30分钟学会用scikit-learn的基本回归方法(线性、决策树、SVM、KNN)和集成方法(随机森林,Adaboost和GBRT)
注:本教程是本人尝试使用scikit-learn的一些经验,scikit-learn真的超级容易上手,简单实用。30分钟学会用调用基本的回归方法和集成方法应该是够了。
本文主要参考了scikit-learn的官方网站
前言:本教程主要使用了numpy的最最基本的功能,用于生成数据,matplotlib用于绘图,scikit-learn用于调用机器学习方法。如果你不熟悉他们(我也不熟悉),没关系,看看numpy和matplotlib最简单的教程就够了。我们这个教程的程序不超过50行
1. 数据准备
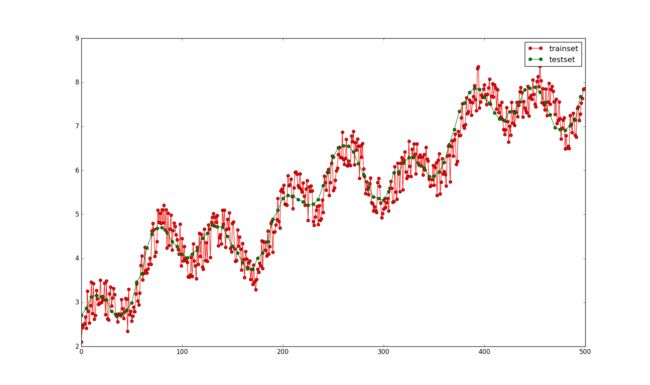
为了实验用,我自己写了一个二元函数,y=0.5*np.sin(x1)+ 0.5*np.cos(x2)+0.1*x1+3。其中x1的取值范围是0~50,x2的取值范围是-10~10,x1和x2的训练集一共有500个,测试集有100个。其中,在训练集的上加了一个-0.5~0.5的噪声。生成函数的代码如下:
def f(x1, x2):
y = 0.5 * np.sin(x1) + 0.5 * np.cos(x2) + 0.1 * x1 + 3
return y
def load_data():
x1_train = np.linspace(0,50,500)
x2_train = np.linspace(-10,10,500)
data_train = np.array([[x1,x2,f(x1,x2) + (np.random.random(1)-0.5)] for x1,x2 in zip(x1_train, x2_train)])
x1_test = np.linspace(0,50,100)+ 0.5 * np.random.random(100)
x2_test = np.linspace(-10,10,100) + 0.02 * np.random.random(100)
data_test = np.array([[x1,x2,f(x1,x2)] for x1,x2 in zip(x1_test, x2_test)])
return data_train, data_test其中训练集(y上加有-0.5~0.5的随机噪声)和测试集(没有噪声)的图像如下:
2. scikit-learn最简单的介绍。
scikit-learn非常简单,只需实例化一个算法对象,然后调用fit()函数就可以了,fit之后,就可以使用predict()函数来预测了,然后可以使用score()函数来评估预测值和真实值的差异,函数返回一个得分。例如调用决策树的方法如下
In [6]: from sklearn.tree import DecisionTreeRegressor
In [7]: clf = DecisionTreeRegressor()
In [8]: clf.fit(x_train,y_train)
Out[11]:
DecisionTreeRegressor(criterion='mse', max_depth=None, max_features=None,
max_leaf_nodes=None, min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter='best')
In [15]: result = clf.predict(x_test)
In [16]: clf.score(x_test,y_test)
Out[16]: 0.96352052312508396
In [17]: result
Out[17]:
array([ 2.44996735, 2.79065744, 3.21866981, 3.20188779, 3.04219101,
2.60239551, 3.35783805, 2.40556647, 3.12082094, 2.79870458,
2.79049667, 3.62826131, 3.66788213, 4.07241195, 4.27444808,
4.75036169, 4.3854911 , 4.52663074, 4.19299748, 4.42235821,
4.48263415, 4.16192621, 4.40477767, 3.76067775, 4.35353213,
4.6554961 , 4.99228199, 4.29504731, 4.55211437, 5.08229167,接下来,我们可以根据预测值和真值来画出一个图像。画图的代码如下:
plt.figure()
plt.plot(np.arange(len(result)), y_test,'go-',label='true value')
plt.plot(np.arange(len(result)),result,'ro-',label='predict value')
plt.title('score: %f'%score)
plt.legend()
plt.show()然后图像会显示如下:

3. 开始试验各种不同的回归方法
为了加快测试, 这里写了一个函数,函数接收不同的回归类的对象,然后它就会画出图像,并且给出得分.
函数基本如下:
def try_different_method(clf):
clf.fit(x_train,y_train)
score = clf.score(x_test, y_test)
result = clf.predict(x_test)
plt.figure()
plt.plot(np.arange(len(result)), y_test,'go-',label='true value')
plt.plot(np.arange(len(result)),result,'ro-',label='predict value')
plt.title('score: %f'%score)
plt.legend()
plt.show()train, test = load_data()
x_train, y_train = train[:,:2], train[:,2] #数据前两列是x1,x2 第三列是y,这里的y有随机噪声
x_test ,y_test = test[:,:2], test[:,2] # 同上,不过这里的y没有噪声3.1 常规回归方法
常规的回归方法有线性回归,决策树回归,SVM和k近邻(KNN)
3.1.1 线性回归
In [4]: from sklearn import linear_model
In [5]: linear_reg = linear_model.LinearRegression()
In [6]: try_different_method(linar_reg)
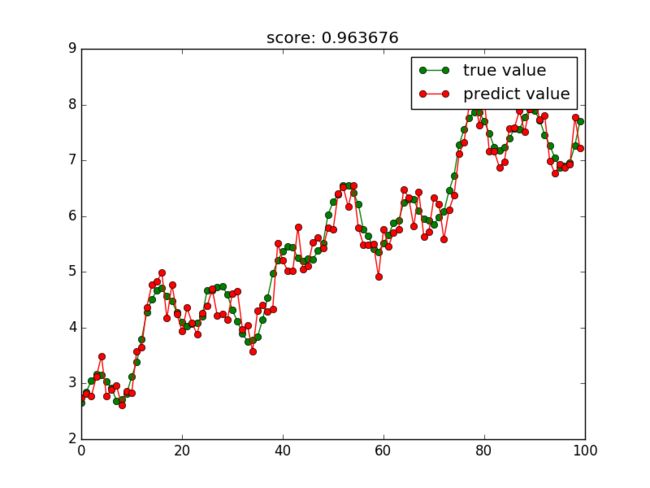
3.1.2数回归
from sklearn import tree
tree_reg = tree.DecisionTreeRegressor()
try_different_method(tree_reg)
然后决策树回归的图像就会显示出来:
3.1.3 SVM回归
In [7]: from sklearn import svm
In [8]: svr = svm.SVR()
In [9]: try_different_method(svr)
结果图像如下:

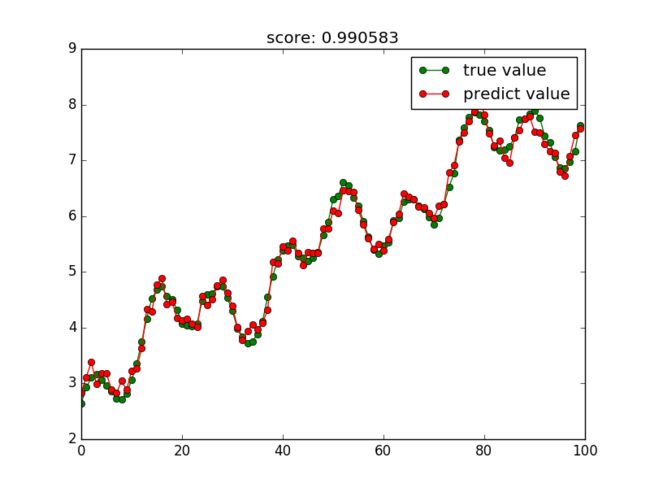
3.1.4 KNN
In [11]: from sklearn import neighbors
In [12]: knn = neighbors.KNeighborsRegressor()
In [13]: try_different_method(knn)
竟然KNN这个计算效能最差的算法效果最好
3.2 集成方法(随机森林,adaboost, GBRT)
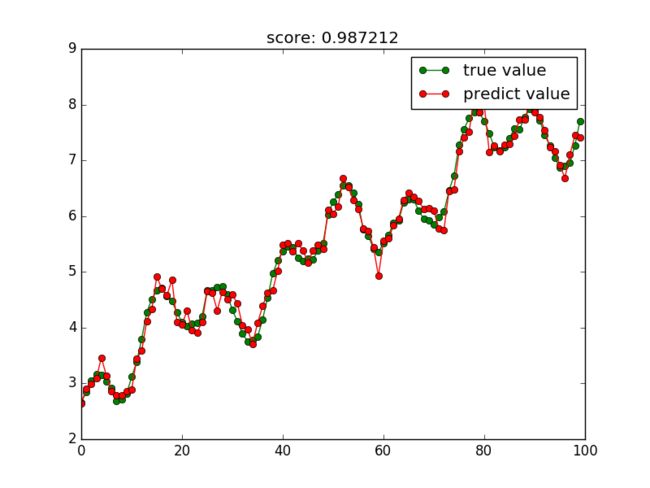
3.2.1随机森林
In [14]: from sklearn import ensemble
In [16]: rf =ensemble.RandomForestRegressor(n_estimators=20)#这里使用20个决策树
In [17]: try_different_method(rf)
3.2.2 Adaboost
In [18]: ada = ensemble.AdaBoostRegressor(n_estimators=50)
In [19]: try_different_method(ada)
图像如下:

3.2.3 GBRT
In [20]: gbrt = ensemble.GradientBoostingRegressor(n_estimators=100)
In [21]: try_different_method(gbrt)
图像如下

4. scikit-learn还有很多其他的方法,可以参考用户手册自行试验.
5.完整代码
我这里在pycharm写的代码,但是在pycharm里面不显示图形,所以可以把代码复制到ipython中,使用%paste方法复制代码片.
然后参照上面的各个方法导入算法,使用try_different_mothod()函数画图.
完整代码如下:
import numpy as np
import matplotlib.pyplot as plt
def f(x1, x2):
y = 0.5 * np.sin(x1) + 0.5 * np.cos(x2) + 3 + 0.1 * x1
return y
def load_data():
x1_train = np.linspace(0,50,500)
x2_train = np.linspace(-10,10,500)
data_train = np.array([[x1,x2,f(x1,x2) + (np.random.random(1)-0.5)] for x1,x2 in zip(x1_train, x2_train)])
x1_test = np.linspace(0,50,100)+ 0.5 * np.random.random(100)
x2_test = np.linspace(-10,10,100) + 0.02 * np.random.random(100)
data_test = np.array([[x1,x2,f(x1,x2)] for x1,x2 in zip(x1_test, x2_test)])
return data_train, data_test
train, test = load_data()
x_train, y_train = train[:,:2], train[:,2] #数据前两列是x1,x2 第三列是y,这里的y有随机噪声
x_test ,y_test = test[:,:2], test[:,2] # 同上,不过这里的y没有噪声
def try_different_method(clf):
clf.fit(x_train,y_train)
score = clf.score(x_test, y_test)
result = clf.predict(x_test)
plt.figure()
plt.plot(np.arange(len(result)), y_test,'go-',label='true value')
plt.plot(np.arange(len(result)),result,'ro-',label='predict value')
plt.title('score: %f'%score)
plt.legend()
plt.show()