大话数据结构学习笔记 - 查找之顺序查找、折半查找、插值查找及斐波那契查找
大话数据结构学习笔记 - 查找之顺序查找、折半查找、插值查找及斐波那契查找
查找(Searching): 就是根据给定的某个值,在查找表中确定一个其关键字等于给定值的数据元素(或记录)
概论
概念
查找表(Search Table):由同一类型的数据元素(或记录)构成的集合
关键字(Key):数据元素中某个数据项的值,又称为键值,用来标识一个数据元素
主关键字(Primary Key):若关键字可以唯一的标识一个记录,则称此关键字为主关键字, 主关键字所在的数据项称为主关键码
次关键字(Secondary Key): 可以识别多个数据元素(或记录)的关键字
查找表
静态查找表
静态查找表(Static Search Table): 只做查找操作的查找表
- 查询某个特定数据元素是否在查找表中
- 检索某个特定数据元素和各种属性
动态查找表
动态查找表(Dynamic Search Table): 在查找过程中同时插入查找表中不存在的数据元素,或者从查找表中删除已经存在的某个数据元素
- 查找时插入数据元素
- 查找时删除数据元素
面向查找操作的数据结构称为查找结构
本文所有代码,示例数组为{0,1,16,24,35,47,59,62,73,88,99}, 区间为[1, 10], 返回下标0则表示查找失败
顺序表查找
顺序查找(Sequential Search) 又叫线性查找,是最基本的查找技术,它的查找过程是:从表中第一个(或最后一个)记录开始,逐个进行记录的关键字和给定值比较,若某个记录的关键字和给定值相等,则查找成功,找到所查的记录,如果知道最后一个(或第一个)记录,其关键字和给定值比较都不等时,则表中没有所查的纪录,查找不成功
复杂度:最好时,查找次数为1次,时间复杂度为 O(1) O ( 1 ) ; 最坏时,查找次数为n + 1次, 时间复杂度为 O(n) O ( n ) , 平均查找次数为 (n+1)/2 ( n + 1 ) / 2 , 故时间复杂度为 O(n) O ( n )
顺序查找算法
/* 无哨兵顺序查找,a为数组,n为要查找的数组个数,key为要查找的关键字 */
int Sequential_Search(int *a, int n, int key)
{
for(int i = 1; i <= n; i++) /* 元素值从下标 1 开始 */
{
if(a[i] == key)
return i;
}
return 0;
}顺序表查找优化
通过设置哨兵, 则不需要每次都与n比较,以判断是否越界
/* 有哨兵顺序查找 */
int Sequential_Search2(int *a, int n, int key)
{
int i = n; /* 循环从数组尾部开始 */
a[0] = key; /* 设置 a[0] 为关键字值,我们称之为 哨兵 */
while(a[i] != key)
i--;
return i; /* 返回 0 则说明查找失败 */
}有序表查找
折半查找
折半查找(Binary Search) 技术,又称为 二分查找。它的前提是线性表中的记录必须是关键码有序(通常从小到大有序), 线性表必须采用顺序存储。折半查找的基本思想是:在有序表中,取中间记录作为比较对象,若给定值与中间记录的关键字相等,则查找成功;若给定值小于中间记录的关键字,则在中间记录的左半区继续查找;若给定值大于中间记录的关键字,则在中间记录的右半区继续查找。不断重复上述过程,知道查找成功,或所有查找区域无记录,查找失败为止。
复杂度: 时间复杂度为 O(log(n)) O ( l o g ( n ) )
前提: 有序表顺序存储, 对于静态查找表,一次排序后不再变化,这样的算法比较好。但若经常执行插入或删除操作的表,不建议使用
/* 折半查找 */
int Binary_Search(int *a, int n, int key)
{
int low = 1, high = n, middle; // 此处元素区间为 [1, n], 也可以使用 [0, n - 1]
while(low <= high)
{
middle = low + (high - low) / 2; // 寻找中间位置, 不使用 (middle = low + high) / 2 原因是可能溢出
if(a[middle] < key) // 若查找值比中位数大
low = middle + 1;
else if(a[middle] > key) // 若查找值比中位数小
high = middle - 1;
else
return middle; /* 若相等则说明 middle 即为查找到的位置 */
}
return 0;
}插值查找
对于折半查找的思考是为什么一定要折半,而不是折四分之一或者更多呢?比如在字典查apple单词或zoo单词,肯定不会从中间开始查起,而是有一定目的的往前翻或往后翻。
同样,若在取值范围0~1000之间的100个元素从小到大均匀分布的数组中查找5,自然会考虑从数组下标较小的开始查找。
折半查找中的middle取值公式为 middle=low+high2=low+high−low2 m i d d l e = l o w + h i g h 2 = l o w + h i g h − l o w 2 , 可通过改进该公式优化折半查找算法
middle=low+key−a[low]a[high]−a[low](high−low) m i d d l e = l o w + k e y − a [ l o w ] a [ h i g h ] − a [ l o w ] ( h i g h − l o w ) , 将参数 12 1 2 改为 key−a[low]a[high]−a[low] k e y − a [ l o w ] a [ h i g h ] − a [ l o w ] , 可以让middle值更快的靠近关键字所在的位置,也就减少了比较次数
插值查找(Interpolation Search): 是根据要查找的关键字key与查找表中最大最小记录的关键字比较后的查找方法,其核心就在于插值公式 key−a[low]a[high]−a[low] k e y − a [ l o w ] a [ h i g h ] − a [ l o w ]
复杂度: 也是 O(log(n)) O ( l o g ( n ) ) , 但对于表长较大,而关键字分布有比较均匀的查找表来说,其平均性能要比折半查找好得多
/* 插值查找 */
int Interpolation_Search(int *a, int n, int key)
{
int low = 1, high = n, middle;
while(a[low] != a[high] && key >= a[low] && key <= a[high]) // 此处判断条件是为了防止 key - a[low] 为负值的情况
{
middle = low + (high - low) * (key - a[low]) / (a[high] - a[low]);
if(key > a[middle])
low = middle + 1;
else if(key < a[middle])
high = middle - 1;
else
return middle;
}
if(key == a[low]) return low; // 如果是2, 2, 2, 2这种全部重复元素,就不会上面的循环,为了防止 key - a[low] 为 0 的情况,则此处处理该情况,返回第一个 2
return 0;
}关于插值查找算法,下面的某个博客讲解非常详细,要详细阅读
斐波那契查找
黄金分割或黄金比例是指事物各部分间一定的数学比例关系,即将整体分割成比例为1:0.618的比例被认为最完美。而斐波那契数列两个相邻想的比例会逐渐接近0.618,为了使用该比例,则有了斐波那契查找算法。
斐波那契数列的最重要的性质是从第三个数字起,每个数都等于前两个数之和,即f[n] = f[n-1] + f[n-2], 而f[n-1]和f[n-2]又可以继续分解,直到f[1]和f[2]为止。
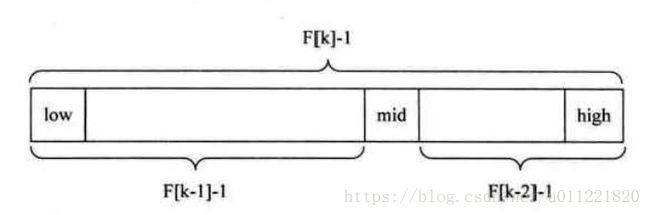
算法核心
- 当
key = a[mid]时,查找成功 - 当
key < a[mid]时,新范围是第low个到第mid - 1个,此时范围个数为F[k - 1] - 1个 - 当
key > a[mid]时,新范围是第mid + 1个到第high个,此时范围个数为F[k - 2] - 1个
复杂度: 若要查找的记录始终出现在右侧,时间复杂度为 O(log(n)) O ( l o g ( n ) ) , 但优于折半查找。若始终出现在左侧,则效率低于折半查找。并且折半查找进行的是加法与除法运算 mid=(low+high)/2 m i d = ( l o w + h i g h ) / 2 ; 插值查找进行的是复杂的四则运算 mid=low+(high−low)∗key−a[low]a[high]−a[low] m i d = l o w + ( h i g h − l o w ) ∗ k e y − a [ l o w ] a [ h i g h ] − a [ l o w ] , 而斐波那契查找只是最简单的加减法运算 mid=low+F[k−1]−1 m i d = l o w + F [ k − 1 ] − 1 ,当然这也会影响一些。
/* 斐波那契查找 */
int Fibonacci_Search(int *a, int n, int key)
{
int low = 1, high = n, k = 0, middle;
while (n > F[k] - 1) /* 计算 n 处于斐波那契数列的位置 */
k++;
for(int i = n; i < F[k] - 1; i++) /* 填充数组,使其长度为斐波那契数列的最大值 */
a[i] = a[n];
while(low <= high)
{
middle = low + F[k - 1] - 1; /* 计算当前分隔的下标 */
if(key < a[middle]) /* 若当前查找记录小于当前分隔记录 */
{
high = middle - 1; /* 排除右半边的元素 */
k = k - 1; /* F[k - 1] 是左半边的长度 */
}
else if(key > a[middle]) /* 若查找记录大于当前分隔记杀 */
{
low = middle + 1; /* 排除左半边的元素 */
k = k - 2; /* F[k - 2] 是右半边的长度 */
}
else{
if(middle <= n) /* 若相等则说明 mid 即为查找到的位置 */
return middle;
else
return n; /* 若 middle > n 说明是补全数值,返回 n */
}
}
return 0;
}源码
静态查找-顺序查找、折半查找、插值查找及斐波那契查找
推荐博客
- (二分查找有几种写法?它们的区别是什么? - 胖胖的回答 - 知乎
- 二分查找(面试必备)
- July. 有序数组的查找
- 【算法】先生,您点的查找套餐到了(二分、插值和斐波那契查找 (必看,有关插值查找的各种问题详解))