DBSCAN与KMeans对比
DBSCAN也是基于密度的聚类算法
超参数:
EPS领域半径
Mmpts 核心点领域内点个数的阈值
核心概念:
核心点:一个对象在其半径内含有>Mmpts数目的点,则该点为核心点
边界点:一个对象在其半径内含有 噪音点:既不是核心点,也不是边界点的点。 import numpy as np x1,y1 = datasets.make_circles(n_samples=500,factor=0.6,noise=0.05) x=np.concatenate((x1,x2)) #kmeans聚类
import matplotlib.pyplot as plt
from sklearn import datasets
x2,y2 = datasets.make_blobs(n_samples=500,n_features=2,centers=[[1.2,1.2]], cluster_std=[[.1]])
plt.scatter(x[:,0],x[:,1])
from sklearn.cluster import KMeans
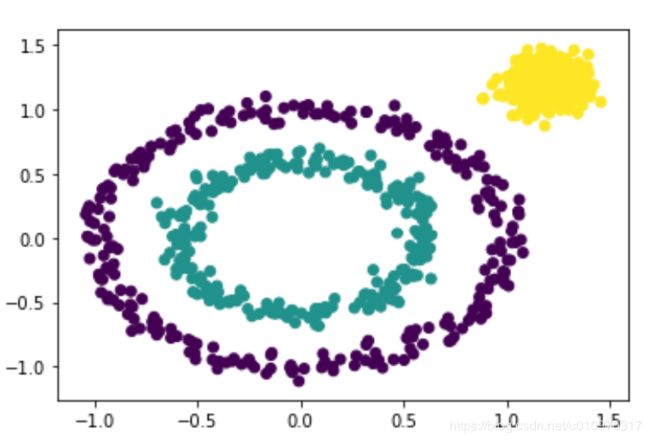
y_pred = KMeans(n_clusters=3,random_state=9).fit_predict(x)
plt.scatter(x[:,0],x[:,1],c=y_pred)
#dbscan聚类
from sklearn.cluster import DBSCAN
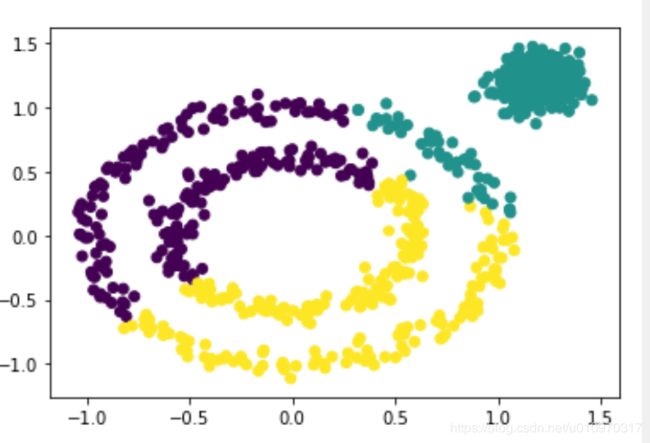
y_pred = DBSCAN(eps = 0.16, min_samples = 10).fit_predict(x)
plt.scatter(x[:,0],x[:,1],c=y_pred)