深度学习最基础理论知识总结 (CS231课程总结,持续更新)
因为有在看CS231学习深度学习的简单知识,所以打算整理成blog,持续更新中。。。
一、损失函数loss function
1、SVM:最简单的loss function
![]()
其中![]() 为真实label对应的分数,
为真实label对应的分数,![]() 为label j对应的分数,Li为每个样本的分类损失,目的是最大化真实label对应分数。
为label j对应的分数,Li为每个样本的分类损失,目的是最大化真实label对应分数。
在初始化时,Li的初始值接近于C-1,其中C为分类的个数,因为所有的分数都接近于0,对应为(C-1)个1相加。
所有样本的loss表示为:
![]()
2、softmax
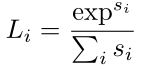
二、模型正则项
通常为了防止模型过拟合,使得模型在效果和复杂度之间达到平衡,常常引入正则项。不同的正则项都是为了模型简单化,但是对简单的定义各异。
1) L1范式:鼓励稀疏,也就是鼓励权重向量中0的个数,从而使得模型简单化
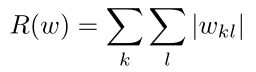
2) L2范式:鲁棒性更好,控制向量中的整体分布,各个位置的数值均影响模型更好,即各个位置的数值较为平均。
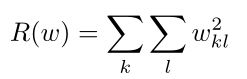
3) dropout:随机将每一层上的一些神经元设为0,常在全连接层使用。训练时间加长,但训练后鲁棒性增强。
4) bach normalization:见下
5) dropconnect:和3不同,不是丢弃神经元,而是丢弃一些权重矩阵
6) stochastic depth:随机丢弃一些层。
三、Bach Normalization
深度学习中,通常为了能让激活函数更好地激活,防止梯度消失或者梯度爆炸 (后面会有解释),需要对特征进行归一化,将特征向量变成均值为0,方差为1的向量
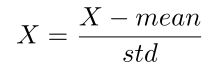
通常在全连接层和卷积层之后使用,每一层保证高斯分布,对向量的每个维度进行归一化。
四、正向传播与反向传播
神经网络中最主要的操作就是正向传播与反向传播。
正向传播:值,从输入层开始计算各个层的值,依次向后传播直至输出层;
反向传播:从输出层将损失进行反向传播,传播的是梯度,基于链式法则。
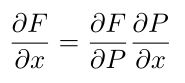
五、卷积神经网络 convolutional neural network (CNN)
全连接层:整图input x,经过权重矩阵W,进行矩阵相乘Wx得到输出
卷积层:对于一个矩阵x(N*N*depth),使用一个卷积核 (filter) w (F*F*depth),在x上按行向下滚动点乘 (将对应位置上的元素相乘),通常会有滚动的间隔stride,以下图为例,对应卷积操作为:
1) 从第一行开始,在对应位置使用卷积核点乘;
2) 将卷积核向右移动一个stride,得到第二幅图,进行点乘;
3) 一直向右以stride为间隔移动,直至到达最右端。然后从第二行开始继续执行1、2步。
所以在经过一次卷及操作后,输出的尺寸大小为s= (N-F)/stride+1,其中F为卷积核的尺寸,N为原始尺寸,输出的大小为s*s*1。通常每一个卷积层会有k个不同的卷积核,所以得到的输出层尺寸为s*s*k。
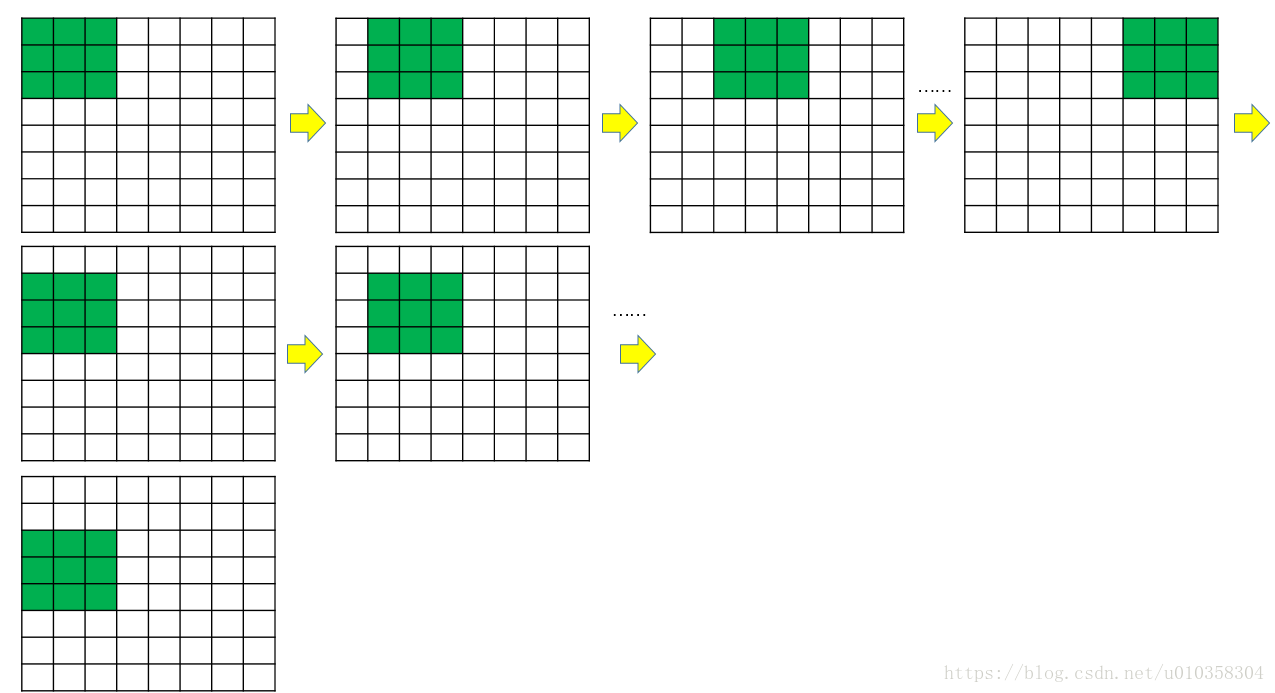
处理边角位置:使用zero pad在外围一层填空,或是复制边缘值。 目的:在stride=1时保证输出和原始尺寸相同,减少信息损失 (图片尺寸快速减小),减小边角信息损失。
常用的卷积核大小:3*3,5*5,7*7。使用不同的卷积核,为了使输出尺寸保持不变,zero pad的宽度会随之变化。
对于n个m*m的卷积核,对应的参数个数为(m*m*3+1)*n,其中3为depth的值,通常为RGB三通道;1为偏差项;n通常设置为2的次方(32,64,……)。
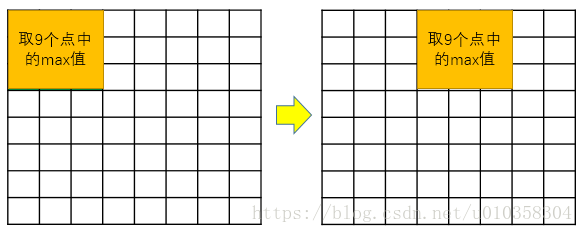
池化层 pooling layer:不改变深度,只改变尺寸。
max pooling: 使用m*m的filter,stride=m (没有重叠区域,降采样),每一个小块取其中的最大值。
采用max而不是mean的原因:为了表示对应区域的受激程度。
通常的深度网络结构:((CONV-RELU)*N-POOL)*M-(FC-RELU)*K,SOFTMAX
其中RELU为激活函数,下面会讲到。通常![]() 。
。
六、激活函数activation function
1、sigmoid
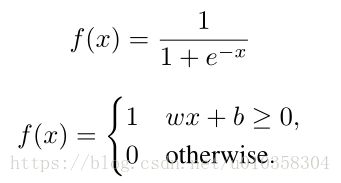
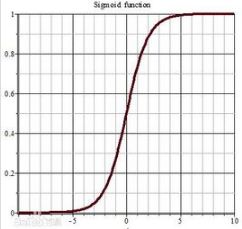
其中第二个分段函数是感知机。
存在的问题:
- 饱和神经元使梯度消失:x很大/很小时,梯度变为0,传递到下游节点,梯度消失;
- 非零中心函数:当输入wx+b,x均为正值时,梯度均为正或者均为负,在参数更新时只朝一个方向移动,无法得到理想参数,更新效率低;
- exp(-x)的计算代价较高。
2、Relu
![]()

优点:
- 不会饱和,避免梯度消失;
- 计算成本小;
- 收敛速度快;
- 更具有生物合理性。
缺点:
- 非零中心函数;
- x<0时会出现梯度消失的问题,dead relu
- 不适用较大梯度,参数更新后不再激活,梯度为0。
3、Leaky-Relu
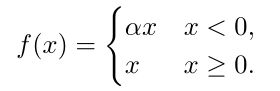
4、PRelu
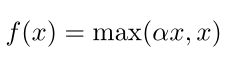
5、tanh
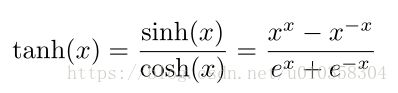
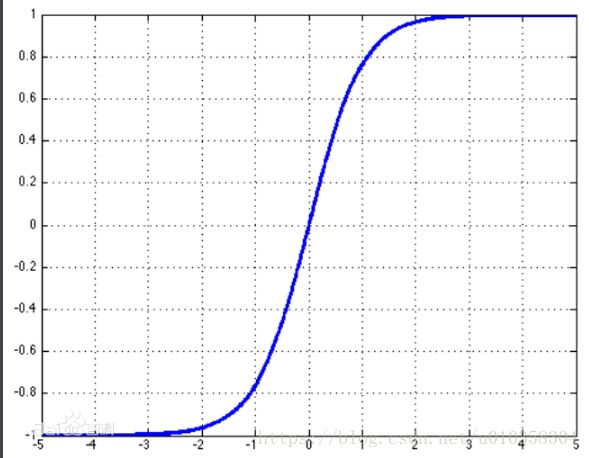
优点:零中心
缺点:仍有梯度消失问题
6、Maxout
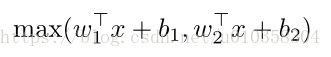
优点:不饱和,no die
缺点:参数数量翻倍
7、ELU

七、数据预处理 data preprocessing
1、zero-centered: x-=np.mean
1) 对所有通道取均值 AlexNet
2) 对每个channel取均值 VGGNet
2、normalized data: x/=np.std(X,axis=0)
八、权重初始化 weight initialization
初始化时可能面临的问题:
- 如果将w均初始化为0,则所有神经元都在做相同的事情。
- 权值设置过小 (0.01),不断传播后数值变得过小
- 权值设置过大,饱和,梯度变为0
所以常使用Xavier initialization:
np.random.randn(in,out)/np.sqrt(in)或者
np.random.randn(in,out)/np.sqrt(in/2) 解决Relu每次有一般不会被激活的问题 (x<0)。
九、babysitting参数监控
- 如果loss为NaN,说明学习速率设置过大
- 如果loss值下降很缓慢,说明学习速率过小
- 交叉验证,如果训练集的accuracy不断增加,而测试集不变,说明可能过拟合,需要调整正则化项
十、随机梯度下降 stochasitc gradient decent (SGD)
梯度:沿着梯度方向函数值上升最快
梯度更新:计算好当前状态下损失函数在每个参数下的梯度后,再更新每个参数;而不是计算一个参数就更新一个参数,然后再计算一个参数,因为这时第一个参数已经改变。 这里提到的是同步更新的概念。
缺点:
- 在某个方向loss下降很快,某个方向loss下降很慢
- 局部最小点:如下所示红点位置
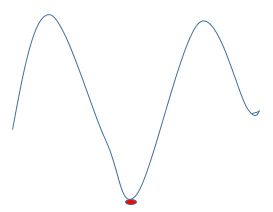
- 鞍点:saddle point,一个方向上梯度大于0,一个方向上梯度小于0。在高维数据上容易发生
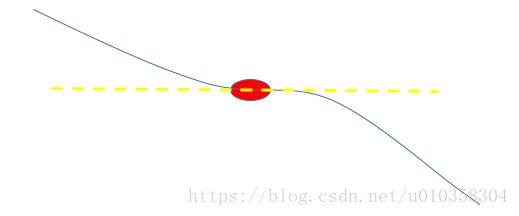
- stochastic:曲折着走向optimal,耗时。
十一、学习率learning rate decay method
1、exponential decay

2、 1/t decay
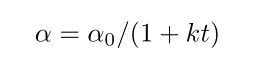
十二、VGG Net
1) smaller filter:3*3卷积核
参数量较小,可以使用更多的filters来增加深度
2) same effective field
使用3层,3*3 C个filters,对应的视野域和7*7的相同,但是参数远远小,3*(3*3*C*C)<(7*7*C*C)。
effective field:第一层3*3;第二层也是3*3,但其中每个点都对应第一层中的一个3*3区域,按照stride=1滚动,所以第二层中的3*3实际对应了原始中5*5的区域;同理,第三层对应到的实际是7*7的区域。
所以视野域和直接使用7*7的卷积核是一样的,但是参数变少了,减少了计算负担。
十三、GoogleNet
无全连接层,含有一个inception layer, 包含了3个conv层和1个pooling层,最终结果将4个输出串联为最终输出,每个conv层,pooling层尺寸相同,深度 (通道数)不同。
但是这种方法,计算量大。解决方案:加入bottleneck层,使用1*1 conv先降低输入深度。
例如,m*m*256经过1*1 filter后,变成m*m*32,这样再传入conv层能够减少运算。
十四、ResNet
Hypothsis: the problem is an optimization problem, deeper models are harder t optimize. 所以并不是越深的网络就一定越好。