opencv 学习之 车牌识别
去年三月写过一篇文章,就是这货:
http://blog.csdn.net/u010477528/article/details/44095699
车牌提取,基于OpenCV,当时仅做到车牌提取,后来懒惰吧,一拖再拖,拖到现在。
接下来做一下字符分割和识别。恩,先上一张车牌吧。

1、字符分割
分割的话简单,方法也比较多。看网上有人通过不断切割的方式,直到出现理想轮廓,没试过,不知道效果。
直接把车牌设置成ROI区域,拷贝成图片,在新的图片中提取轮廓。此处图像预处理与原来不同。
除了汉字,字母和数字基本都是一个轮廓,所以对于车牌,形态学处理稍微膨胀下就好了。
//ROI设置
cvSetImageROI(src_img, rect);
cvCopyImage(src_img,plate_img);
cvResetImageROI(src_img);
效果像下面这样。
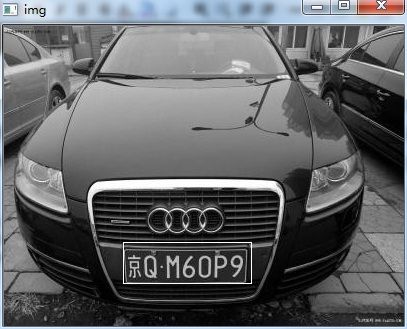
图:原图中定位车牌

图:车牌提取出来
下来就轮廓提取,不要的轮廓删掉,提出7个轮廓来。
cvFindContours(plate_img,storage, &contour, sizeof(CvContour), CV_RETR_CCOMP, CV_CHAIN_APPROX_SIMPLE);
找到轮廓并设置筛选条件,plate_img 就是刚才提出来的车牌,上面那个图。
之后呢,如法炮制,将各字符设置ROI并提取。此步骤是在轮廓检测阶段,若当前轮廓符合条件,则设置ROI。
cvSetImageROI(plate_img, rect);
cvCopyImage(plate_img,plate_number);
cvResetImageROI(plate_img);
plate_number就是提取出来的一个个的小字符,效果如下

不知道轮廓提取的顺序基于什么原理,反正最后依照轮廓 x 坐标重新排列一下就好。
提出7个轮廓来,每提出一个,识别一次。
2、字符识别
先在网上下载一个字符库,不用太专业。下面这个就行。
http://download.csdn.net/detail/bailichun19901111/8306831
下来就是字符和模板的匹配了。
_finddata_t FileInfo;
string FilePathStr;
char * FilePath = "..\\templet\\";
long Handle =_findfirst(FilePathStr.assign(FilePath).append("*.bmp").c_str(),&FileInfo);
templet文件夹存放模板,放在工程目录下就行。
_findfirst() 这个函数是读取文件夹下文件信息,第一个参数是目录,信息存第二个参数里面。
然后_findnext( Handle, &FileInfo)读下一个模板。
对每个模板的相似度进行统计,当然也有其他方法,此处用MSE。
for(int i=0; i
{
for(int j=0; j
{
calar_normal =cvGet2D(normal_plate_number, i, j).val[0];
calar_template =cvGet2D(templet_img, i, j).val[0];
mse += abs(calar_normal -calar_template);
}
}
mse_list[templet_number]= mse;
templet_number是模板数量,mse_list[]是mse列表
int pos =Find_min_pos(mse_list, templet_number);
point_x_list[contour_number_availd][0]= rect.x; //存储轮廓的X坐标
point_x_list[contour_number_availd][1]= pos; //存储模板编码,即图像对应第几个模板
Find_min_pos()找到最小值,表示匹配度最高。
point_x_list记录字符位置x坐标及与字符匹配的模板编码。编码如0对应0,11对应A。
下来按照x坐标的大小排序,编码随之变动。
//坐标排序
int temp =point_x_list[j][0];
point_x_list[j][0] =point_x_list[j + 1][0];
point_x_list[j +1][0] = temp;
//数值随之变化
temp =point_x_list[j][1];
point_x_list[j][1] =point_x_list[j+1][1];
point_x_list[j+1][1]= temp;
然后输出对应x左边的模板编码即可。
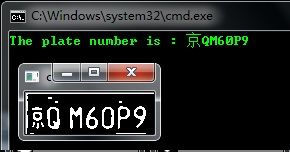
最基本的算法,未考虑倾斜、模糊等现象。