java实战小技巧
Java作为一个生态庞大的语言,在开发过程中,有很多封装好的类或者工具可以给我们提供事半功倍的效果,本文主要总结了开发过程中的一些小细节,通过一些小技巧来提升我们的开发效率,另本文档内容基于jdk1.8。
- java的空判断
java的common包或者spring的org.springframework.util都封装了我们可以直接使用的字符串或集合空判断,一般开发可以统一一种方式进行空判断,可以增加团队代码的可读性和课维护性
当然,既然提到了jdk1.8,那自然绕不开Optional
当我们想判断一个对象是否为空则可以用这样的方式
Optional.ofNullable(userServiceProxy.findUserHigherLevel(userCode)).orElse("")Optional有很多高级用法,主要用在判断空的嵌套层次比较深的时候超级方便,如:
if (user != null) { Address address = user.getAddress(); if (address != null) { Country country = address.getCountry(); if (country != null) { String isocode = country.getIsocode(); if (isocode != null) { isocode = isocode.toUpperCase(); } } }}使用Option后就可以缩减为
String result = Optional.ofNullable(user) .flatMap(User::getAddress) .flatMap(Address::getCountry) .map(Country::getIsocode) .orElse("default");- swagger-bootstrap-ui
swagger大家都会用,但是大家往往被它那ugly的界面吓退,但是大家引入这个包后,你会爱上swagger
com.github.xiaoymin
swagger-bootstrap-ui
${swagger.ui.version}
加之前
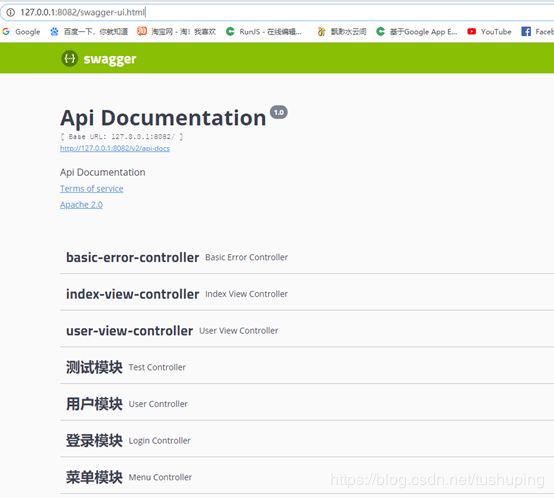
加之后
可读性和便捷性瞬间提升一大截
- excel导入导出
大多数的系统都会有excel导入导出功能,下面轮到easypoi上场了
cn.afterturn
easypoi-spring-boot-starter
${easypoi.version}
简单的注解
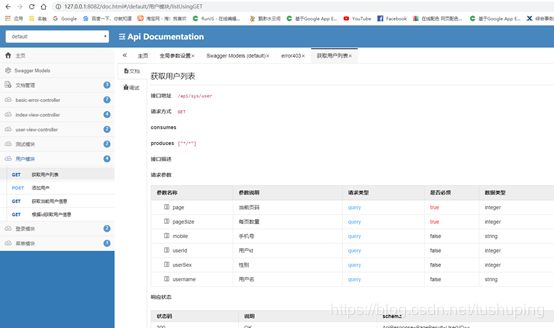
就能直接映射导入和导出的对象集合,再也不用自己去封装了
- 对象拷贝
Java里一般使用有浅拷贝和深拷贝两种,但是大部分使用场景都是需要深拷贝,深拷贝的大多数解决方案都是通过将对象进行序列化或者通过反射进行赋值,性能损耗比较严重,接下来出场的是orika:
ma.glasnost.orika
orika-core
${orika-core.version}
orika底层采用了javassist类库生成Bean映射的字节码,之后直接加载执行生成的字节码文件,因此在速度上比使用反射进行赋值会快很多,在orika的世界里面,万物皆可拷贝,无论你是对象或者list集合,一条代码全解决,非常适用于dto转vo等场景
- stream处理
Java8开始提供了stream方便我们出对象,集合等快捷操作,下面举几个栗子
1)从list中拿到某一列的集合,在查询数据库的时候经常用到获取某个集合的id然后使用in的方式进行查询,使用stream可以这样
List userCodes = bonuses.stream().map(StoreUserBonus::getUserCode).distinct().collect(Collectors.toList()); 2)将list转为以id为key,某个属性为value的map,此功能主要使用在对数据库多个表的返回
数据进行拼接
Map starVolume = storeStarList.stream().collect(Collectors.toMap(StoreStar::getId, StoreStar::getBaseUser, (v1, v2) -> v2)); 此处注意一定要·加上(v1, v2) -> v2,因为在jdk1.8中,如果key值一样,就是报空指针错误,需要申明用后面的新值覆盖之前的值,当然jdk9起,已经修复了这个问题
Steam功能超级强大,除了上述的转换功能,stream还提供了集合过滤,排序,比较,运算等功能,可以自己去深究
- guava工具包
Guava是一种基于开源的Java库,其中包含谷歌正在由他们很多项目使用的很多核心库。这个库是为了方便编码,并减少编码错误。这个库提供用于集合,缓存,支持原语,并发性,常见注解,字符串处理,I/O和验证的实用方法。
里面的·方法都是经过谷歌验证,性能可靠的工具,比如BloomFilter等,大家可以多使用这里的方法减少重复代码的编写。
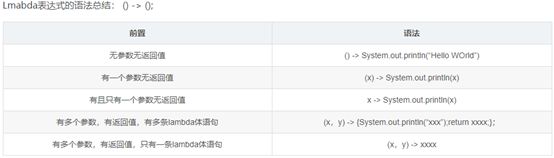
- Lambda
废话不多说,直接上代码,比如起一个线程
不适用lambda前:
new Thread(new Runnable() {@Overridepublic void run() { System.out.println("Hello from thread");}}).start();使用后:
new Thread(() -> System.out.println("Hello from thread")).start();大大简化了代码的编写,当然lambda配合stream才是正确的打开方式
details.stream()
.filter(d -> (StringUtils.isBlank(d.getTemplateLineCode())))
.collect(Collectors.toList());()-> expression简化方法的编写
- AutoCloseable
对于io的代码我们一般这么写:
public String getText(File file){ FileInputStream fis = null; try { fis = new FileInputStream(file); byte[] b = new byte[(int) file.length()]; fis.read(b); return new String(b, "UTF-8"); } catch (IOException e) { e.printStackTrace(); } finally { if (fis != null) { try { fis.close(); } catch (IOException e) { e.printStackTrace(); } } } return "";}从jdk起增加了AutoCloseable类,所有流处理的类都实现了它
如输入流
![]()

所以,jdk1.7以后我们可以放弃处理关闭流文件,只需要try即可
public String getText(File file){ try(FileInputStream fis = new FileInputStream(file)) { byte[] b = new byte[(int) file.length()]; fis.read(b); return new String(b, "UTF-8"); } catch (IOException e) { e.printStackTrace(); } return ""; }- 日期工具
Jdk1.8增加了日期工具LocalDate、LocalTime、LocalDateTime,保证了线程安全的同时,易用性相对于Date有了很大的提升,比如往前推几天/ 往后推几天/ 计算某年是否闰年/ 推算某年某月的第一天、最后一天、第一个星期一等等,只需要调用一个方法就可以达到目的,所以关于日期处理最好从这些类出发。