49:25.900 [initandlisten] ** We suggest launching mongod like this to avoid performance problems: 5. Mon Apr 1 20:49:25.900 [initandlisten] ** numactl --interleave=all mongod [other options] 6. Mon Apr 1 20:49:25.900 [initandlisten]
按照提示我们应该向下面这样启动mongodb进程,在启动命令前加上numactl --interleave选项:
1. numactl --interleave=all ./bin/mongod --dbpath data/ --logpath log/mongodb.log --fork
这时再登录mongodb就不会再有警告信息了。
以上只是就问题解决问题,至于在NUMA架构的CPU上非正常启动mongodb会带来什么样的性能影响还没做验证,网上可以搜到一些别人使用的经验。官方的文档(参看MongoDB Documentation, Release 2.4.1 12.8.1 MongoDB on NUMA Hardware)中有如下说明:

简单做下解释,NUMA架构中每个核访问分配给自己的内存会比分配给其他核内存要快,有下面几种访问控制策略:
- 缺省(default):总是在本地节点分配(分配在当前进程运行的节点上);
- 绑定(bind):强制分配到指定节点上;
- 交叉(interleave):在所有节点或者指定的节点上交织分配;
- 优先(preferred):在指定节点上分配,失败则在其他节点上分配。
但是目前mongodb在这种架构下工作的不是很好,--interleave=all就是禁用NUMA为每个核单独分配内存的机制。