Java-十种内部排序实现(选择,冒泡,插入,希尔,堆,归并,快速,基数,计数,桶)及代码下载
- 选择排序
- 冒泡排序
- 插入排序
- 希尔排序
- 堆排序
- 归并排序
- 快速排序
- 基数排序
- 计数排序
- 桶排序
1. 选择排序
这个排序方法最简单,废话不多说,直接上代码:
public class SelectSort {
/**
* 选择排序
* 思路:每次循环得到最小值的下标,然后交换数据。
* 如果交换的位置不等于原来的位置,则不交换。
*/
public static void main(String[] args) {
selectSort(Datas.data);
Datas.prints("选择排序");
}
public static void selectSort(int[] data){
int index=0;
for (int i = 0; i < data.length; i++) {
index = i;
for (int j = i; j < data.length; j++) {
if (data[index]>data[j]) {
index = j;
}
}
if (index != i) {
swap(data,index,i);
}
}
}
public static void swap(int[] data,int i,int j){
int temp = data[i];
data[i] = data[j];
data[j] = temp;
}
}
选择排序两层循环,第一个层循环遍历数组,第二层循环找到剩余元素中最小值的索引,内层循环结束,交换数据。内层循环每结束一次,排好一位数据。两层循环结束,数据排好有序。
2 冒泡排序
冒泡排序也简单,上代码先:
public class BubbleSort {
/**
* 冒泡排序
* 思路:内部循环每走一趟排好一位,依次向后排序
*/
public static void main(String[] args) {
bubbleSort(new int[]{9, 4, 2, 6, 8, 2, 0});
}
private static void bubbleSort(int[] data) {
int temp;
for (int i = 0; i < data.length; i++) {
for (int j = 0; j < data.length - i - 1; j++) {
if (data[j] > data[j+1]) {
temp =data[j];
data[j]=data[j+1];
data[j+1] = temp;
}
}
}
for (int i = 0; i < data.length; i++) {
System.out.print(data[i] + ", ");
}
}
}
冒泡排序和选择排序有点像,两层循环,内层循环每结束一次,排好一位数据。不同的是,数据像冒泡一样,不断的移动位置,内层循环结束,刚好移动到排序的位置。
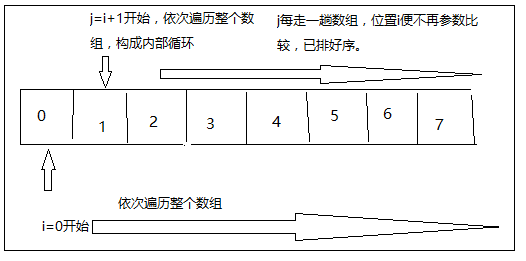
该图对应上面的代码进行的说明,没有用专门的画图工具,使用的是window的maspint,大家凑合着看哈_明白意思就成!
3 插入排序
插入排序也是简单的排序方法,代码量不多,先看代码:
public class InsertSort {
/**
* 插入排序
* 思路:将数据插入到已排序的数组中。
*/
public static void main(String[] args) {
int[] data = Datas.data;
int temp;
for (int i = 1; i < data.length; i++) {
temp = data[i];//保存待插入的数值
int j = i;
for (; j>0 && temp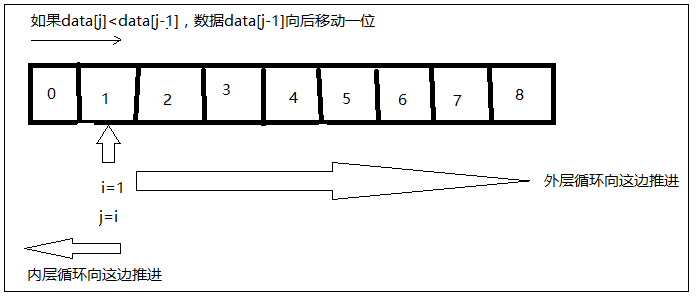
该图是上面插入排序的说明图,插入排序,其过程就是其名字说明的一样,将待排序的数据插入到已排序的数据当中。两层循环,内层循环结束一次,插入排序排好一位数据。
4 希尔排序
希尔排序,也叫缩减增量排序,其中增量的设置影响着程序的性能。最好的增量的设置为1,3,5,7,11,。。。这样一组素数,并且各个元素之间没有公因子。这样的一组增量 叫做Hibbard增量。使用这种增量的希尔排序的最坏清醒运行时间为θ(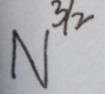 )
)
当不使用这种增量时,希尔排序的最坏情形运行时间为θ( )
)
这里电脑打印这些太麻烦,干脆手写拍照啦哈哈哈哈。。。。。
好了,废话不多说,上代码;
public class ShellSort {
/**
* 希尔排序(缩减增量排序)
* 想想也不难。
* 思路:三层循环
* 第一层循环:控制增量-增量随着程序的进行依次递减一半
* 第二层循环:遍历数组
* 第三层循环:比较元素,交换元素。
* 这里需要注意的是:比较的两个元素和交换的两个元素是不同的。
*/
public static void main(String[] args) {
int[] data = Datas.data;
int k;
for (int div = data.length/2; div>0; div/=2) {
for (int j = div; j < data.length; j++) {
int temp = data[j];
for (k=j; k>=div && temp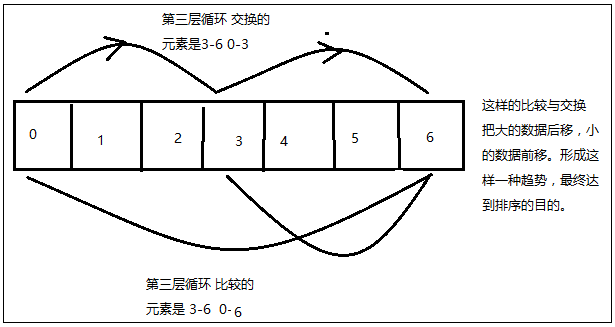
程序中,需要注意的是第三层循环,第三层循环的代码中,if语句的比较和内部的交换是分别不同的两个数据。原因是:把大的数据后移,小的数据前移,形成这样一种趋势,才能实现排序。
当然可以试试,if语句比较的两个数据和内部移动的数据一致的话,会出现什么问题?出现的问题就是移动的数据打破了之前形成的大的数据在后,小的数据在前的趋势。无法排序。
5 堆排序
堆排序,要知道什么是堆?说白了,堆就是完全二叉树,堆是优先队列。要求父元素比两个子元素要大。这就好办了。数组元素构建堆,根节点最大,删除根节点得到最大值,剩下的元素再次构建堆,接着再删除根节点,得到第二大元素,剩下的元素再次构建堆,依次类推,得到一组排好序的数据。为了更好地利用空间,我们把删除的元素不使用新的空间,而是使用堆的最后一位保存删除的数据。
代码上来:
public class HeapSort {
/**
* 堆排序(就是优先队列)
* 也就是完全二叉树
* 第一步:建堆.其实就是讲数组中的元素进行下虑操作,
* 使得数组中的元素满足堆的特性。
* 第二步:通过将最大的元素转移至堆的末尾,
* 然后将剩下的元素在构建堆。
* 完成排序。
* 最重要的过程就是构建堆的过程。
* 里面的比较思路和希尔排序中的比较思路一致。
* 将大的元素上浮,小的元素下浮。始终和temp比较。
* temp除了第一次比较可能改变外,其他次数的比较不改变该值。
* 这样的处理就是让较大的元素趋于上浮,较小的元素下浮。
*/
public static void main(String[] args) {
int[] data = Datas.data;
for (int i = data.length/2; i >=0; i--) {
buildHeap(data,i,data.length);
}
Datas.prints("堆排序-构建树");
System.out.println("============================");
for (int i = data.length-1; i>0; i--) {
swap(data, 0, i);
buildHeap(data, 0, i);
}
Datas.prints("堆排序-排序后");
}
static void swap(int[] data,int i,int j){
int temp = data[i];
data[i] = data[j];
data[j] = temp;
}
static void buildHeap(int[] data,int i,int len){
int leftChild = leftChild(i);
int temp = data[i];
for (; leftChild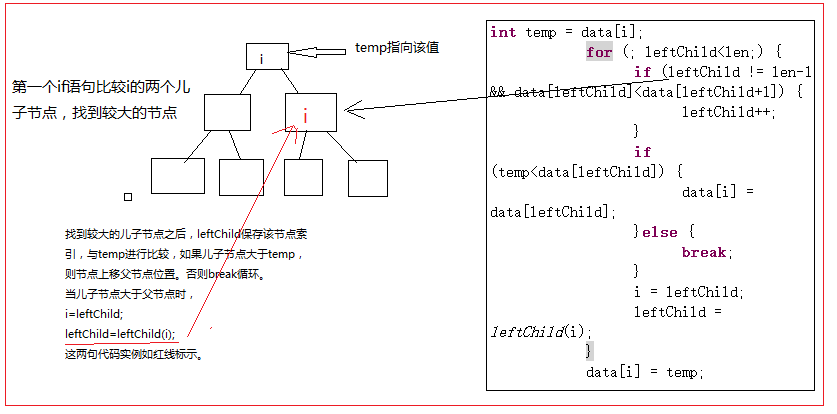
堆排序,最重要的就是构建堆,构建堆是核心!我们代码中使用的是数组形式的二叉树,也就是优先队列。要真正看懂这部分的代码,需要知道优先队列部分的知识,不难,看看就懂啦。说白了就是二叉树。
6 归并排序
归并排序思路就是将两个已经排好序的数组插入到第三个数组当中。核心就是将原有数组分割两部分,排好序,插入到第三个与原有数组大小一致的数组中。代码上来:
public class MergeSort {
/**
* 归并排序
* 思路:如果是两个已排序的数组,进行合并非常简单。
* 所以就对原有数组进行分割,分割成各个排序的数组,
* 然后递归合并。
*/
public static void main(String[] args) {
int[] data = Datas.data;
merge(data);
Datas.prints("归并排序");
}
public static void merge(int[] data){
int[] temp = new int[data.length];
merge0(data, temp, 0, data.length-1);
}
public static void merge0(int[] data,int[] temp,int left,int rigth){
if (left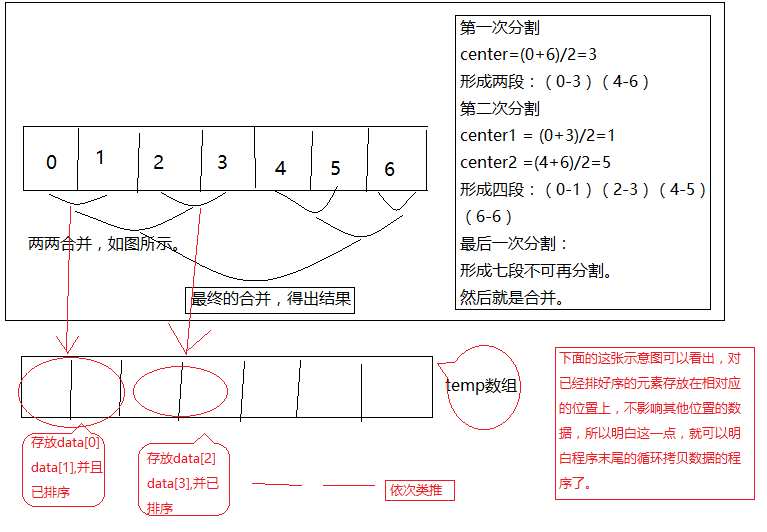
说明图中已经说明了关于数组分割,排序、归并的步骤。归并排序其实就是分割,排序,归并,最后得到排序的结果。
排序要等到分割完成之后进行,归并要等盗排序之后进行。
分割通过递归调用进行,排序通过程序中的三个while循环进行,即完成了归并。最后将数据拷贝要原来的数组中去。
7 快速排序
快速排序有点类似于归并排序,其实也是分割,不同的是,快速排序的分割是按照中值进行分割的,所以中值的好坏影响着程序的性能。最常见的情形是三数中值分割法!!
该方法的思路是选取左,右、中三个数进行交换,把三个数中最小值放在左边,中间值放在中间,最大值放在右边,这样以中值为界形成了两部分,要注意这时候还没有排序,只是进行了枢纽元的选取。中间值就是枢纽元!
然后以枢纽元为中心,分别交换左右两侧的数据,把大的数据放在枢纽元的右侧,把小的数据放在枢纽元的左侧,最终形成大致排序的两组数据,枢纽元排好序,然后递归调用快速排序。
同时,为了移动数据方便,我们把枢纽元的位置放在right-1的位置。
大家可能要问了:为什么把枢纽元放在right-1的位置呢?
原因是:right的位置放置的是比枢纽元大的数,在选取枢纽元的时候,我们把大的数放在right的位置,最小的数放在left的位置,把枢纽元放在right-1的位置,这样当完成数据交换之后枢纽元只需一次交换。如果把枢纽元放在中间的位置,要知道的是,中间位置并不一定就是枢纽元要排序的位置。这个地方要搞清楚,还得看代码:
public class QuickSort {
/**
* 快速排序
* 首先找到三数中值,然后分别移动左右两边的数据,
* 以中值数分割成两组,一组比中值数大,一组比中值数小。
* 然后递归快排两组数组。
* 当待排序的数组小于CUTOFF时,使用插入排序。
*/
private static int[] datas = {4, 9, 0, 1, 4, 5, -14, -15, 90, 7, 99};
public static void main(String[] args) {
quickSort(datas, 0, datas.length-1);
for (int i = 0; i < datas.length; i++) {
System.out.print(datas[i] + ", ");
}
}
public static void quickSort(int[] data,int left,int right) {
int CUTOFF = 1;
if (left+CUTOFFmedia);
if (i>j) {
break;
}
swap(data, i, j);
}
//将中值数移动到i处。中值数即排在i处。
swap(data, i, right-1);
return i;
}
//找到中值数
public static int media3(int[] data,int left,int right){
int center = (left+right)/2;
/**
* 前两个if语句的比较,
* 使得最小值放在最左边。
*/
if (data[center] 0; j--) {
if (datas[j] < datas[j-1]) {
swap(datas, j, j-1);
}
}
}
}
}
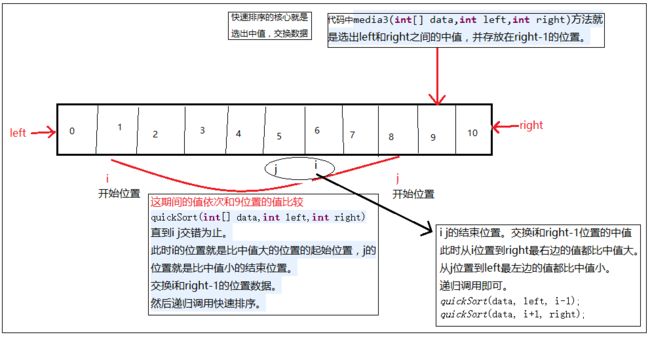
快速排序说明图,示意了i、j游标的移动位置。结合程序应该能看懂。
不过值得大家注意的是,程序中不仅仅使用快速排序的思路,而在最后,当left与right的差值在CUTOFF的时候,直接使用直接插入排序,不再使用快速排序。原因我在注释中已经给出。
如果不使用CUTOFF时候的插入排序,最终的结果并不是我们想要的。如果仅仅使用快速排序得到最终结果,则代码是不正确的。
上面的代码必须在最后使用一次插入排序才能得到最终的结果。
8 基数排序
桶排序之前不了解,我看的《数据结构与算法分析》一书中并没有给出大量的讲解,反而代码是通过例题的形式给出的。桶排序其实就是形成大的容器,通过比较数据各个位上的数进行排序。
别的不多说了,直接上代码:
public class RadixSort {
/**
* 基数排序
* 二维数组构成桶
* 一维数组记录每个位存放的个数。
* 每次构建桶完成,拷贝数据到原来的数组中去。
* 继续下一轮桶的构建。
* 分别个位,十位,百位。。。
* 程序必须知道最大值的位数。
*/
public static void main(String[] args) {
radixSort(Datas.data,3);
Datas.prints("基数排序");
}
public static void radixSort(int[] data,int maxLen){
//maxLen表示最大值的长度
//LSD最低位优先排序 MSD最高位优先排序 l从0开始 循环三次
int k = 0;
int n = 1;
int[][] bucket = new int[10][data.length];//桶
/**
* 表示桶的每一行也就是每一位存放的个数
*/
int[] orders = new int[10];
int temp = 0;
for (int l = 0; l < maxLen; l++) {
for (int i = 0; i < data.length; i++) {
temp = (data[i]/n)%10;
bucket[temp][orders[temp]] = data[i];
orders[temp]++;
}
//将桶中的数值保存会原来的数组中
for (int i = 0; i < 10; i++) {
for (int j = 0; j < orders[i]; j++) {
if (orders[i]>0) {
data[k]=bucket[i][j];
k++;
}
}
//拷贝完成清除记录的个数,设为0
orders[i]=0;
}
//n乘以10 取十位 百位的数值
n*=10;
k=0;
//k值记录拷贝数据到原有数组中的位置,拷贝完成恢复0
}
}
}

这个是实例,程序打印结果的话,不好看,只好手写大家看效果。
bucket二维数组存放原始数据。orders数组存放每一位数存放的原始数据的个数。外层循环每执行一次,就把数据拷贝给原来的数组。然后进行下一轮循环。分别进行个位、十位、百位、、、、的循环。这是从最低位开始排序。也有最高位开始进行的排序。
9 计数排序
这个直接上代码:
public class CuntingSort {
/**
* 计数排序
* 思路:构建一个与待排序中最大值相同大小的数组,
* 该数组存放待排序数组中每个数字出现的个数。
*/
public static void main(String[] args) {
cunting(Datas.data, 333);
Datas.prints("计数排序");
}
public static void cunting(int[] data,int max){
int[] temp = new int[max+1];
int[] result = new int[data.length];
/**
* 该循环设置初始值为0
*/
for (int i = 0; i < temp.length; i++) {
temp[i]=0;
}
/**
* 该for语句循环遍历原数组,将数组中元素出现的个数存放在
* temp数组中相对应的位置上。
* temp数组长度与最大值的长度一致。保证每个元素都有一个对应的位置。
*/
for (int i = 0; i < data.length; i++) {
temp[data[i]]+=1;
}
/**
* 累计每个元素出现的个数。
* 通过该循环,temp中存放原数组中数据小于等于它的个数。
* 也就是说此时temp中存放的就是对应的元素排序后,在数组中存放的位置+1。
*/
for (int i = 1; i < temp.length; i++) {
temp[i]=temp[i]+temp[i-1];
}
/**
* 这里从小到大遍历也可以输出正确的结果,但是不是稳定的。
* 只有从大到小输出,结果才是稳定的。
* result中存放排序会的结果。
*/
for (int i = data.length-1; i>=0; i--) {
int index = temp[data[i]];
result[index-1]= data[i];
temp[data[i]]--;
}
Datas.data = result;
}
}
这个排序还真没法画图,其实这个排序相当容易理解。找出待排序数组中最大的元素,构建一个与最大元素数+1长度的数组temp,这样保证待排序数组中的每一个元素都能在temp数组中找到自己的位置,但是temp不是用来存放元素的,而是存放每个元素在待排序数组中出现的个数。这一步通过第二个for循环得到。
接着第三个for循环,循环遍历temp,目的就是得到每个元素排序后存放在原有数组中的位置。大家想一想,每个位置存放自己出现的个数,那么小于自己的元素出现的个数加到一起,即可得到自己排序后数组中的存放位置。是不是真的很巧妙!!!!!
到此,基本就是该排序算法的核心啦!!!
10 桶排序
桶排序是另外一种以O(n)或者接近O(n)的复杂度排序的算法. 它假设输入的待排序元素是等可能的落在等间隔的值区间内.一个长度为N的数组使用桶排序, 需要长度为N的辅助数组. 等间隔的区间称为桶, 每个桶内落在该区间的元素. 桶排序是基数排序的一种归纳结果。
算法的主要思想: 待排序数组A[1…n]内的元素是随机分布在[0,1)区间内的的浮点数.辅助排序数组B[0…n-1]的每一个元素都连接一个链表. 将A内每个元素乘以N(数组规模)取底,并以此为索引插入(插入排序)数组B的对应位置的连表中. 最后将所有的链表依次连接起来就是排序结果.
这个过程可以简单的分步如下:
1、设置一个定量的数组当作空桶子。
2、寻访序列,并且把项目一个一个放到对应的桶子去。
3、对每个不是空的桶子进行排序。
4、从不是空的桶子里把项目再放回原来的序列中。
例如要对大小为[1…1000]范围内的n个整数A[1…n]排序,可以把桶设为大小为10的范围,具体而言,设集合B[1]存储[1…10]的整数,集合B[2]存储(10…20]的整数,……集合B[i]存储((i-1)10, i10]的整数,i = 1,2,…100。总共有100个桶。然后对A[1…n]从头到尾扫描一遍,把每个A[i]放入对应的桶B[j]中。 然后再对这100个桶中每个桶里的数字排序,这时可用冒泡,选择,乃至快排,一般来说任何排序法都可以。最后依次输出每个桶里面的数字,且每个桶中的数字从小到大输出,这样就得到所有数字排好序的一个序列了。
/**
* 桶排序算法,对arr进行桶排序,排序结果仍放在arr中
* @param arr
*/
public static void main(String[] args){
bucketSort(Datas.datad);
for (int i = 0; i < Datas.datad.length; i++) {
System.out.println(Datas.datad[i]+",");
}
}
public static void bucketSort(double arr[]){
int n = arr.length;
ArrayList arrList[] = new ArrayList[n];
//把arr中的数均匀的的分布到[0,1)上,每个桶是一个list,存放落在此桶上的元素
for(int i =0;i();
arrList[temp].add(arr[i]);
}
//对每个桶中的数进行插入排序
for(int i = 0;i iter = arrList[i].iterator();
while(iter.hasNext()){
Double d = (Double)iter.next();
arr[count] = d;
count++;
}
}
}
}
/**
* 用插入排序对每个桶进行排序
* @param list
*/
public static void insert(ArrayList list){
if(list.size()>1){
for(int i =1;i=0&&((Double)list.get(j)>(Double)list.get(j+1));j--)
list.set(j+1, list.get(j));
list.set(j+1, temp);
}
}
}
}
}
原文地址:http://www.tuicool.com/articles/3emMVz
这个是我看到的关于桶排序说的最好的一篇文章。
举例说明:
假如待排序列K= { 49、 38 、 35、 97 、 76、 73 、 27、 49 }。这些数据全部在1—100之间。因此我们定制10个桶,然后确定映射函数f(k)=k/10。则第一个关键字49将定位到第4个桶中(49/10=4)。依次将所有关键字全部堆入桶中,并在每个非空的桶中进行快速排序后得到如下图所示:
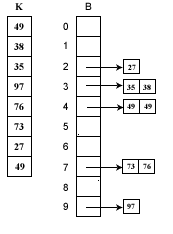
对上图只要顺序输出每个B[i]中的数据就可以得到有序序列了。
这个例子有点类似于基数排序。因此,可以说,桶排序是基数排序的一种。
网上很多讲述基数排序,计数排序,桶排序的文章,但是很多都搞混了。如果大家希望看到最权威的讲述就看《算法导论》这本书。这本书专门一章讲述基数排序,计数排序和桶排序。不过,算法导论有点难呦~~
本文中全部代码下载,[请猛戳这里!!]