python3使用scrapy爬取数据保存到mysql
写这篇文章的原因是因为牛人们总结的scrapy爬虫效果都很厉害的样子(http://www.bjhee.com/scrapy.html和https://segmentfault.com/a/1190000008135000),但是照着操作却总是不这么顺利(要么因为python3不兼容/要么因为过时了接口都变了/要么就是数据库本地没有/要么爬取的网站不好使了–此文章首次编辑于2018-2-25,一段时间后请大家继续参考官方文档进行修改),而且我个人比较习惯用mysql数据库(官方举例用MongoDB),因此爬取的数据想保存到mysql中,因此结合网友们的智慧对官方demo做了一些修改。
为了更好的使用爬虫的api–保证不过时,详细使用流程参考官方文档 https://docs.scrapy.org/en/latest/intro/tutorial.html ,此处继续采用 http://quotes.toscrape.com/ 网站作为典型(因为结构简单好操作^-^,而且不会改变内容以便爬虫生效时间更长),爬取网站的quotes列表和author列表保存到一个mysql数据库对应的表中, QuotesSpider 和 AuthorSpider 两类分别爬取。
前提:
- 到 https://dev.mysql.com/downloads/mysql/ 下载安装MySQL Community Server和MySQL Workbench(用于查看数据库内容–也可以不需要这个),参考 https://www.jianshu.com/p/09ad017b1c35 安装(默认3306端口),在python3下使用
pip install PyMySQL安装库确保import pymysql可用即可(此处mysql都py2和py3库名字不一样使用方法页不一样–要注意)。 - 创建mysql数据表:
# /usr/local/mysql/support-files/mysql.server start
# /usr/local/mysql/support-files/mysql.server stop
mysql -u root -p # 首次密码要注意复制保存,以便初次进入可以修改密码
SET PASSWORD FOR 'root'@'localhost' = PASSWORD('xyz123'); # 这个测试密码就不打码了
create database scrapy DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
use scrapy;
# 创建数据表
CREATE TABLE quotes (
text VARCHAR(5000) NOT NULL,
author VARCHAR(100) NOT NULL,
tags VARCHAR(1000)
);
CREATE TABLE author (
name VARCHAR(100) NOT NULL,
birthdate VARCHAR(100),
bio VARCHAR(5000)
);
# 一些调试语句
# INSERT INTO quotes(text,author,tags) VALUES('aaa','aaa','aaa');
# SELECT * FROM quotes;
# DELETE FROM quotes;编码
基本的爬虫代码是参考 https://docs.scrapy.org/en/latest/intro/tutorial.html 实现的,主要就是按照说明依次执行和拷贝了(没错我就是这么懒)对应代码,参考如下:
1。 scrapy startproject tutorial 创建爬虫;
2。在./tutorial/tutorial/spiders 下依次创建两个文件 quotes_spider.py 和 author_spider.py ,分别编写如下类实现:
# author_spider.py
import scrapy
class AuthorSpider(scrapy.Spider):
name = 'author'
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
# follow links to author pages
for href in response.css('.author + a::attr(href)'):
yield response.follow(href, self.parse_author)
# follow pagination links
for href in response.css('li.next a::attr(href)'):
yield response.follow(href, self.parse)
def parse_author(self, response):
def extract_with_css(query):
return response.css(query).extract_first().strip()
yield {
'name': extract_with_css('h3.author-title::text'),
'birthdate': extract_with_css('.author-born-date::text'),
'bio': extract_with_css('.author-description::text'),
}# quotes_spider.py
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
# def start_requests(self):
# urls = [
# 'http://quotes.toscrape.com/page/1/',
# 'http://quotes.toscrape.com/page/2/',
# ]
# for url in urls:
# yield scrapy.Request(url=url, callback=self.parse)
start_urls = [
'http://quotes.toscrape.com/page/1/',
# 'http://quotes.toscrape.com/page/2/',
]
def parse(self, response):
# print(response.body)
# page = response.url.split("/")[-2]
# filename = 'quotes-%s.html' % page
# with open(filename, 'wb') as f:
# f.write(response.body)
# self.log('Saved file %s' % filename)
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').extract_first(),
'author': quote.css('small.author::text').extract_first(),
'tags': ''.join(quote.css('div.tags a.tag::text').extract()),
}
# next_page = response.css('li.next a::attr(href)').extract_first()
# if next_page is not None:
# next_page = response.urljoin(next_page)
# yield scrapy.Request(next_page, callback=self.parse)
for a in response.css('li.next a'):
yield response.follow(a, callback=self.parse)其中的注释代码是另一种写法实现,我只是参考官方demo一步一步尝试,毕竟初次使用scrapy有必要了解下…
3。编写最刺激的一部分,就是将爬到的item写入到mysql中,具体的原理还是在原说明中介绍了,主要是实现管道TutorialPipeline类(在其中对各个item进行任何自己想做的处理,原理参考官方说明)如下:
# pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
class TutorialPipeline(object):
quotes_name = 'quotes'
author_name = 'author'
quotesInsert = '''insert into quotes(text,author,tags)
values('{text}','{author}','{tags}')'''
authorInsert = '''insert into author(name,birthdate,bio)
values('{name}','{birthdate}','{bio}')'''
def __init__(self, settings):
self.settings = settings
def process_item(self, item, spider):
print(item)
if spider.name == "quotes":
sqltext = self.quotesInsert.format(
text=pymysql.escape_string(item['text']),
author=pymysql.escape_string(item['author']),
tags=pymysql.escape_string(item['tags']))
# spider.log(sqltext)
self.cursor.execute(sqltext)
elif spider.name == "author":
sqltext = self.authorInsert.format(
name=pymysql.escape_string(item['name']),
birthdate=pymysql.escape_string(item['birthdate']),
bio=pymysql.escape_string(item['bio']))
# spider.log(sqltext)
self.cursor.execute(sqltext)
else:
spider.log('Undefined name: %s' % spider.name)
return item
@classmethod
def from_crawler(cls, crawler):
return cls(crawler.settings)
def open_spider(self, spider):
# 连接数据库
self.connect = pymysql.connect(
host=self.settings.get('MYSQL_HOST'),
port=self.settings.get('MYSQL_PORT'),
db=self.settings.get('MYSQL_DBNAME'),
user=self.settings.get('MYSQL_USER'),
passwd=self.settings.get('MYSQL_PASSWD'),
charset='utf8',
use_unicode=True)
# 通过cursor执行增删查改
self.cursor = self.connect.cursor();
self.connect.autocommit(True)
def close_spider(self, spider):
self.cursor.close()
self.connect.close()#items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class TutorialItem(scrapy.Item):
# for quotes
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()
# for author table
name = scrapy.Field()
birthdate = scrapy.Field()
bio = scrapy.Field()settings.py最后添加如下mysql配置:
ITEM_PIPELINES = {
'tutorial.pipelines.TutorialPipeline': 300,
}
MYSQL_HOST = 'localhost'
MYSQL_DBNAME = 'scrapy'
MYSQL_USER = 'root'
MYSQL_PASSWD = 'xyz123'
MYSQL_PORT = 3306前面的爬虫框架(数据爬取
QuotesSpider和AuthorSpider类实现,以及TutorialItem定义)都没有什么值得注意的,关键在于以下几点:
+ 代码中的mysql参数定义在settings.py中,在TutorialPipeline类里面的获取方法。
+pymysql.escape_string方法在mysql中保证字符串的转义,避免爬取的字符串包含特殊字符导致sql语句出错!
+ TutorialItem 中的多个字段是分别针对QuotesSpider和AuthorSpider爬取的参数定义的,在TutorialPipeline中也是根据爬虫的类别决定读取项目的字段。
+ mysql的基本使用需要掌握。
4。 运行爬虫: scrapy crawl quotes 和 scrapy crawl author
之后就可以看到屏幕输出一大堆log(好恶心:谁知道怎么可以把log去掉?或者只输出想要的log?)–最后在MySQL Workbench中查看到数据表如下:
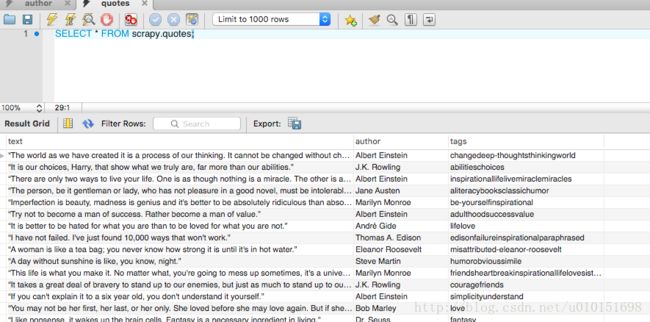
总结:
爬虫的使用流程:
1. 创建项目:scrapy startproject tutorial
2. 编写爬虫类:继承scrapy.Spider, 定义name和start_urls, 实现def parse(self, response) – 使用css或者xpath提取数据。
3. 在items.py中使用scrapy.Field()定义爬取字段,在pipelines.py的process_item中定义item处理规则,最后在settings.py中使用ITEM_PIPELINES激活管道。
4. 运行爬虫: scrapy crawl quotes -o quotes.j