[2019][cvpr]Edge-Labeling Graph Neural Network for Few-shot Learning 笔记
paper:EGNN paper
code:code and models are available on github
其他人的总结
主要思想就是通过图网络进行信息传播,学出边的信息,也就是节点间相似性和相异性
这篇论文方法不复杂,实现也不难,很有效,值得学习。作者使用了4个NVIDIA Tesla P40 GPUs。我试了一下,由于imagenet图片不大,embedding_size也不大,单个gpu也能跑。
few shot learning
少样本任务setting是这样的:采用episodic过程进行学习和测试。也就是对于一个N-way, K-shot的任务,一个episode包含了support set 和 query set。
从全体类别中采样出的N个类别,每个类别包含了K个样本,这NK个样本称为支撑集,记为 S = { ( x i , y i ) } i = 1 N K \mathcal{S} = \{(x_i,y_i)\}_{i = 1}^{NK} S={(xi,yi)}i=1NK。另外还有 T T T个样本的查询集 Q \mathcal{Q} Q,在训练阶段查询集的label用于计算loss和学习,测试阶段查询集的label是我们要进行预测的。
训练阶段和测试阶段的类别是不相交的,也就是 C t r a i n ∩ C t e s t = ∅ \mathcal{C}_{train} \cap \mathcal{C}_{test} = \varnothing Ctrain∩Ctest=∅。
当部分support set 不提供label时,称为semi supervised few shot learning.
论文模型
符号定义和特征
令 G = ( V , E ; T ) \mathcal{G} = (\mathcal{V},\mathcal{E};\mathcal{T}) G=(V,E;T)为一个episode样本 T \mathcal{T} T构建的图, ∣ T ∣ = N K + T |\mathcal{T}| = NK+T ∣T∣=NK+T, V = { V i } i = 1 , . . . , ∣ T ∣ \mathcal{V}=\{V_i\}_{i = 1,...,|\mathcal{T}|} V={Vi}i=1,...,∣T∣为顶点集, E = { E i } i = 1 , . . . , ∣ T ∣ \mathcal{E}=\{E_i\}_{i = 1,...,|\mathcal{T}|} E={Ei}i=1,...,∣T∣为边集
定义,边的ground true edge label
y i j = { 1 , i f y i = y j , 0 , o t h e r w i s e y_{ij} = \begin{cases} 1,\,if\,y_i = y_j, \\ 0,\, other wise \end{cases} yij={1,ifyi=yj,0,otherwise
然后定义每条边为一为一个二维向量 e i j = { e i j d } d = 1 2 ∈ [ 0 , 1 ] 2 e_{ij} = \{e_{ijd}\}_{d=1}^2 \in [0,1]^2 eij={eijd}d=12∈[0,1]2,每一维度是一个0到1的数,和为1,表示的是类内关系和类间关系(也就是两样本类别相似性和相异性)。在这文章里,应该是不对称的,也就是 e i j e_{ij} eij和 e j i e_{ji} eji是不同的,也就是有向边
初始点特征是由一个convolution embedding 网络提取的, v i 0 = f e m b ( x i ; θ e m b ) v_i^0 =f_{emb}(x_i;\theta_{emb}) vi0=femb(xi;θemb)
边的初始化( ∣ ∣ || ∣∣表示concatenation)
![[2019][cvpr]Edge-Labeling Graph Neural Network for Few-shot Learning 笔记_第1张图片](http://img.e-com-net.com/image/info8/9be780ea78344241b13201754271ceaf.jpg)
图的更新
图网络包含 L L L层,更新法则如下
node向量的更新
和attention机制类似,用邻接节点的node信息更新当前节点。分为两部分,一部分是根据相似性提取的信息,一部分是根据相异性提取的信息,concatenate 起来
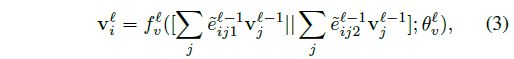
其中 e ~ i j d = e i j d ∑ k e i k d \tilde{e}_{ijd} = \dfrac{e_{ijd}} {\sum_k e_{ikd}} e~ijd=∑keikdeijd 表示每个邻接节点的权重归一化
f v l f_v^l fvl是第 l l l层节点transform网络。在代码中的实现是将原来的feature拼接上去,不仅仅是上面两部分。代码中的conv2d可以改成conv1d。实际上那个卷积就是一个线性层,只不过这样处理更加方便。便于后面batchnorm和dropout对特征的每个维度做处理
edge更新
![[2019][cvpr]Edge-Labeling Graph Neural Network for Few-shot Learning 笔记_第2张图片](http://img.e-com-net.com/image/info8/db13d866688a4ed6bd306bee928efeef.jpg)
这部分理解起来也很容易,就是边信息的传播,根据两个节点信息以及上一层的边信息以及和当前节点连接的其他边信息决定。 f e l f_e^l fel是一个相似性计算网络,(5)计算不相似性用了 1 − f e l 1 - f_e^l 1−fel,也可以用另一个网络计算代替。最后就是归一化。
也就是说,对节点 i i i的所有边进行重新调整,调整方法是根据节点计算出的相似性和原来相似性乘积作为权重、调整后总和不变。这是我的理解,上面的(4)式子可以看成(省略上标 l l l和参数)
( ∑ k e i k 1 ) f e ( v i , v j ) e i j 1 ∑ k f e ( v i , v k ) e i k 1 \left(\sum_k e_{ik1} \right)\frac{f_e(v_i,v_j) e_{ij1}}{ \sum_k f_e(v_i,v_k) e_{ik1}} (k∑eik1)∑kfe(vi,vk)eik1fe(vi,vj)eij1
∑ k e i k 1 = ∑ k e ˉ i k 1 \sum_k e_{ik1} = \sum_k \bar{e}_{ik1} k∑eik1=k∑eˉik1
算法
最后用有label的,去预测没有label的,方法就是利用最后输出边的相似性权重计算分类概率,也就是令 y ^ i j = e i j 1 L \hat{y}_{ij} =e_{ij1}^L y^ij=eij1L
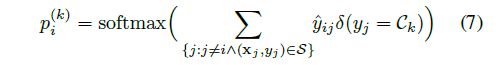
整合到一起就得到算法,图模型预测的算法
![[2019][cvpr]Edge-Labeling Graph Neural Network for Few-shot Learning 笔记_第3张图片](http://img.e-com-net.com/image/info8/d73e4aefe3fb4a12a7e2769b2a08ecaf.jpg)
网络架构![[2019][cvpr]Edge-Labeling Graph Neural Network for Few-shot Learning 笔记_第4张图片](http://img.e-com-net.com/image/info8/d2d0b2b0a9364ff8b7c0b38f1d5491ae.jpg)
Loss
在训练阶段,不是拿query set的样本,按照上面的预测概率进行损失的计算。而是利用边权指导每一层的训练。对每一次迭代的episode 的M个样本,loss为
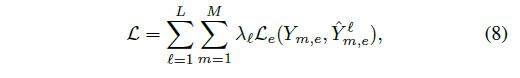
其中 Y m , e Y_{m,e} Ym,e是样本m和query set连接的边集, Y ^ m , e l \hat{Y}_{m,e}^l Y^m,el是第 l l l层预测的这些边的权。 L e \mathcal{L}_e Le是binary cross entropy loss
实验
数据集:miniImageNet and tieredImageNet (都是ILSVRC-12的一个子集,类别数不一样,后一个比前一个多得多)
实验设置
特征提取网络使用4个blocks的网络
测试阶段:5-way, 5-shot 每个episode 中每个类的query样本包含15个
训练阶段:Adam 优化器,初始学习率5e-4,weight decay 1e-6。mini-batch size, 5-way时40,10-way时20(应该是指episode数量)。
miniImageNet每 15 , 000 15,000 15,000个episode,学习率减半,tieredImageNet 则是 30 , 000 30,000 30,000个 episode。使用NVIDIA Tesla P40 GPUs
文章没有说训练时query set的大小,不过代码中貌似是每个类别一个,共N个
实验结果
![[2019][cvpr]Edge-Labeling Graph Neural Network for Few-shot Learning 笔记_第5张图片](http://img.e-com-net.com/image/info8/26bfe6f33e6e44328d3ea717d424d61c.jpg)
few-shot分类比较,三个部分No,Yes,BN,分别表示的是。No表示非转导(transductive)方法,Yes指的是转导方法,也就是所有query一起处理,而不是一个个来。 BN 值得是利用query的batch统计量,而不是用batch normalization parameters(可以看做是一种 test-time的transductive inference)
![[2019][cvpr]Edge-Labeling Graph Neural Network for Few-shot Learning 笔记_第6张图片](http://img.e-com-net.com/image/info8/4555efa4b1224c8cbed6d22e5294e43e.jpg)
半监督设置,也就是部分label没有给
![[2019][cvpr]Edge-Labeling Graph Neural Network for Few-shot Learning 笔记_第7张图片](http://img.e-com-net.com/image/info8/da86b6779b9a49dab2b832dd0d1bc07e.jpg)
简化有效性测试,随着网络层数从1增加到3,网络在miniImagenet表现越来越好,intra&inter的边类型比单独只有Intra类型的要好
![[2019][cvpr]Edge-Labeling Graph Neural Network for Few-shot Learning 笔记_第8张图片](http://img.e-com-net.com/image/info8/046dcdd1443f48cba621bd4be6941c6b.jpg)
5 way学习的网络,也能用于10 way的预测反过来也一样,上面表格显示,即使是cross-way,网络表现依然很好,不用重新训练
![[2019][cvpr]Edge-Labeling Graph Neural Network for Few-shot Learning 笔记_第9张图片](http://img.e-com-net.com/image/info8/feb1dbf1ef6f41c0a52f92370cdbcc52.jpg)
t-sne可视化。上面是GNN,下面是EGNN,从左到右分别是初始化embedding,第一层到第三层的node特征可视化
![[2019][cvpr]Edge-Labeling Graph Neural Network for Few-shot Learning 笔记_第10张图片](http://img.e-com-net.com/image/info8/ba12f48285894c2ca872bcda27472a4a.jpg)
边权的可视化
future work
For future work, we can consider another training loss which is related to the valid graph clustering such as the cycle loss [35]. Another promising direction is graph sparsification, e.g. constructing K-nearest neighbor graphs [50], that will make our algorithm more scalable to larger number of shots