机器学习与深度学习的起点——线性回归
从此文开始,本专栏将推出一系列深度学习与图像处理相关的教程文章。注重原理精讲和代码实现。实现框架将重点选择Tensorflow或Pytorch。
什么是机器学习?
传统的有监督机器学习可以归结为这样一个过程:
- 获取标记数据对 (x,y) ( x , y ) 。
- 建立含参模型,描述数据对 (x,y) ( x , y ) 之间的关系: ŷ =f(x;θ) y ^ = f ( x ; θ ) 。其中 θ θ 是待学习的参数。
- 利用众多标记数据对 {(xi,yi)|i=1,⋯,N} { ( x i , y i ) | i = 1 , ⋯ , N } 通过梯度下降法训练得到合适的参数 θ θ ,使得估计误差最小。也就是:
minθ‖ŷ −y‖22 min θ ‖ y ^ − y ‖ 2 2
机器学习还包括半监督、无监督和强化学习等,这里暂不考虑。
线性回归原理
线性回归问题是最简单机器学习问题。它的任务是:给定一个线性模型和数据对,求解出模型的最优参数。
设有向量变量 x∈Rm x ∈ R m , y∈Rn y ∈ R n ,权重矩阵 W∈Rm×n W ∈ R m × n ,偏倚向量 b∈Rn b ∈ R n ,他们服从线性模型
y=Wx+b(8) (8) y = W x + b
线性回归问题是:给定多组观察数据 (xi,yi),i=1,⋯,p ( x i , y i ) , i = 1 , ⋯ , p ,求权重矩阵 W W 和偏倚向量 b b 。
为了将多组输入数据写入一个模型中,令 X=(xT1,⋯,xTp)T X = ( x 1 T , ⋯ , x p T ) T , Y=(yT1,⋯,yTp)T Y = ( y 1 T , ⋯ , y p T ) T , B=(bT,⋯,bT)T B = ( b T , ⋯ , b T ) T ,则线性模型估计输出为
Ỹ =XW+B(9) (9) Y ~ = X W + B
故线性回归问题归结于求解如下优化问题
minW,b‖Y−Ỹ ‖22(10) (10) min W , b ‖ Y − Y ~ ‖ 2 2
Tensorflow实现
用Tensorflow估计线性回归模型的参数:
# coding=UTF-8
from __future__ import print_function
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 运算设备 cpu
device = "/cpu:0"
# 预设的模型参数
weight = 5
bias = 1.9
# 根据线性模型生成训练数据 trX 和 trY
trX = np.linspace(-1, 1, 101)
trY = weight * trX + bias + np.random.rand(*trX.shape) * 0.33 # 对 trY 添加高斯噪声
# tf定义线性模型
def model(X, w, b):
return tf.multiply(X, w) + b
# tf定义占位符,用于输入数据,训练或测试
X = tf.placeholder("float")
Y = tf.placeholder("float")
# tf模型变量(也就是需要估计的参数)
w = tf.Variable(0.0, name="weights")
b = tf.Variable(0.0, name="bias")
y_model = model(X, w, b)
# tf损失函数
cost = tf.reduce_mean(tf.square(Y - y_model))
# tf优化算子:使用梯度下降法,步长0.01
train_op = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
# 打包训练数据为二元组列表
tdata = zip(trX, trY)
# 开启tf会话
with tf.Session() as sess:
# 指定运算设备 (CPU或GPU)
with tf.device(device):
# 初始化所有tf变量
tf.global_variables_initializer().run()
# 迭代优化 30 个Epoch
for i in range(30):
# 迭代一个Epoch
for (x, y) in zip(trX, trY):
# 用数据 x,y 进行一次梯度下降
sess.run(train_op, feed_dict={X:x, Y: y})
# 打印当前的损失函数值
print(i, sess.run(cost, feed_dict={X:trX, Y:trY}))
# 打印对模型变量估计的结果
estimated_w = sess.run(w)
estimated_b = sess.run(b)
print("estimated_w = %f, estimated_b = %f\n" % (estimated_w, estimated_b)) # print estimated result of w
# 用估计的参数画出模型拟合数据的效果
modelY = estimated_w * trX + estimated_b
plt.figure()
plt.plot(trX, trY, 'ro')
plt.plot(trX, modelY, 'b-')
plt.show()实验效果
程序运行的输出为:
0 4.06233
1 1.36456
2 0.381636
3 0.106645
4 0.0343513
5 0.0155213
6 0.0105695
7 0.00923523
8 0.00885943
9 0.00874572
10 0.00870772
11 0.00869348
12 0.00868756
13 0.00868489
14 0.00868362
15 0.008683
16 0.00868268
17 0.00868254
18 0.00868246
19 0.00868242
20 0.0086824
21 0.00868239
22 0.00868237
23 0.00868237
24 0.00868237
25 0.00868237
26 0.00868237
27 0.00868237
28 0.00868237
29 0.00868237
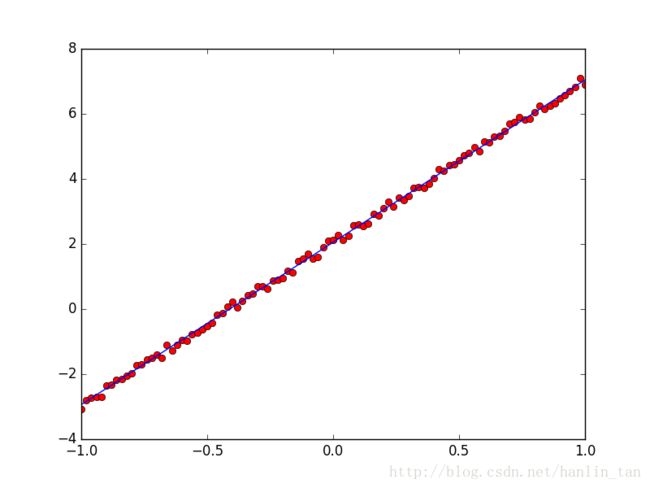
estimated_w = 4.989621, estimated_b = 2.052838可以看到,随着迭代轮次的增加,模型的估计误差稳定在 0.00868 0.00868 左右。预测的参数值 w=4.99,b=2.05 w = 4.99 , b = 2.05 与设定的参数值 5,1.9 5 , 1.9 接近。
用估计的 W,b W , b 画出的直线与原始数据放在一起的效果:
Pytorch实现
同样的问题,我们还可以用Pytorch更简洁地实现:
# coding=UTF-8
from __future__ import print_function
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.optim as optim
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
# 运算设备 cpu
device = "/cpu:0"
# 预设的模型参数
weight = 5
bias = 1.9
# 根据线性模型生成训练数据 trX 和 trY
trX = np.linspace(-1, 1, 101)
trY = weight * trX + bias + np.random.rand(*trX.shape) * 0.33 # 对 trY 添加高斯噪声
def get_wb(model):
for (i, param) in enumerate(model.parameters()):
if i == 0:
estimated_w = param.detach().numpy()[0,0]
else:
estimated_b = param.data.item()
#print('e_w : ', estimated_w)
#print('e_b : ', estimated_b)
return estimated_w, estimated_b
# pytorch定义线性模型
class LinearModel(nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.linear = nn.Linear(in_features=1, out_features=1)
def forward(self, x):
y = self.linear(x)
return y
model = LinearModel()
# 定义损失函数为 MSE
loss_func = F.mse_loss
# 定义优化算子
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 打包训练数据为二元组列表
tdata = zip(trX, trY)
# 迭代优化 30 个Epoch
for i in range(30):
# 迭代一个Epoch
for (x, y) in zip(trX, trY):
# 用数据 x,y 进行一次梯度下降
# 将 x, y 变为变量
x = Variable(torch.from_numpy(np.asarray([x]))).float()
y = Variable(torch.from_numpy(np.asarray([y]))).float()
output = model(x)
# 计算误差
loss = loss_func(output, y)
# 梯度清零
optimizer.zero_grad()
# 计算梯度
loss.backward()
# 反向传播地梯度下降
optimizer.step()
# 打印当前的损失函数值和 w, b
estimated_w, estimated_b = get_wb(model)
print('iter : ', i, 'loss : ', loss.data.item(), "w, b = ", estimated_w, estimated_b)
# 用估计的参数画出模型拟合数据的效果
estimated_w, estimated_b = get_wb(model)
modelY = estimated_w * trX + estimated_b
plt.figure()
plt.plot(trX, trY, 'ro')
plt.plot(trX, modelY, 'b-')
plt.show()本文说明了如何用Tensorflow、Pytorch完成机器学习中最简单的一个任务:线性回归。为之后更复杂的深度学习问题打下基础。
微信公众号同步更新

TomHeaven的博客,欢迎关注 :)