Java集合类框架学习 5.3—— ConcurrentHashMap(JDK1.8)
以下内容,如有问题,烦请指出,谢谢!
现在看下1.8版本的ConcurrentHashMap,改动很大。目前本人也有些地方没有弄懂,具体来说就是扩容有关的那一块,有几个地方还不太对得上,单独理解是没问题的,联合起来发现存在些矛盾的地方。所以下面的扩容有关的,各位看官还是细看,自己也要想下。
零、主要改动
参照对象为jdk1.7的ConcurrentHashMap,当然,熟悉jdk1.8的HashMap能够更好地理解一些改动,HashMap和ConcurrentHashMap本来就有很多共通的东西。
1、jdk1.8的ConcurrentHashMap不再使用Segment代理Map操作这种设计,整体结构变为HashMap这种结构,但是依旧保留分段锁的思想。之前版本是每个Segment都持有一把锁,1.8版本改为锁住恰好装在一个hash桶本身位置上的节点,也就是hash桶的第一个节点 tabAt(table, i),后面直接叫第一个节点。它可能是Node链表的头结点、保留节点ReservationNode、或者是TreeBin节点(TreeBin节点持有红黑树的根节点)。还有,1.8的节点变成了4种,这个后面细说,是个重要的知识。
2、可以多线程并发来完成扩容这个耗时耗力的操作。在之前的版本中如果Segment正在进行扩容操作,其他写线程都会被阻塞,jdk1.8改为一个写线程触发了扩容操作,其他写线程进行写入操作时,可以帮助它来完成扩容这个耗时的操作。多线程并发扩容这部分后面细说。
3、因为多线程并发扩容的存在,导致的其他操作的实现上会有比较大的改动,常见的get/put/remove/replace/clear,以及迭代操作,都要考虑并发扩容的影响。
4、使用新的计数方法。不使用Segment时,如果直接使用一个volatile类变量计数,因为每次读写volatile变量的开销很大,高并发时效率不如之前版本的使用Segment时的计数方式。jdk1.8新增了一个用与高并发情况的计数工具类java.util.concurrent.atomic.LongAdder,此类是基本思想和1.7及以前的ConcurrentHashMap一样,使用了一层中间类,叫做Cell(类似Segment这个类)的计数单元,来实现分段计数,最后合并统计一次。因为不同的计数单元可以承担不同的线程的计数要求,减少了线程之间的竞争,在1.8的ConcurrentHashMap基本结果改变时,继续保持和分段计数一样的并发计数效率。
关于这个LongAdder,专门写了一篇,可以看下 这里。
5、同1.8版本的HashMap,当一个hash桶中的hash冲突节点太多时,把链表变为红黑树,提高冲突时的查找效率。
6、一些小的改进,具体见后面的源码上我写的注释。
7、函数式编程、Stream api相关的新功能,占据了1.8的大概40%的代码,这部分这里就先不说了。
一、基本性质
改动的几点除外,其余的基本和之前版本的ConcurrentHashMap一致。
因为不再使用中间层的Segment,整体设计结构基本上和1.8版本的HashMap一样,和普通的HashMap很像了,图就不画了。
二、常量和变量
1、常量
只对相对1.7的有改动的常量,或者新增的常量作注释。特别注意下,concurrencyLevel和loadFactor都不再是原来的作用了,保留很大程度只是为了兼容之前的版本。
private static final int MAXIMUM_CAPACITY = 1 << 30;
private static final int DEFAULT_CAPACITY = 16;
// 下面3个,在1.8的HashMap中也有相同的常量
// 一个hash桶中hash冲突的数目大于此值时,把链表转化为红黑树,加快hash冲突时的查找速度
static final int TREEIFY_THRESHOLD = 8;
// 一个hash桶中hash冲突的数目小于等于此值时,把红黑树转化为链表,当数目比较少时,链表的实际查找速度更快,也是为了查找效率
static final int UNTREEIFY_THRESHOLD = 6;
// 当table数组的长度小于此值时,不会把链表转化为红黑树。所以转化为红黑树有两个条件,还有一个是 TREEIFY_THRESHOLD
static final int MIN_TREEIFY_CAPACITY = 64;
// 虚拟机限制的最大数组长度,在ArrayList中有说过,jdk1.8新引入的,ConcurrentHashMap的主体代码中是不使用这个的,主要用在Collection.toArray两个方法中
static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
// 默认并行级别,主体代码中未使用此常量,为了兼容性,保留了之前的定义,主要是配合同样是为了兼容性的Segment使用,另外在构造方法中有一些作用
// 千万注意,1.8的并发级别有了大的改动,具体并发级别可以认为是hash桶是数量,也就是容量,会随扩容而改变,不再是固定值
private static final int DEFAULT_CONCURRENCY_LEVEL = 16;
// 加载因子,为了兼容性,保留了这个常量(名字变了),配合同样是为了兼容性的Segment使用
// 1.8的ConcurrentHashMap的加载因子固定为 0.75,构造方法中指定的参数是不会被用作loadFactor的,为了计算方便,统一使用 n - (n >> 2) 代替浮点乘法 *0.75
private static final float LOAD_FACTOR = 0.75f;
// 扩容操作中,transfer这个步骤是允许多线程的,这个常量表示一个线程执行transfer时,最少要对连续的16个hash桶进行transfer
// (不足16就按16算,多控制下正负号就行)
// 也就是单线程执行transfer时的最小任务量,单位为一个hash桶,这就是线程的transfer的步进(stride)
// 最小值是DEFAULT_CAPACITY,不使用太小的值,避免太小的值引起transfer时线程竞争过多,如果计算出来的值小于此值,就使用此值
// 正常步骤中会根据CPU核心数目来算出实际的,一个核心允许8个线程并发执行扩容操作的transfer步骤,这个8是个经验值,不能调整的
// 因为transfer操作不是IO操作,也不是死循环那种100%的CPU计算,CPU计算率中等,1核心允许8个线程并发完成扩容,理想情况下也算是比较合理的值
// 一段代码的IO操作越多,1核心对应的线程就要相应设置多点,CPU计算越多,1核心对应的线程就要相应设置少一些
// 表明:默认的容量是16,也就是默认构造的实例,第一次扩容实际上是单线程执行的,看上去是可以多线程并发(方法允许多个线程进入),
// 但是实际上其余的线程都会被一些if判断拦截掉,不会真正去执行扩容
private static final int MIN_TRANSFER_STRIDE = 16;
// 用于生成每次扩容都唯一的生成戳的数,最小是6。很奇怪,这个值不是常量,但是也不提供修改方法。
/** The number of bits used for generation stamp in sizeCtl. Must be at least 6 for 32bit arrays. */
private static int RESIZE_STAMP_BITS = 16;
// 最大的扩容线程的数量,如果上面的 RESIZE_STAMP_BITS = 32,那么此值为 0,这一点也很奇怪。
/** The maximum number of threads that can help resize. Must fit in 32 - RESIZE_STAMP_BITS bits. */
private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1;
// 移位量,把生成戳移位后保存在sizeCtl中当做扩容线程计数的基数,相反方向移位后能够反解出生成戳
/** The bit shift for recording size stamp in sizeCtl. */
private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS;
// 下面几个是特殊的节点的hash值,正常节点的hash值在hash函数中都处理过了,不会出现负数的情况,特殊节点在各自的实现类中有特殊的遍历方法
// ForwardingNode的hash值,ForwardingNode是一种临时节点,在扩进行中才会出现,并且它不存储实际的数据
// 如果旧数组的一个hash桶中全部的节点都迁移到新数组中,旧数组就在这个hash桶中放置一个ForwardingNode
// 读操作或者迭代读时碰到ForwardingNode时,将操作转发到扩容后的新的table数组上去执行,写操作碰见它时,则尝试帮助扩容
/** Encodings for Node hash fields. See above for explanation. */
static final int MOVED = -1; // hash for forwarding nodes
// TreeBin的hash值,TreeBin是ConcurrentHashMap中用于代理操作TreeNode的特殊节点,持有存储实际数据的红黑树的根节点
// 因为红黑树进行写入操作,整个树的结构可能会有很大的变化,这个对读线程有很大的影响,
// 所以TreeBin还要维护一个简单读写锁,这是相对HashMap,这个类新引入这种特殊节点的重要原因
static final int TREEBIN = -2; // hash for roots of trees
// ReservationNode的hash值,ReservationNode是一个保留节点,就是个占位符,不会保存实际的数据,正常情况是不会出现的,
// 在jdk1.8新的函数式有关的两个方法computeIfAbsent和compute中才会出现
static final int RESERVED = -3; // hash for transient reservations
// 用于和负数hash值进行 & 运算,将其转化为正数(绝对值不相等),Hashtable中定位hash桶也有使用这种方式来进行负数转正数
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
// CPU的核心数,用于在扩容时计算一个线程一次要干多少活
/** Number of CPUS, to place bounds on some sizings */
static final int NCPU = Runtime.getRuntime().availableProcessors();
// 在序列化时使用,这是为了兼容以前的版本
/** For serialization compatibility. */
private static final ObjectStreamField[] serialPersistentFields = {
new ObjectStreamField("segments", Segment[].class),
new ObjectStreamField("segmentMask", Integer.TYPE),
new ObjectStreamField("segmentShift", Integer.TYPE)
};
// Unsafe初始化跟1.7版本的基本一样,不说了
2、变量
只对相对1.7的有改动的或者新增的变量作注释。变量是理解1.8的新的改动的关键,在前面说了几点关键的改动,nextTable、sizeCtl、transferIndex与多线程扩容有关,baseCount、cellsBusy、counterCells与新的高效的并发计数方式有关。
另外说明下:本人认为sizeCtl的英文注释是有误的,所以各位请务必仔细看下sizeCtl的,结合扩容相关的一起看。网上有不少直接按照sizeCtl的英文注释来理解代码,这样是不对的。
transient volatile Node[] table;
private transient KeySetView keySet;
private transient ValuesView values;
private transient EntrySetView entrySet;
// 扩容后的新的table数组,只有在扩容时才有用
// nextTable != null,说明扩容方法还没有真正退出,一般可以认为是此时还有线程正在进行扩容,
// 极端情况需要考虑此时扩容操作只差最后给几个变量赋值(包括nextTable = null)的这个大的步骤,
// 这个大步骤执行时,通过sizeCtl经过一些计算得出来的扩容线程的数量是0
private transient volatile Node[] nextTable;
// 非常重要的一个属性,源码中的英文翻译,直译过来是下面的四行文字的意思
// sizeCtl = -1,表示有线程正在进行真正的初始化操作
// sizeCtl = -(1 + nThreads),表示有nThreads个线程正在进行扩容操作
// sizeCtl > 0,表示接下来的真正的初始化操作中使用的容量,或者初始化/扩容完成后的threshold
// sizeCtl = 0,默认值,此时在真正的初始化操作中使用默认容量
// 但是,通过我对源码的理解,这段注释实际上是有问题的,
// 有问题的是第二句,sizeCtl = -(1 + nThreads)这个,网上好多都是用第二句的直接翻译去解释代码,这样理解是错误的
// 默认构造的16个大小的ConcurrentHashMap,只有一个线程执行扩容时,sizeCtl = -2145714174,
// 但是照这段英文注释的意思,sizeCtl的值应该是 -(1 + 1) = -2
// sizeCtl在小于0时的确有记录有多少个线程正在执行扩容任务的功能,但是不是这段英文注释说的那样直接用 -(1 + nThreads)
// 实际中使用了一种生成戳,根据生成戳算出一个基数,不同轮次的扩容操作的生成戳都是唯一的,来保证多次扩容之间不会交叉重叠,
// 当有n个线程正在执行扩容时,sizeCtl在值变为 (基数 + n)
// 1.8.0_111的源码的383-384行写了个说明:A generation stamp in field sizeCtl ensures that resizings do not overlap.
/**
* Table initialization and resizing control.
* When negative, the table is being initialized or resized: -1 for initialization,
* else -(1 + the number of active resizing threads).
* Otherwise, when table is null, holds the initial table size to use upon creation,
* or 0 for default.
* After initialization, holds the next element count value upon which to resize the table.
*/
private transient volatile int sizeCtl;
// 下一个transfer任务的起始下标index 加上1 之后的值,transfer时下标index从length - 1开始往0走
// transfer时方向是倒过来的,迭代时是下标从小往大,二者方向相反,尽量减少扩容时transefer和迭代两者同时处理一个hash桶的情况,
// 顺序相反时,二者相遇过后,迭代没处理的都是已经transfer的hash桶,transfer没处理的,都是已经迭代的hash桶,冲突会变少
// 下标在[nextIndex - 实际的stride (下界要 >= 0), nextIndex - 1]内的hash桶,就是每个transfer的任务区间
// 每次接受一个transfer任务,都要CAS执行 transferIndex = transferIndex - 实际的stride,
// 保证一个transfer任务不会被几个线程同时获取(相当于任务队列的size减1)
// 当没有线程正在执行transfer任务时,一定有transferIndex <= 0,这是判断是否需要帮助扩容的重要条件(相当于任务队列为空)
private transient volatile int transferIndex;
// 下面三个主要与统计数目有关,可以参考jdk1.8新引入的java.util.concurrent.atomic.LongAdder的源码,帮助理解
// 计数器基本值,主要在没有碰到多线程竞争时使用,需要通过CAS进行更新
private transient volatile long baseCount;
// CAS自旋锁标志位,用于初始化,或者counterCells扩容时
private transient volatile int cellsBusy;
// 用于高并发的计数单元,如果初始化了这些计数单元,那么跟table数组一样,长度必须是2^n的形式
private transient volatile CounterCell[] counterCells;
三、基本类
1、Node:基本节点/普通节点
此节点就是一个很普通的Entry,在链表形式保存才使用这种节点,它存储实际的数据,基本结构类似于1.8的HashMap.Node,和1.7的Concurrent.HashEntry。
// 此类不会在ConcurrentHashMap以外被修改,只读迭代可以利用这个类,迭代时的写操作需要由另一个内部类MapEntry代理执行写操作
// 此类的子类具有负数hash值,并且不存储实际的数据,如果不使用子类直接使用这个类,那么key和val永远不会为null
static class Node implements Map.Entry {
final int hash;
final K key;
volatile V val;
volatile Node next;
Node(int hash, K key, V val, Node next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return val; }
public final int hashCode() { return key.hashCode() ^ val.hashCode(); }
public final String toString(){ return key + "=" + val; }
// 不支持来自ConcurrentHashMap外部的修改,跟1.7的一样,迭代操作需要通过另外一个内部类MapEntry来代理,迭代写会重新执行一次put操作
// 迭代中可以改变value,是一种写操作,此时需要保证这个节点还在map中,
// 因此就重新put一次:节点不存在了,可以重新让它存在;节点还存在,相当于replace一次
// 设计成这样主要是因为ConcurrentHashMap并非为了迭代操作而设计,它的迭代操作和其他写操作不好并发,
// 迭代时的读写都是弱一致性的,碰见并发修改时尽量维护迭代的一致性
// 返回值V也可能是个过时的值,保证V是最新的值会比较困难,而且得不偿失
public final V setValue(V value) {
throw new UnsupportedOperationException();
}
public final boolean equals(Object o) {
Object k, v, u; Map.Entry e;
return ((o instanceof Map.Entry) && (k = (e = (Map.Entry)o).getKey()) != null && (v = e.getValue()) != null &&
(k == key || k.equals(key)) && (v == (u = val) || v.equals(u)));
}
// 从此节点开始查找k对应的节点
// 这里的实现是专为链表实现的,一般作用于头结点,各种特殊的子类有自己独特的实现
// 不过主体代码中进行链表查找时,因为要特殊判断下第一个节点,所以很少直接用下面这个方法,
// 而是直接写循环遍历链表,子类的查找则是用子类中重写的find方法
/** Virtualized support for map.get(); overridden in subclasses. */
Node find(int h, Object k) {
Node e = this;
if (k != null) {
do {
K ek;
if (e.hash == h && ((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
} while ((e = e.next) != null);
}
return null;
}
}
2、TreeNode:红黑树节点
在红黑树形式保存时才存在,它也存储有实际的数据,结构和1.8的HashMap的TreeNode一样,一些方法的实现代码也基本一样。不过,ConcurrentHashMap对此节点的操作,都会由TreeBin来代理执行。也可以把这里的TreeNode看出是有一半功能的HashMap.TreeNode,另一半功能在ConcurrentHashMap.TreeBin中。
红黑树节点本身保存有普通链表节点Node的所有属性,因此可以使用两种方式进行读操作。
static final class TreeNode extends Node {
TreeNode parent; // red-black tree links
TreeNode left;
TreeNode right;
// 新添加的prev指针是为了删除方便,删除链表的非头节点的节点,都需要知道它的前一个节点才能进行删除,所以直接提供一个prev指针
TreeNode prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node next, TreeNode parent) {
super(hash, key, val, next);
this.parent = parent;
}
Node find(int h, Object k) {
return findTreeNode(h, k, null);
}
// 以当前节点 this 为根节点开始遍历查找,跟HashMap.TreeNode.find实现一样
final TreeNode findTreeNode(int h, Object k, Class kc) {
if (k != null) {
TreeNode p = this;
do {
int ph, dir; K pk; TreeNode q;
TreeNode pl = p.left, pr = p.right;
if ((ph = p.hash) > h)
p = pl;
else if (ph < h)
p = pr;
else if ((pk = p.key) == k || (pk != null && k.equals(pk)))
return p;
else if (pl == null)
p = pr;
else if (pr == null)
p = pl;
else if ((kc != null || (kc = comparableClassFor(k)) != null) && (dir = compareComparables(kc, k, pk)) != 0)
p = (dir < 0) ? pl : pr;
else if ((q = pr.findTreeNode(h, k, kc)) != null) // 对右子树进行递归查找
return q;
else
p = pl; // 前面递归查找了右边子树,这里循环时只用一直往左边找
} while (p != null);
}
return null;
}
}
3、ForwardingNode:转发节点
ForwardingNode是一种临时节点,在扩容进行中才会出现,hash值固定为-1,并且它不存储实际的数据数据。如果旧数组的一个hash桶中全部的节点都迁移到新数组中,旧数组就在这个hash桶中放置一个ForwardingNode。读操作或者迭代读时碰到ForwardingNode时,将操作转发到扩容后的新的table数组上去执行,写操作碰见它时,则尝试帮助扩容。
static final class ForwardingNode extends Node {
final Node[] nextTable;
ForwardingNode(Node[] tab) {
super(MOVED, null, null, null);
this.nextTable = tab;
}
// ForwardingNode的查找操作,直接在新数组nextTable上去进行查找
Node find(int h, Object k) {
// loop to avoid arbitrarily deep recursion on forwarding nodes 使用循环,避免多次碰到ForwardingNode导致递归过深
outer: for (Node[] tab = nextTable;;) {
Node e; int n;
if (k == null || tab == null || (n = tab.length) == 0 || (e = tabAt(tab, (n - 1) & h)) == null)
return null;
for (;;) {
int eh; K ek;
if ((eh = e.hash) == h && ((ek = e.key) == k || (ek != null && k.equals(ek)))) // 第一个节点就是要找的节点,直接返回
return e;
if (eh < 0) {
if (e instanceof ForwardingNode) { // 继续碰见ForwardingNode的情况,这里相当于是递归调用一次本方法
tab = ((ForwardingNode)e).nextTable;
continue outer;
}
else
return e.find(h, k); // 碰见特殊节点,调用其find方法进行查找
}
if ((e = e.next) == null) // 普通节点直接循环遍历链表
return null;
}
}
}
} TreeBin的hash值固定为-2,它是ConcurrentHashMap中用于代理操作TreeNode的特殊节点,持有存储实际数据的红黑树的根节点。因为红黑树进行写入操作,整个树的结构可能会有很大的变化,这个对读线程有很大的影响,所以TreeBin还要维护一个简单读写锁,这是相对HashMap,这个类新引入这种特殊节点的重要原因。
// 红黑树节点TreeNode实际上还保存有链表的指针,因此也可以用链表的方式进行遍历读取操作
// 自身维护一个简单的读写锁,不用考虑写-写竞争的情况
// 不是全部的写操作都要加写锁,只有部分的put/remove需要加写锁
// 很多方法的实现和jdk1.8的ConcurrentHashMap.TreeNode里面的方法基本一样,可以互相参考
static final class TreeBin extends Node {
TreeNode root; // 红黑树结构的跟节点
volatile TreeNode first; // 链表结构的头节点
volatile Thread waiter; // 最近的一个设置 WAITER 标识位的线程
volatile int lockState; // 整体的锁状态标识位
// values for lockState
// 二进制001,红黑树的 写锁状态
static final int WRITER = 1; // set while holding write lock
// 二进制010,红黑树的 等待获取写锁的状态,中文名字太长,后面用 WAITER 代替
static final int WAITER = 2; // set when waiting for write lock
// 二进制100,红黑树的 读锁状态,读锁可以叠加,也就是红黑树方式可以并发读,每有一个这样的读线程,lockState都加上一个READER的值
static final int READER = 4; // increment value for setting read lock
// 重要的一点,红黑树的 读锁状态 和 写锁状态 是互斥的,但是从ConcurrentHashMap角度来说,读写操作实际上可以是不互斥的
// 红黑树的 读、写锁状态 是互斥的,指的是以红黑树方式进行的读操作和写操作(只有部分的put/remove需要加写锁)是互斥的
// 但是当有线程持有红黑树的 写锁 时,读线程不会以红黑树方式进行读取操作,而是使用简单的链表方式进行读取,此时读操作和写操作可以并发执行
// 当有线程持有红黑树的 读锁 时,写线程可能会阻塞,不过因为红黑树的查找很快,写线程阻塞的时间很短
// 另外一点,ConcurrentHashMap的put/remove/replace方法本身就会锁住TreeBin节点,这里不会出现写-写竞争的情况,因此这里的读写锁可以实现得很简单
// 在hashCode相等并且不是Comparable类时才使用此方法进行判断大小
static int tieBreakOrder(Object a, Object b) {
int d;
if (a == null || b == null || (d = a.getClass().getName().compareTo(b.getClass().getName())) == 0)
d = (System.identityHashCode(a) <= System.identityHashCode(b) ? -1 : 1);
return d;
}
// 用以b为头结点的链表创建一棵红黑树
TreeBin(TreeNode b) {
super(TREEBIN, null, null, null);
this.first = b;
TreeNode r = null;
for (TreeNode x = b, next; x != null; x = next) {
next = (TreeNode)x.next;
x.left = x.right = null;
if (r == null) {
x.parent = null;
x.red = false;
r = x;
}
else {
K k = x.key;
int h = x.hash;
Class kc = null;
for (TreeNode p = r;;) {
int dir, ph;
K pk = p.key;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((kc == null && (kc = comparableClassFor(k)) == null) || (dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk);
TreeNode xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
r = balanceInsertion(r, x);
break;
}
}
}
}
this.root = r;
assert checkInvariants(root);
}
/**
* Acquires write lock for tree restructuring.
*/
// 对根节点加 写锁,红黑树重构时需要加上 写锁
private final void lockRoot() {
if (!U.compareAndSwapInt(this, LOCKSTATE, 0, WRITER)) // 先尝试获取一次 写锁
contendedLock(); // offload to separate method 单独抽象出一个方法,直到获取到 写锁 这个调用才会返回
}
// 释放 写锁
private final void unlockRoot() {
lockState = 0;
}
// 可能会阻塞写线程,当写线程获取到写锁时,才会返回
// ConcurrentHashMap的put/remove/replace方法本身就会锁住TreeBin节点,这里不会出现写-写竞争的情况
// 本身这个方法就是给写线程用的,因此只用考虑 读锁 阻碍线程获取 写锁,不用考虑 写锁 阻碍线程获取 写锁,
// 这个读写锁本身实现得很简单,处理不了写-写竞争的情况
// waiter要么是null,要么是当前线程本身
private final void contendedLock() {
boolean waiting = false;
for (int s;;) {
// ~WAITER是对WAITER进行二进制取反,当此时没有线程持有 读锁(不会有线程持有 写锁)时,这个if为真
if (((s = lockState) & ~WAITER) == 0) {
if (U.compareAndSwapInt(this, LOCKSTATE, s, WRITER)) {
// 在 读锁、写锁 都没有被别的线程持有时,尝试为自己这个写线程获取 写锁,同时清空 WAITER 状态的标识位
if (waiting) // 获取到写锁时,如果自己曾经注册过 WAITER 状态,将其清除
waiter = null;
return;
}
}
else if ((s & WAITER) == 0) { // 有线程持有 读锁(不会有线程持有 写锁),并且当前线程不是 WAITER 状态时,这个else if为真
if (U.compareAndSwapInt(this, LOCKSTATE, s, s | WAITER)) { // 尝试占据 WAITER 状态标识位
waiting = true; // 表明自己正处于 WAITER 状态,并且让下一个被用于进入下一个 else if
waiter = Thread.currentThread();
}
}
else if (waiting) // 有线程持有 读锁(不会有线程持有 写锁),并且当前线程处于 WAITER 状态时,这个else if为真
LockSupport.park(this); // 阻塞自己
}
}
// 从根节点开始遍历查找,找到“相等”的节点就返回它,没找到就返回null
// 当有写线程加上 写锁 时,使用链表方式进行查找
final Node find(int h, Object k) {
if (k != null) {
for (Node e = first; e != null; ) {
int s; K ek;
// 两种特殊情况下以链表的方式进行查找
// 1、有线程正持有 写锁,这样做能够不阻塞读线程
// 2、WAITER时,不再继续加 读锁,能够让已经被阻塞的写线程尽快恢复运行,或者刚好让某个写线程不被阻塞
if (((s = lockState) & (WAITER|WRITER)) != 0) {
if (e.hash == h && ((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
e = e.next;
}
else if (U.compareAndSwapInt(this, LOCKSTATE, s, s + READER)) { // 读线程数量加1,读状态进行累加
TreeNode r, p;
try {
p = ((r = root) == null ? null : r.findTreeNode(h, k, null));
} finally {
Thread w;
// 如果这是最后一个读线程,并且有写线程因为 读锁 而阻塞,那么要通知它,告诉它可以尝试获取写锁了
// U.getAndAddInt(this, LOCKSTATE, -READER)这个操作是在更新之后返回lockstate的旧值,
// 不是返回新值,相当于先判断==,再执行减法
if (U.getAndAddInt(this, LOCKSTATE, -READER) == (READER|WAITER) && (w = waiter) != null)
LockSupport.unpark(w); // 让被阻塞的写线程运行起来,重新去尝试获取 写锁
}
return p;
}
}
}
return null;
}
// 用于实现ConcurrentHashMap.putVal
final TreeNode putTreeVal(int h, K k, V v) {
Class kc = null;
boolean searched = false;
for (TreeNode p = root;;) {
int dir, ph; K pk;
if (p == null) {
first = root = new TreeNode(h, k, v, null, null);
break;
}
else if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((pk = p.key) == k || (pk != null && k.equals(pk)))
return p;
else if ((kc == null && (kc = comparableClassFor(k)) == null) || (dir = compareComparables(kc, k, pk)) == 0) {
if (!searched) {
TreeNode q, ch;
searched = true;
if (((ch = p.left) != null && (q = ch.findTreeNode(h, k, kc)) != null) ||
((ch = p.right) != null && (q = ch.findTreeNode(h, k, kc)) != null))
return q;
}
dir = tieBreakOrder(k, pk);
}
TreeNode xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
TreeNode x, f = first;
first = x = new TreeNode(h, k, v, f, xp);
if (f != null)
f.prev = x;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
// 下面是有关put加 写锁 部分
// 二叉搜索树新添加的节点,都是取代原来某个的NIL节点(空节点,null节点)的位置
if (!xp.red) // xp是新添加的节点的父节点,如果它是黑色的,新添加一个红色节点就能够保证x这部分的一部分路径关系不变,
// 这是insert重新染色的最最简单的情况
x.red = true; // 因为这种情况就是在树的某个末端添加节点,不会改变树的整体结构,对读线程使用红黑树搜索的搜索路径没影响
else { // 其他情况下会有树的旋转的情况出现,当读线程使用红黑树方式进行查找时,可能会因为树的旋转,导致多遍历、少遍历节点,影响find的结果
lockRoot(); // 除了那种最最简单的情况,其余的都要加 写锁,让读线程用链表方式进行遍历读取
try {
root = balanceInsertion(root, x);
} finally {
unlockRoot();
}
}
break;
}
}
assert checkInvariants(root);
return null;
}
// 基本是同jdk1.8的HashMap.TreeNode.removeTreeNode,仍然是从链表以及红黑树上都删除节点
// 两点区别:1、返回值,红黑树的规模太小时,返回true,调用者再去进行树->链表的转化;2、红黑树规模足够,不用变换成链表时,进行红黑树上的删除要加 写锁
final boolean removeTreeNode(TreeNode p) {
TreeNode next = (TreeNode)p.next;
TreeNode pred = p.prev; // unlink traversal pointers
TreeNode r, rl;
if (pred == null)
first = next;
else
pred.next = next;
if (next != null)
next.prev = pred;
if (first == null) {
root = null;
return true;
}
if ((r = root) == null || r.right == null || (rl = r.left) == null || rl.left == null) // too small
return true;
lockRoot();
try {
TreeNode replacement;
TreeNode pl = p.left;
TreeNode pr = p.right;
if (pl != null && pr != null) {
TreeNode s = pr, sl;
while ((sl = s.left) != null) // find successor
s = sl;
boolean c = s.red; s.red = p.red; p.red = c; // swap colors
TreeNode sr = s.right;
TreeNode pp = p.parent;
if (s == pr) { // p was s's direct parent
p.parent = s;
s.right = p;
}
else {
TreeNode sp = s.parent;
if ((p.parent = sp) != null) {
if (s == sp.left)
sp.left = p;
else
sp.right = p;
}
if ((s.right = pr) != null)
pr.parent = s;
}
p.left = null;
if ((p.right = sr) != null)
sr.parent = p;
if ((s.left = pl) != null)
pl.parent = s;
if ((s.parent = pp) == null)
r = s;
else if (p == pp.left)
pp.left = s;
else
pp.right = s;
if (sr != null)
replacement = sr;
else
replacement = p;
}
else if (pl != null)
replacement = pl;
else if (pr != null)
replacement = pr;
else
replacement = p;
if (replacement != p) {
TreeNode pp = replacement.parent = p.parent;
if (pp == null)
r = replacement;
else if (p == pp.left)
pp.left = replacement;
else
pp.right = replacement;
p.left = p.right = p.parent = null;
}
root = (p.red) ? r : balanceDeletion(r, replacement);
if (p == replacement) { // detach pointers
TreeNode pp;
if ((pp = p.parent) != null) {
if (p == pp.left)
pp.left = null;
else if (p == pp.right)
pp.right = null;
p.parent = null;
}
}
} finally {
unlockRoot();
}
assert checkInvariants(root);
return false;
}
// 下面四个是经典的红黑树方法,改编自《算法导论》
static TreeNode rotateLeft(TreeNode root, TreeNode p);
static TreeNode rotateRight(TreeNode root, TreeNode p);
static TreeNode balanceInsertion(TreeNode root, TreeNode x);
static TreeNode balanceDeletion(TreeNode root, TreeNode x);
// 递归检查一些关系,确保构造的是正确无误的红黑树
static boolean checkInvariants(TreeNode t);
// Unsafe相关的初始化工作
private static final sun.misc.Unsafe U;
private static final long LOCKSTATE;
static {
try {
U = sun.misc.Unsafe.getUnsafe();
Class k = TreeBin.class;
LOCKSTATE = U.objectFieldOffset(k.getDeclaredField("lockState"));
} catch (Exception e) {
throw new Error(e);
}
}
}
5、ReservationNode:保留节点
或者叫空节点,computeIfAbsent和compute这两个函数式api中才会使用。它的hash值固定为-3,就是个占位符,不会保存实际的数据,正常情况是不会出现的,在jdk1.8新的函数式有关的两个方法computeIfAbsent和compute中才会出现。
为什么需要这个节点,因为正常的写操作,都会想对hash桶的第一个节点进行加锁,但是null是不能加锁,所以就要new一个占位符出来,放在这个空hash桶中成为第一个节点,把占位符当锁的对象,这样就能对整个hash桶加锁了。put/remove不使用ReservationNode是因为它们都特殊处理了下,并且这种特殊情况实际上还更简单,put直接使用cas操作,remove直接不操作,都不用加锁。但是computeIfAbsent和compute这个两个方法在碰见这种特殊情况时稍微复杂些,代码多一些,不加锁不好处理,所以需要ReservationNode来帮助完成对hash桶的加锁操作。
static final class ReservationNode extends Node {
ReservationNode() {
super(RESERVED, null, null, null);
}
// 空节点代表这个hash桶当前为null,所以肯定找不到“相等”的节点
Node find(int h, Object k) {
return null;
}
}
四、构造方法与初始化
下面是构造方法,不执行真正的初始化。
// 真的是什么也不做
public ConcurrentHashMap() {
}
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1)); // 求 2^n
this.sizeCtl = cap; // 用这个重要的变量保存hash桶的接下来的初始化使用的容量
}
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, 1);
}
// concurrencyLevel只是为了此方法能够兼容之前的版本,它并不是实际的并发级别,loadFactor也不是实际的加载因子了
// 这两个都失去了原有的意义,仅仅对初始容量有一定的控制作用
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0) // 检查参数
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel)
initialCapacity = concurrencyLevel;
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size); // tableSizeFor,求不小于size的 2^n的算法,jdk1.8的HashMap中说过
this.sizeCtl = cap; // 用这个重要的变量保存hash桶的接下来的初始化使用的容量
// 不进行任何数组(hash桶)的初始化工作,构造方法进行懒初始化lazyInitialization
}
public ConcurrentHashMap(Map m) {
this.sizeCtl = DEFAULT_CAPACITY;
putAll(m);
}// 真正的初始化方法,使用保存在sizeCtl中的数据作为初始化容量
// Initializes table, using the size recorded in sizeCtl.
private final Node[] initTable() {
Node[] tab; int sc;
while ((tab = table) == null || tab.length == 0) { // Thread.yeild() 和 CAS 都不是100%和预期一致的方法,所以用循环,其他代码中也有很多这样的场景
if ((sc = sizeCtl) < 0) // 看前面sizeCtl这个重要变量的注释
Thread.yield(); // lost initialization race; just spin
// 真正的初始化是要禁止并发的,保证tables数组只被初始化一次,但是又不能切换线程,所以用yeild()暂时让出CPU
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) { // CAS更新sizeCtl标识为 "初始化" 状态
try {
if ((tab = table) == null || tab.length == 0) { // 检查table数组是否已经被初始化,没初始化就真正初始化
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node[] nt = (Node[])new Node[n];
table = tab = nt;
sc = n - (n >>> 2); // sc = threshold,n - (n >>> 2) = n - n/4 = 0.75n,前面说了loadFactor没用了,这里看出,统一用0.75f了
}
} finally {
sizeCtl = sc; // 设置threshold
}
break;
}
}
return tab;
}
五、一些基本的方法
下面这些方法逻辑都比较简单,是最基础的方法,很多地方都要用的下面这些方法,基本还是和1.8的HashMap,以及1.7的ConcurrentHashMap中的那些对应的基本方法差不多。
// hash扰动函数,跟1.8的HashMap的基本一样,& HASH_BITS用于把hash值转化为正数,负数hash是有特别的作用的
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
// 用于求2^n,用来作为table数组的容量,同1.8的HashMap
private static final int tableSizeFor(int c) {
int n = c - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
// 1.8的HashMap中讲解红黑树相关的时候说过,用于获取Comparable接口中的泛型类
static Class comparableClassFor(Object x) {
if (x instanceof Comparable) {
Class c; Type[] ts, as; Type t; ParameterizedType p;
if ((c = x.getClass()) == String.class) // bypass checks
return c;
if ((ts = c.getGenericInterfaces()) != null) {
for (int i = 0; i < ts.length; ++i) {
if (((t = ts[i]) instanceof ParameterizedType) &&
((p = (ParameterizedType)t).getRawType() == Comparable.class) &&
(as = p.getActualTypeArguments()) != null &&
as.length == 1 && as[0] == c) // type arg is c
return c;
}
}
}
return null;
}
// 同1.8的HashMap,当类型相同且实现Comparable时,调用compareTo比较大小
@SuppressWarnings({"rawtypes","unchecked"}) // for cast to Comparable
static int compareComparables(Class kc, Object k, Object x) {
return (x == null || x.getClass() != kc ? 0 : ((Comparable)k).compareTo(x));
}
// 下面几个用于读写table数组,使用Unsafe提供的更强的功能(数组元素的volatile读写,CAS 更新)代替普通的读写,调用者预先进行参数控制
// 方法功能,以及Unsafe的用法都基本同1.7
// volatile读取table[i]
@SuppressWarnings("unchecked")
static final Node tabAt(Node[] tab, int i) {
return (Node)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
// CAS更新table[i],也就是Node链表的头节点,或者TreeBin节点(它持有红黑树的根节点)
static final boolean casTabAt(Node[] tab, int i, Node c, Node v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
// volatile写入table[i]
static final void setTabAt(Node[] tab, int i, Node v) {
U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v);
}
// 满足变换为红黑树的两个条件时(链表长度这个条件调用者保证,这里只验证Map容量这个条件),将链表变为红黑树,否则只是进行一次扩容操作
private final void treeifyBin(Node[] tab, int index) {
Node b; int n, sc;
if (tab != null) {
if ((n = tab.length) < MIN_TREEIFY_CAPACITY) // Map的容量不够时,只是进行一次扩容
tryPresize(n << 1);
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
synchronized (b) {
if (tabAt(tab, index) == b) {
TreeNode hd = null, tl = null;
for (Node e = b; e != null; e = e.next) {
TreeNode p = new TreeNode(e.hash, e.key, e.val, null, null);
if ((p.prev = tl) == null)
hd = p;
else
tl.next = p;
tl = p;
}
setTabAt(tab, index, new TreeBin(hd));
}
}
}
}
}
// 规模不足时把红黑树转化为链表,此方法由调用者进行synchronized加锁,所以这里不加锁
static Node untreeify(Node b) {
Node hd = null, tl = null;
for (Node q = b; q != null; q = q.next) {
Node p = new Node(q.hash, q.key, q.val, null);
if (tl == null)
hd = p;
else
tl.next = p;
tl = p;
}
return hd;
}
六、计数操作
1.7及以前的ConcurrentHashMap中使用了Segment,Segment能够分担所有的针对单个K-V的写操作,包括put/replace。并且Segment自带一些数据,比如Segment.count,用于处理Map的计数要求,这样就可以像put/repalce一样,分担整个Map的并发计数压力。
但是1.8中没有再使用Segment来完成put/replace,虽然还是利用了锁分段的思想,但是使用的是自带的synchronized锁住hash桶中的第一个节点,没有新增别的数据。因此计数操作,被落下来了,它无法享受synchronized实现的变种分段锁带来的高效率,单独使用一个Map.size来计数,线程竞争可能会很大,比使用Segment是效率低很多。
为了处理这个问题,jdk1.8中使用了一个仿造LongAdder实现的计数器,让计数操作额外使用别的基于分段并发思想的实现的类。具体是什么原理,可以看下 这一篇我专门写的关于LongAdder的源码分析。ConcurrentHashMap中不直接使用LongAdder,而是自己拷贝代码实现一个内部的,主要为了方便。LongAdder的实现本身代码不是特别多,ConcurrentHashMap中的实现,基本和LongAdder一样,可以直接看做是LongAdder。
扩容这部分是改动最大的,目前也不能说全部搞清楚,有些地方还对不上,所以各位还是细看,自己也要分析下。
七、扩容
1.8的扩容可以多线程一起完成,因此扩容变得复杂了,但是效率提升了。这部分的内容比较多,分几点说下。
1、一个transfer任务
对于一个大任务拆分成多个小任务供多线程执行,一般都要求这些小任务具有相似性,流程一致,并且很重要的一点,任务之间的相互影响尽量少。那么在扩容之中,是怎么划分这个任务的呢?
一般我们说的扩容,都包含两个步骤。第一,新建一个2倍大小的数组,这个过程要求单线程完成(多线程创建几个数组没有意义,容易出错),这个步骤每个HashMap、ConcurrentHashMap基本是都是同一套,前面我说过很多了,到这里没什么好说的了。第二步,执行节点迁移,说白了就是rehash,相当于把旧数组中所有的节点重新“put”到新数组中。在1.8的HashMap中,用了一个技巧,避免了重新根据hash值定位(可以看我写的这篇)。根据这个,我们可以知道,进行 n -> 2n 的扩容时,扩容前节点所在的hash桶的索引为index,这个节点迁移到新数组中只会有两种情况:要么在还是在新数组的索引为index处,要么迁移到新数组的索引为 index + n 的地方。所以旧的table数组上各个hash桶中的节点的迁移是不会互相影响的,这一点对多线程扩容非常有利。根据这一点,可以知道,每个hash桶的迁移都可以作为一个线程在扩容时的一个transfer任务。
另外,每个线程要任务都不应该规模太小,因为扩容并不是IO型操作,节点迁移的执行速度本身很快,太多的线程来执行节点迁移,线程调度开销占比变大,反而降低了吞吐量。ConcurrentHashMap这里,会根据CPU的核心数目,来算出一个transfer任务包含的hash桶的数量。
// 下面的代码用于计算每个transfer中要迁移多少个hash桶,一个transfer任务完成后,可以再次申请
int n = tab.length, stride;
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
2、transfer任务的申请
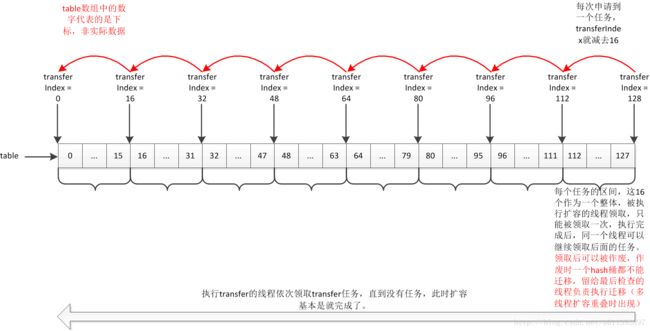
这个就是讲解transferIndex这个属性的作用。
在经典的生成者消费者模式中,会有一个任务队列。消费者向任务队列申请任务,申请到任务时,队列中元素数量减1,当任务队列中元素数量为0时,不能再申请任务。ConcurrentHashMap这里并没有使用额外的任务队列,因为table数组本身就可以当作是一个队列。第一点中说了,一个transfer任务中要负责迁移stride个hash桶,最简单的设计当然是16个hash桶都是连续的。为了记录还有多少个任务,使用了一个类变量transferIndex,可以把这个看成是任务队列的size,每一次申请任务,这个size减1。
另外,迭代操作的下标是从小往大,也就是正向,为了减少扩容时的transfer和迭代的冲突,transfer使用反向,也就是下标从大到小。顺序相反时,二者相遇过后,迭代没处理的都是已经transfer的hash桶,transfer没处理的,都是已经迭代的hash桶,冲突会变少。
所以,任务队列的size减1,翻译过来就是,在table数组中的索引减stride。这个索引就是 transferIndex,用于标记整体的transfer进行到了哪里。因为transfer个数,从1开始,因此transferIndex也是从1开始,下标在[transferIndex - 实际的stride(下界要 >= 0), transferIndex - 1]内的hash桶,就是每个transfer的任务区间。transferIndex <= 0 时,代表没有任务可以申请,此时无法帮助扩容。注意,NCPU不一定是2^n,因此最后一个任务中的hash桶的数量可能不足stride个,此时只执行余下的数量。
为了保证每个任务只被领取一次,transferIndex递减是用CAS操作完成的。
特殊情况下,会出现多线程扩容重叠,此时某个transfer任务虽然被领取了,但是却不能被执行,会被作废。这是根据transfer方法的代码理解得带的,因为transfer方法的代码中有考虑任务作废的情况。但是根据下面第3点的分析,扩容重叠这种特殊情况是有一个机制来避免的。
根据本人目前对代码的理解, 简而言之就是:代码中有处理扩容作废,但是实际不会发生。
下面简单画了个示意图。
——————分隔线——————
第3点和第4点是比较难得理解的地方,虽然看了很久,但是有些地方还是不能理解。扩容重叠现象以及避免,是最难理解的地方。觉得我说的不好,或者分析得有问题的,麻烦一定要指出来,谢谢!
3、resizeStamp以及扩容重叠相关
为了好看,我把跟resizeStamp(以下简称rs)有关的代码片段都贴在一起,实际的代码就在下面的第4点中,可以对照看下。
// 用于生成每次扩容都唯一的生成戳的数,最小是6。很奇怪,这个值不是常量,但是也不提供修改方法。
/** The number of bits used for generation stamp in sizeCtl. Must be at least 6 for 32bit arrays. */
private static int RESIZE_STAMP_BITS = 16;
// 最大的扩容线程的数量,如果上面的 RESIZE_STAMP_BITS = 32,那么此值为 0,这一点也很奇怪。
/** The maximum number of threads that can help resize. Must fit in 32 - RESIZE_STAMP_BITS bits. */
private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1;
// 移位量,把生成戳移位后保存在sizeCtl中当做扩容线程计数的基数,相反方向移位后能够反解出生成戳
/** The bit shift for recording size stamp in sizeCtl. */
private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS;
// 非常重要的一个属性,源码中的英文翻译,直译过来是下面的四行文字的意思
// sizeCtl = -1,表示有线程正在进行真正的初始化操作
// sizeCtl = -(1 + nThreads),表示有nThreads个线程正在进行扩容操作
// sizeCtl > 0,表示接下来的真正的初始化操作中使用的容量,或者初始化/扩容完成后的threshold
// sizeCtl = 0,默认值,此时在真正的初始化操作中使用默认容量
// 但是,通过我对源码的理解,这段注释实际上是有问题的,
// 有问题的是第二句,sizeCtl = -(1 + nThreads)这个,网上好多都是用第二句的直接翻译去解释代码,这样理解是错误的
// 默认构造的16个大小的ConcurrentHashMap,只有一个线程执行扩容时,sizeCtl = -2145714174,
// 但是照这段英文注释的意思,sizeCtl的值应该是 -(1 + 1) = -2
// sizeCtl在小于0时的确有记录有多少个线程正在执行扩容任务的功能,但是不是这段英文注释说的那样直接用 -(1 + nThreads)
// 实际中使用了一种生成戳,根据生成戳算出一个基数,不同轮次的扩容操作的生成戳都是唯一的,来保证多次扩容之间不会交叉重叠,
// 当有n个线程正在执行扩容时,sizeCtl在值变为 (基数 + n)
// 1.8.0_111的源码的383-384行写了个说明:A generation stamp in field sizeCtl ensures that resizings do not overlap.
/**
* Table initialization and resizing control.
* When negative, the table is being initialized or resized: -1 for initialization,
* else -(1 + the number of active resizing threads).
* Otherwise, when table is null, holds the initial table size to use upon creation,
* or 0 for default.
* After initialization, holds the next element count value upon which to resize the table.
*/
private transient volatile int sizeCtl;
/**
* Returns the stamp bits for resizing a table of size n.
* Must be negative when shifted left by RESIZE_STAMP_SHIFT.
*/
// 返回与扩容有关的一个生成戳rs,每次新的扩容,都有一个不同的n,这个生成戳就是根据n来计算出来的一个数字,n不同,这个数字也不同
// 另外还得保证 rs << RESIZE_STAMP_SHIFT 必须是负数
// 这个方法的返回值,当且仅当 RESIZE_STAMP_SIZE = 32时为负数
// 但是b = 32时MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1 = 0,这一点很奇怪
static final int resizeStamp(int n) {
return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1));
}
// 这个if在addCount、helpTransfer、tryPresize中都有(可能会少一个条件,因为那个条件上文判断了),是理解这一点的重要的代码
// 实际看下代码,可以知道执行到这里时,sc(sc = sizeCtl)是一定小于0的
// 为真时会直接退出外层循环,然后退出方法
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || (nt = nextTable) == null || transferIndex <= 0)
// 这个在addCount、tryPresize中都有。实际看下代码,可以知道执行到这里时,sc 一定大于 0(等于0是初始化情况,可以不考虑)
// 为真时会进入transfer方法去执行扩容操作
else if (U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2))
// 这个在transfer方法中,条件为真时会 return 退出方法
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)先看下resizeStamp方法。
Integer.numberOfLeadingZeros(n),是返回二进制表示中,前面有多少个连续的0。这里n是2的幂,假设n = 2^x,那么有 Integer.numberOfLeadingZeros(n) = 31 - x < 32,二进制最高的27位都是0。并且它只跟n有关,n不同,这个运算的结果也不同。
1 << (RESIZE_STAMP_BITS - 1),因为RESIZE_STAMP_BITS 最小是6,因此这个运算,在不考虑变成负数的情况下,最下是 1<< 5 = 32,二进制最低的5位都是0,。
进行 | 运算后,可以知道二者的二进制不重叠,可以确定,n不同时,每个rs也不同。
接着看下这个 else if (U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2)),这个是sizeCtl有关的。如果按照sizeCtl本身的注释,这里应该是把sc更新为sc - 1才对,这一点就说明它本身的注释是不准确的。为了防止扩容重叠,这里使用扩容生成戳进行了处理,尽量避免扩容重叠。
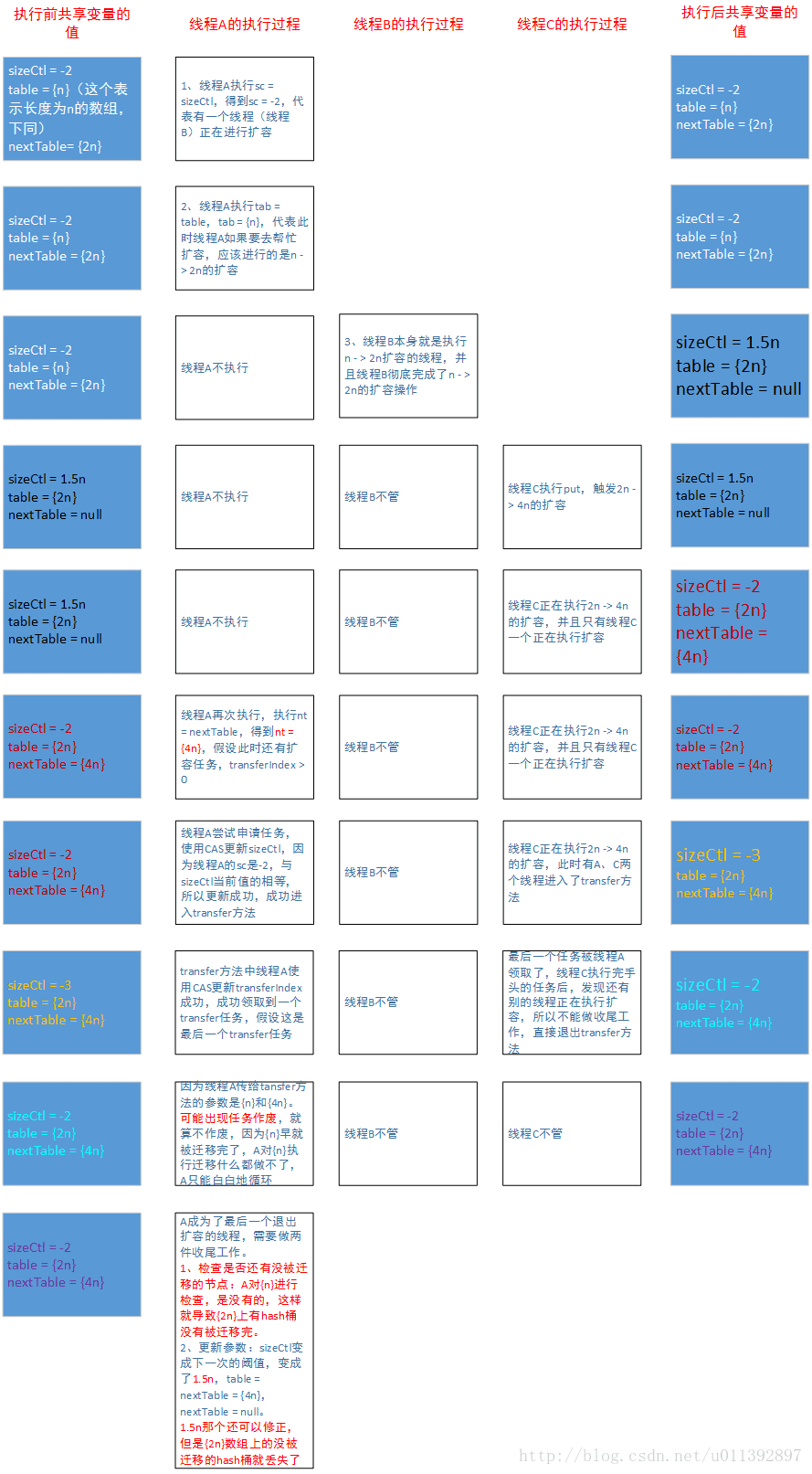
扩容重叠改如何理解?为什么上面的这种对sizeCtl进行的处理(下面叫做resizeStamp机制)能避免扩容重叠?
——————分割线——————
如果直接使用注释所说的,sizeCtl = -(1 + nThreads),表示有nThreads个线程正在进行扩容操作,其他有关rs的代码也都不要,剩余的条件不变,那么会出现什么呢?
代码变成了这样
// 来自addCount方法中触发扩容的代码
// 直接使用 -(1 + nThreads) 表示正在扩容的线程数时,去掉rs相关的代码,就变成了下面这样
while (s >= (long)(sc = sizeCtl) && (tab = table) != null && (n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((nt = nextTable) == null || transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc - 1))
transfer(tab, nt);
}
else if ...
}114 aload_0
115 invokevirtual #30
118 lstore 7
120 iload_3
121 iflt 291 (+170)
124 lload 7
126 aload_0
127 getfield #25
130 dup
131 istore 12
133 i2l
134 lcmp
135 iflt 291 (+156)
138 aload_0
139 getfield #35
142 dup
143 astore 9
145 ifnull 291 (+146)
148 aload 9
150 arraylength
151 dup
152 istore 11
154 ldc #4 <1073741824>
156 if_icmpge 291 (+135)
159 iload 11
161 invokestatic #142
164 istore 13
166 iload 12
168 ifge 252 (+84)
171 iload 12
173 getstatic #143
176 iushr
177 iload 13
179 if_icmpne 291 (+112)
182 iload 12
184 iload 13
186 iconst_1
187 iadd
188 if_icmpeq 291 (+103)
191 iload 12
193 iload 13
195 getstatic #144
198 iadd
199 if_icmpeq 291 (+92)
202 aload_0
203 getfield #145
206 dup
207 astore 10
209 ifnull 291 (+82)
212 aload_0
213 getfield #146
216 ifgt 222 (+6)
219 goto 291 (+72)
222 getstatic #13
假设有一个线程正在执行n -> 2n 的扩容,那么sizeCtl = -2,此时一个线程,叫做线程A,来尝试帮助执行扩容(对照源码看,addCount方法的while循环,里面会先后读取sizeCtl、table、nextTable来给局部变量赋值,这中间可能会插入其他操作,导致局部变量的值是旧值)。
A先执行sc= sizeCtl,此时得到sc = -2,这样判断sc < 0会为真。再执行 tab = table,此时 n -> 2n 的扩容还没完成,tab赋值为长度为n的数组。然后线程A一段时间不执行了,等它再次执行下一句,也就是赋值操作 nt = nextTable 时,n -> 2n的扩容早就已经完成了,并且现在又有一个的线程正在执行 2n -> 4n的扩容,此时sizeCtl仍然是-2,但是nt被赋值为长度为4n的数组。如果还有可以申请transfer任务,最后线程A就会进入transfer方法,此时它的tab长度为n,nt长度为4n。
如果transfer方法中碰到了这种情况(两个数组长度不满足2倍关系),它可能会让线程A申请到的任务直接作废,就算不是直接作废,因为线程A的tab中所有hash桶都已经被迁移完成了,这个任务实际也算是作废了。作废的任务会让最后一个退出扩容的线程来检查出来并处理掉,这是一个预防机制。
但是还有很重要的一点,按照上面的假设保证不了,那就是线程A一定不能成为最后一个退出扩容的线程,有两个原因:
1、A的tab的长度是n,实际扩容完成后,使用n重设下一次扩容阈值sizeCtl时,会让sizeCtl变成一个错误的值(正确值的一半,这个影响不太大,下次扩容就恢复了);
2、A作为最后一个线程,它需要重新检查一次所有hash桶,这个是针对长度为n的tab来进行的。实际上tab中所有hash桶都被迁移完成了,检测tab没有意义。真正需要检查是的当下的table数组,它的长度为2n,因为线程A申请到的扩容任务作废了,当前的table数组中有一部分hash桶没有迁移,此时线程A最后检查一遍时,发现不了这个问题,也处理不了,导致扩容完成时有部分hash桶没有被迁移,发生了扩容错误。
所以必须不能让这个扩容重叠、参数错误的线程,成为最后一个退出扩容的线程。
在使用 -(1 + nThreads) 表示有nThreads个线程正在进行扩容操作时,会出现上面描述的扩容重叠,导致发生错误,很大程度上还是因为CAS操作,因为CAS操作无法处理ABA问题。直接使用-(1 + nThreads)表示正在执行扩容的线程数时,sizeCtl会经常是一些常见的数,不同的扩容中很容易出现相同的,这样会频繁发生ABA问题。
因此不能直接像sizeCtl注释所说的,直接使用 -(1 + nThreads) 来表示正在执行扩容的线程数目。为了避免ABA问题导致的扩容重叠,应该让sizeCtl跟table数组的长度n绑定,并且sizeCtl能够反解出它对应的n,这样就能够保证这一轮的扩容跟另外一轮扩容,它们的执行过程中不可能出现相同的sizeCtl。
简单画了个图,可以看下。
——————分隔线——————
前面说了,rs是跟n绑定的,不同的n有不同的rs,并且rs能够反解出唯一的n,这里不能直接使用rs,因为 sizeCtl 大于0时表示的是扩容阈值,因此需要把rs处理成负数,并且还要保证不同扩容之间不会出现相同的sizeCtl。这两个是依靠移位操作 rs << RESIZE_STAMP_SHIFT 来完成的。
下面是一段不严格的数学证明,证明rs的有效性,能够避免 sizeCtl 出现 ABA 问题可能导致的扩容错误,这段证明只是为了解释源码中一些代码的有效性,不讨论为什么不用别的设计。
(以下情况中都不考虑 b = 32的情况,b实际可以认为是常量)
假设正在执行扩容的线程数量为nThreads,令b = RESIZE_STAMP_BITS,table.length = 1 << x,其中6 <= b <=32,1 <= x <= 30 ,那么有:
RESIZE_STAMP_SHIFT = 32 - b,rs = (31 - x) | (1 << (b - 1)),
sizeCtl = sc = (rs << (32 - b)) + 1 + nThreads(后面都用sc,看下面的addCount的代码,sc > 0时,尝试成为第一个扩容的线程的代码,+2表示有一个,+1表示有0个),
MAX_RESIZERS = (1 << (32 - b)) - 1 >= nThreads;
b >= 6,那么(1 << (b-1)) >= 32,并且它的二进制中只有一位是1,(32 - b) + (b - 1) = 31 < 32,这样 rs = (31 - x) | (1 << (b - 1)) 中的 或运算 可以转化为加法(因为不会进位),rs的移位运算可以转化为两部分移位的和 ,所以移位运算
(rs << (32 - b)) = ((31 - x) << (32 - b)) + (1 << 31);
又因为31 - x < 32 = (1 << 5),32 - b <= 26,所以((31 - x) << (32 - b)) < (1 << 31),(1 << 31) = Integer.MIN_VALUE, 所以(rs << (32 - b))是负数,满足resizeStamp的设计;
好了,那么sc = (rs << (32 - b)) + 1 + nThreads = ((31 - x) << (32 - b)) + (1 << 31) + 1 + nThreads,
因为32 - x < (1 << 5),32 - b <=26,所以 ((32 - x) << (32 - b)) 是正数,并且绝对值小于 (1 << 31), sc 不可能出现负数溢出变正数的情况,此时sc < 0;
nThreads取最小值0时,很明显也不可出现负数溢出,因此sc < 0;
小结下,扩容完成前,使用rs时,sc总是负数,保证了基本的有效性;
sc反解出rs,通过反向移位就行
sc >>> RESIZE_STAMP_SHIFT = sc >>> (32 - b),这种右移位是把操作数当做无符号数进行普通的右移位,负数移位会变成正数,本身就有sc < 0,
在加法不产生进位时,把和的移位当做移位的和,那么有:
nThreads = 0时,(sc >>> (32 - b)) = (rs << (32 - b)) + 1) >> (32 - b) = rs,正常情况(不发生扩容重叠)一定有 (sc >>> RESIZE_STAMP_SHIFT) >= rs;
nThreads = MAX_RESIZERS时,(sc >>> (32 - b)) = (((31 - x) << (32 - b)) + (1 << 31) + 1 + (1 << (32 - b)) - 1) >>> (32 - b) = rs + 1,因此正常情况(不发生扩容重叠)下一定有(sc >>> RESIZE_STAMP_SHIFT) <= rs + 1,当且仅当扩容线程为最大数时取等号;
再分析下 sc 的在每轮不同的扩容中的唯一性(这里没证明单调性)
sc 的值域为 [ ((31 - x) << (32 - b)) + (1 << 31) + 1, ((31 - x) << (32 - b)) + (1 << 31) + (1 << (32 - b)) ];
另 x = x + 1,也就是进行下一轮扩容,那么 sc 的值域变为 [ ((30 - x) << (32 - b)) + (1 << 31) + 1, ((30 - x) << (32 - b)) + (1 << 31) + (1 << (32 - b)) ];
加法不进位时把移位的和当作和的移位,上界进行移位合并,那么x + 1时的值域为 [ ((30 - x) << (32 - b)) + (1 << 31) + 1, ((31 - x) << (32 - b)) + (1 << 31)) ];
很明显,x+1时上界,比x时的下界小1,所以两个值域中sc不可能相等;
这也就是说,n -> 2n扩容中的sc的任何可能取值,总是大于 2n -> 4n时sc的任何可能取值,
因此sizeCtl具有扩容唯一性,每轮扩容的sizeCtl,都不可能和别的轮次的扩容的sizeCtl相同
那么 sc >>> RESIZE_STAMP_SHIFT 呢,这个就有点特殊了
x时,移位后的值域为 [ (31 - x) + (1 << (b - 1)), (32 - x) + (1 << (b - 1))];
x+1时,移位后的值域为 [ (30 - x) + (1 << (b - 1)), (31 - x) + (1 << (b - 1))];
两者有一个重叠点。
这时可能会绕过(sc >>> RESIZE_STAMP_SHIFT) != rs这个条件的检验,但是此时sc是不一样的,后面CAS更新时,依然不能使用旧的sc的值。
综合上面所说的,resizeStamp这个机制,能够避免sc = sizeCtl在不同轮次的扩容中出现ABA问题,进而避免 扩容重叠 问题出现。
特别的一点,b = 32这种极端情况下,resizeStamp机制会受到影响,并且MAX_RESIZERS = 0。那么这个b = 32应该是不会发生的,但是5个条件的if中又有处理b = 32的情况,又是一处代码跟实际不太对的上的情况。
下面再谈谈那5个条件的if,也就是这句 if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || (nt = nextTable) == null || transferIndex <= 0)
从简单的开始分析:
A、(nt = nextTable) == null:表示整个扩容过程已经结束,或者扩容过程处于一个单线程的阶段(transfer方法中创建nextTable是由单线程完成的),此时不能帮助扩容。
B、transferIndex <= 0:表示所有的transfer任务都被领取光了,没有剩余的hash桶给自己这个线程来transfer,此时线程不能再帮助扩容了。
C、(sc >>> RESIZE_STAMP_SHIFT) != rs:上面的那个证明中,有两个结论,
“正常情况(不发生扩容重叠)下一定有(sc >>> RESIZE_STAMP_SHIFT) <= rs + 1,当且仅当扩容线程为最大数时取等号”,
“正常情况(不发生扩容重叠)下一定有 (sc >>> RESIZE_STAMP_SHIFT) >= rs ”
rs + 1时是个特殊情况,此时扩容线程为最大值,是一定不能帮助扩容的。其他情况下等价于“正常情况(不发生扩容重叠)下一定有(sc >>> RESIZE_STAMP_SHIFT) == rs ”
所以它可以看成是一个个恒等式,正常情况下if中的这个判断条件一定为false。为true则表明sc 和 tab.length 对不上,不能互相反解,继续下去有可能发生扩容重叠。因此为true时也不能帮助扩容,这个条件放在第一位置也是有道理的,它最先避免了扩容重叠的发生。
D、sc == rs + 1:这一个条件很奇怪,根据上下文,sc在这里一定是负数,rs只有当RESIZE_STAMP_BITS = 32时才是负数,此时MAX_RESIZERS = 0。
RESIZE_STAMP_BITS是static变量,但不是常量,也不提供任何更改它的途径。当取最大值32时,RESIZE_STAMP_SHIFT = 0,那么rs << RESIZE_STAMP_SHIFT = rs,这样这个条件就好理解了。
第一次分配transfer任务时,把正在扩容线程数加1的操作是U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2), +2代表有1个,+1代表有0个。再根据上下文,可以认为是此时此刻transfer任务都被执行完成了,本轮扩容操作实际上已经结束了。
E、有和D一样的疑问,那就是,sc在这里一定是负数,rs只有当RESIZE_STAMP_BITS = 32时才是负数,rs + MAX_RESIZERS也只有当RESIZE_STAMP_BITS = 32时才是负数,此时MAX_RESIZERS = 0。
而且逻辑上感觉用 sc == rs + MAX_RESIZERS + 1 才是对的啊。
所以,目前ABC都有了合理解释,DE在目前的情况下,不能给出太合理的解释,只能认为它们两个是为了处理极端的 RESIZE_STAMP_BITS = 32的情况。在实际情况中,没有提供途径去修改 RESIZE_STAMP_BITS 的值,这样D和E一定是false。在这个层面上,可以认为它们两个没啥用。
——————分隔线——————
根据上面的分析,使用resizeStamp这个机制,可以检查sc是否和tab.length匹配,并且可以避免sizeCtl 的ABA问题,进而可以避免 扩容重叠 的发生。
现在还有一个疑问,既然使用这个机制能避免 扩容重叠 的发生,那么transfer方法(第4点中讲)中为什么还要自己处理下一部分扩容重叠的情况?
这一点我暂时还没看明白。可能只是为了保险,可能transfer方法最后那个检查本身就不针对扩容重叠只是单纯的检查,也可能是我第3点第4点的分析漏了什么。
反正就是扩容这块有几个重要的地方,不太对得上,根据代码直接理解,和根据分析理解处理的,有些出入。要么就是代码中有无用的逻辑(sizeCtl的注释错了,所以源码也不是尽善尽美的),要么就是我分析错了什么
——————分隔线——————
4、扩容代码
这部分有了前面3点的基础,代码就基本上看得懂了,要说的都写在注释中了。
// 更改计数值,这部分相关是仿造LongAdder实现的,已经说过了
// 检查是否触发了扩容,是否正在扩容,是否可以帮助扩容
// 并且还要检查是否会触发下一次扩容,因为更改计数值的操作是不在加锁区域内的,扩容过程中可能还有别的线程添加了很多K-V
// 参数check,用于指示计数操作是否会触发扩容,check < 0 代表一定不会触发,
// check <= 1时,只在没有计数时线程竞争才会触发扩容,check > 0 时,也表示的是hash桶中节点的数目
// 普通的put可能会触发,Map拷贝构造中的putAll,因为事先扩容了,所以这个putAll不会触发扩容
private final void addCount(long x, int check) {
// 先按照LongAdder实现,把计数器的值变更,已经说过了
CounterCell[] as; long b, s;
if ((as = counterCells) != null || !U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended = U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1) // 执行到这里,说明线程更新计数值时没有遇到线程竞争(cells != null已经被初始化),
// check == 1时表示hash桶中原本只有一个节点,规模比较小,这次添加先不扩容
return; // 暂时觉得是这样,因为put和1.7的HashMap一样,走实用路线了,添加的是hash桶第一个节点时,
// 一定不扩容(后面将put时说)。当然这个解释感觉还是比较牵强。
// 如果觉得这一点有疑问,麻烦大神指出来,谢谢了!
s = sumCount();
}
if (check >= 0) { // 检测是否扩容
Node[] tab, nt; int n, sc;
// 这里在第3点中详细说了,三个连续的赋值中间可能会插入其他线程的代码,改变了某些值,造成三个局部变量最后不匹配,出现扩容重叠
// 使用resizeStamp机制避免了这种扩容重叠
while (s >= (long)(sc = sizeCtl) && (tab = table) != null && (n = tab.length) < MAXIMUM_CAPACITY) { // 扩容的基础条件
int rs = resizeStamp(n); // 计算本次扩容生成戳
if (sc < 0) { // sc < 0 表明此时有别的线程正在进行扩容
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0) // 根据前面第3点分析的,这5个条件中主要有一个为true,就说明当前线程不能帮助此次扩容
break; // 不能帮助,直接结束
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) // 不满足前面5个条件时,尝试参与此次扩容,把正在执行transfer任务的线程数加1
transfer(tab, nt); // 去帮助执行transfer任务
}
// 试着让自己成为第一个执行transfer任务的线程,这个位运算前面分析了
else if (U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null); // 去执行transfer任务
s = sumCount(); // 重新计数,判断是否需要开启下一轮扩容
// 上面两个进入transfer方法的地方,都是把sizeCtl自增,这一点足够说明sizeCtl的英文注释表达的意思有误
// 如果是 -(1 + nThreads) 表示,那么应该用减1,实际情况用的是加1
// 代码中的加2,是因为逻辑中是用(rs << RESIZE_STAMP_SHIFT) + 1代表现在有0个线程
// 下面的transfer方法中退出方法前的操作,也足够说明“sizeCtl注释错误”这一点
}
}
}
/**Helps transfer if a resize is in progress. */
// 如果正在进行扩容,则尝试去帮助执行transfer任务,此方法都是在循环中被调用,因此本身不用处理接连两次扩容的情况,这种情况在外部调用中处理
final Node[] helpTransfer(Node[] tab, Node f) {
Node[] nextTab; int sc;
// 判断此时是否仍然在执行扩容(这几个变量改变了,说明此次扩容结束了)
if (tab != null && (f instanceof ForwardingNode) && (nextTab = ((ForwardingNode)f).nextTable) != null) {
int rs = resizeStamp(tab.length); // 计数本次扩容的生成戳
while (nextTab == nextTable && table == tab && (sc = sizeCtl) < 0) { // 在判断一次是否正在执行扩容(这几个变量的值改变了,说明此次扩容结束了)
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || transferIndex <= 0) // 判断下是否能真正帮助此次扩容(这4个条件前面说了,少了的那一个不用前面判断了)
break; // 不能帮助,直接结束
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) { // 不满足前面4个条件时,尝试参与此次扩容,把正在执行transfer任务的线程数加1
transfer(tab, nextTab); // 去帮助执行transfer任务
break;
}
}
return nextTab; // 返回新数组
}
return table; // 返回新数组(执行这句说明一开始判断,就发现变量变化了,表明扩容已经结束了,table会被别的线程赋值为新数组)
}
/** Tries to presize table to accommodate the given number of elements. */
// 预先扩容,就是一个包含了初始化逻辑的扩容
// 用于putAll,此时是需要考虑初始化;链表转化为红黑树中,不满足table容量条件时,进行一次扩容,此时就是普通的扩容
private final void tryPresize(int size) {
int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :
tableSizeFor(size + (size >>> 1) + 1);
int sc;
while ((sc = sizeCtl) >= 0) {
Node[] tab = table; int n;
if (tab == null || (n = tab.length) == 0) { // 这个if用于处理初始化,跟initTable方法基本一样
n = (sc > c) ? sc : c;
if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if (table == tab) {
@SuppressWarnings("unchecked")
Node[] nt = (Node[])new Node[n];
table = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
}
}
else if (c <= sc || n >= MAXIMUM_CAPACITY) // c <= sc,说明已经被扩容过了;n >= MAXIMUM_CAPACITY说明table数组已经到了最大长度
break;
else if (tab == table) { // 可以扩容
int rs = resizeStamp(n); // 计算本次扩容的生成戳
if (sc < 0) { // sc < 0 表明此时有别的线程正在进行扩容
Node[] nt;
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0) // 这5个条件前面说了,用于判断是否能真正去帮助执行transfer任务
break; // 不能帮助,直接结束
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) // 尝试参与此次扩容,把正在执行transfer任务的线程数加1
transfer(tab, nt); // 去帮助执行transfer任务
}
// 试着让自己成为第一个执行transfer任务的线程,这个位运算前面分析了
else if (U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null); // 去执行transfer任务
}
}
}
// 执行节点迁移,准确地说是迁移内容,因为很多节点都需要进行复制,复制能够保证读操作尽量不受影响
private final void transfer(Node[] tab, Node[] nextTab) {
int n = tab.length, stride;
// 计算每个transfer任务中要负责迁移多少个hash桶
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
if (nextTab == null) { // initiating 创建新数组
try {
@SuppressWarnings("unchecked")
Node[] nt = (Node[])new Node[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME 处理内存不足导致的OOM,以及table数组超过最大长度,这两种情况都实际上无法再进行扩容了
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
transferIndex = n; // 表明此时执行扩容的线程可以开始申请transfer任务了
}
int nextn = nextTab.length;
// 转发节点,在旧数组的一个hash桶中所有节点都被迁移完后,放置在这个hash桶中,表明已经迁移完,对它的读操作会转发到新数组
ForwardingNode fwd = new ForwardingNode(nextTab);
boolean advance = true;
// 扩容中收尾的线程把做个值设置为true,进行本轮扩容的收尾工作(两件事,重新检查一次所有hash桶,给属性赋新值)
boolean finishing = false; // to ensure sweep before committing nextTab
for (int i = 0, bound = 0;;) {
Node f; int fh;
// while中的代码可以看成是预处理
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing) // 一次transfer任务还没有执行完毕
advance = false;
else if ((nextIndex = transferIndex) <= 0) { // transfer任务已经没有了,表明可以准备退出扩容了
i = -1;
advance = false;
}
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ? nextIndex - stride : 0))) { // 尝试申请一个transfer任务
// 申请到任务后标记自己的任务区间
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
// 这个分支中有处理 扩容重叠,但是前面第3点分析了,到这里应该是不会出现扩容重叠的
if (i < 0 || i >= n || i + n >= nextn) {
// i < 0 表明本次的transfer任务已经执行完毕了,此时需要准备退出这个方法,这个好理解
// i >= n 表明扩容轮次跟预想的不一样(比如这个线程预想的是进行n -> 2n的扩容,实际nextTab是4n数组),此时不能进行节点迁移(第3点分析了一部分)
// 虽然申请到了任务,但是也不能执行,应该准备退出方法,此次任务作废,别的线程也不能领取了,只能让此轮扩容中最后一个线程在重新检查时处理掉
// i + n >= nextn,这个我不知道怎么理解,此时前面两个条件为false,那么就有 0 < i < n,也就是 n < i + n < 2n,这个是一定成立的
// 因为nextn最小也是2n,i + n 怎么也比2n小,所以我觉得奇怪,不知道这个条件判断的是什么情况
int sc;
if (finishing) {
// 执行本轮扩容的收尾工作
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) { // 尝试把正在执行扩容的线程数减1,表明自己要退出扩容
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT) // 判断下自己是不是本轮扩容中的最后一个线程,如果不是,则直接退出。
return;
// 如果自己是本轮扩容中的最后一个线程,那么要准备执行收尾工作了
finishing = advance = true;
i = n; // recheck before commit 最后一个扩容的线程要重新检查一次旧数组的所有hash桶,看是否是都被正确迁移到新数组了。
// 正常情况下,重新检查时,旧数组所有hash桶都应该是转发节点,此时这个重新检查的工作很快就会执行完。
// 特殊情况,比如扩容重叠,那么会有线程申请到了transfer任务,但是参数错误(旧数组和新数组对不上,不是2倍长度的关系),
// 此时这个线程领取的任务会作废,那么最后检查时,还要处理因为作废二没有被迁移的hash桶,把它们正确迁移到新数组中
}
}
else if ((f = tabAt(tab, i)) == null) // hash桶本身为null,不用迁移,直接尝试安放一个转发节点
advance = casTabAt(tab, i, null, fwd);
else if ((fh = f.hash) == MOVED) // 正常情况下,重新检查时,总是执行这个分支。
// 出现扩容重叠,有transfer任务被作废的情况下,会执行其他分支,处理因为作废而没有被迁移的hash桶
advance = true; // already processed
else {
synchronized (f) { // 给f加锁
if (tabAt(tab, i) == f) { // 判断下加锁的节点仍然是hash桶中的第一个节点,加锁的是第一个节点才算加锁成功
Node ln, hn;
if (fh >= 0) {
// 下面这段代码,使用高低位,跟1.6/1.7的使用 & 的效果基本一样
int runBit = fh & n;
Node lastRun = f;
// 尽量重用Node链表尾部的一部分(起码能重用一个,实际情况下能重用比较多的节点,这时候就提高了效率)
for (Node p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) { // 重用的是“低位”
ln = lastRun;
hn = null;
}
else { // 重用的是“高位”
hn = lastRun;
ln = null;
}
for (Node p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node(ph, pk, pv, ln);
else
hn = new Node(ph, pk, pv, hn);
}
setTabAt(nextTab, i, ln); // 放在新table的hash桶中
setTabAt(nextTab, i + n, hn); // 放在新table的hash桶中
setTabAt(tab, i, fwd); // 把旧table的hash桶中放置转发节点,表明此hash桶已经被处理
advance = true;
}
else if (f instanceof TreeBin) {
// 红黑树的情况,先使用链表的方式遍历,复制所有节点,根据高低位(1.8的HashMap中的做法),
// 组装成两个链表,然后看下是否需要进行红黑树变换,最后放在新数组对应的hash桶中
TreeBin t = (TreeBin)f;
TreeNode lo = null, loTail = null;
TreeNode hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode p = new TreeNode
(h, e.key, e.val, null, null);
if ((h & n) == 0) { // 低位
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else { // 高位
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
}
}
}
}
}
九、只读遍历器Traverser
之前版本的ConcurrentHashMap,都有使用Segment带代理分担各种操作,对它进行写操作会首先加锁,Segment扩容都是在写操作中触发的,因此扩容时一定加了锁。它们的Segment的扩容也是单线程的,进行节点复制并迁移,不会更改当前的数组的任何地方(重用的节点不用复制,但是也不会产生更改) 。也就是在扩容期间,Segment是不会有任何更改的,中间无论对这个Segment发生多少次读操作,都不受正在进行的扩容的影响,都会看到一致的结果(因为没有全局锁,Map的遍历还是不具有一致性,期间可能会看到写操作的更改)。
1.8版本的扩容,采用了多线程扩容,并且很重要的一点,那就是扩容会对当前的table数组进行更改,扩容时会在transfer完一个hash桶中的所有节点后,把一个转发节点安放进去。这会影响正在进行的读操作。普通的读操作只读去一个hash桶中的内容,containsValue这种就会遍历读取所有hahs桶,此时就不能使用之前版本的那种什么都不考虑的遍历读,因为此时读会跨越两个数组进行。
因此写了这个内部类,它考虑了遍历读与扩容并发的情况,专门处理1.8版本中的遍历读。
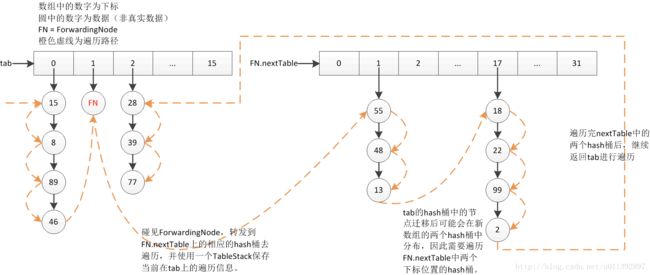
处理的逻辑很简单,就是碰到ForwardingNode时,保存当前正在遍历的数组以及索引信息,然后在FN.nextTable上进行遍历。如果继续碰到FN,就再保存一份信息,跳转到下下个数组进行hash桶节点的遍历。遍历完成后,返回最近一次记录的数组进行遍历,并清除掉最近一次保存的信息。这种行为跟入栈出栈很像,因此可以使用栈结构来保存。
这就是TableStack的由来,它是一个简化的栈,使用链表表示的。入栈就是在链表当前头结点的前面插入一个节点,并把头结点指针指向当前节点;出栈就是删除当前的头结点,把头结点指针指向删除的节点后面的一个节点。
根据transfer的性质,在FN.nextTable上进行的一次遍历只用遍历两个hash桶,index 以及 index + index。在一次出栈操作执行前,需要遍历完这两个hash桶。
这里简单看下代码。
static final class TableStack {
int length;
int index;
Node[] tab;
TableStack next;
}
static class Traverser {
Node[] tab; // current table; updated if resized,当前数组,也就是扩容完成后的旧数组
Node next; // the next entry to use, 新数组,扩容完成后使用的数组
TableStack stack, spare; // to save/restore on ForwardingNodes, 用来 保存/恢复 转发节点
int index; // index of bin to use next,下一个要读取的hash桶的下标
int baseIndex; // current index of initial table,起始的下标,下界
int baseLimit; // index bound for initial table,终止的下标,上界
final int baseSize; // initial table size table,数组的长度
Traverser(Node[] tab, int size, int index, int limit) {
this.tab = tab;
this.baseSize = size;
this.baseIndex = this.index = index;
this.baseLimit = limit;
this.next = null;
}
/** Advances if possible, returning next valid node, or null if none. */
// 遍历器的指针往前移动到下一个有实际数据节点,并返回这个节点,如果到头就返回null
final Node advance() {
Node e;
if ((e = next) != null) // 如果已经进入了一个非空的hash桶,直接尝试获取它的下一个节点
e = e.next;
for (;;) {
Node[] t; int i, n; // must use locals in checks
if (e != null) // 节点非null,直接返回
return next = e;
// 一些边界判断,遍历越界了表明没有了,可以直接返回null
if (baseIndex >= baseLimit || (t = tab) == null || (n = t.length) <= (i = index) || i < 0)
return next = null;
if ((e = tabAt(t, i)) != null && e.hash < 0) { // 处理特殊节点
if (e instanceof ForwardingNode) { // 转发节点,主要处理这个
tab = ((ForwardingNode)e).nextTable; // 将遍历迁移到FN.nextTable新数组上进行
e = null;
pushState(t, i, n); // 入栈保存当前对tab数组的遍历信息
continue; // 开始新一次循环,遍历nextTable中对应的hash桶
}
else if (e instanceof TreeBin) // TreeBin时,获取红黑树所有节点的链表形式的头节点,使用链表的方式遍历,更简单
e = ((TreeBin)e).first;
else // 保留节点,没实际数据
e = null;
}
if (stack != null) // 栈不为空
recoverState(n); // 这里可以看做是出栈操作,得先遍历完FN.nextTable中的两个之后再出栈
else if ((index = i + baseSize) >= n) // 栈为空,准备遍历下一个hash桶
index = ++baseIndex; // visit upper slots if present
}
}
/** Saves traversal state upon encountering a forwarding node. */
// 入栈操作,保存当前对tab的遍历信息
private void pushState(Node[] t, int i, int n) {
TableStack s = spare; // reuse if possible
if (s != null)
spare = s.next;
else
s = new TableStack();
s.tab = t;
s.length = n;
s.index = i;
s.next = stack;
stack = s;
}
/** Possibly pops traversal state. */
// 可能会出栈,不出栈时,更改索引,准备遍历的是FN.nextTable中对应的第二个hash桶
private void recoverState(int n) {
TableStack s; int len;
while ((s = stack) != null && (index += (len = s.length)) >= n) {
n = len;
index = s.index;
tab = s.tab;
s.tab = null;
TableStack next = s.next;
s.next = spare; // save for reuse
stack = next;
spare = s;
}
if (s == null && (index += baseSize) >= n)
index = ++baseIndex;
}
} 
视图(keySet/entrySet)的迭代器,基本上都是间接继承只读遍历器Traverser,用它来完成读操作。至于remove操作,直接用map.remove,remove方法(后面讲)中有处理碰见FN的情况,因此不需要迭代器额外处理。entry.set操作,依旧是跟1.6/1.7的一样,会执行一次map.put,保证节点在此时一定存在与map中。
十、基本方法
看完上面的几点,基本方法就非常好理解了,下面一个个过下。
1、基本的读操作
// size方法就是调用sunCount进行计数器值汇总,然后处理下int溢出的问题
// 特别的,基于HashMap这类依据hash表+链地址法实现的Map,可能会存在实际size比table数组大的情况,因此也可能出现大于Integer.MAX_VALUE的情况
// 返回值是int型是历史遗留,这里只能兼容处理,返回一个错误但是“尽量有用”的值
// 准确的应该是使用mappingCount方法,但是它是1.8才新增的,旧的代码享受不到这个改正了,新代码应该中尽量使用mappingCount
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);
}
public boolean isEmpty() {
return sumCount() <= 0L; // ignore transient negative values 这里,clear方法可能导致计数值临时为负数的情况,不过不影响这个方法的使用
}
public V get(Object key) {
Node[] tab; Node e, p; int n, eh; K ek;
int h = spread(key.hashCode());
// hash桶不为empty时才有必要查找,定位hash桶还是熟悉的方式
if ((tab = table) != null && (n = tab.length) > 0 && (e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) { // 特殊判断第一个节点
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0) // hash桶的第一个节点的hash值小于0,代表它是特殊节点,使用特化的查找方式进行查找
// ForwardingNode会把find转发到nextTable上再去执行一次;
// TreeBin则根据自身读写锁情况,判断是用红黑树方式查找,还是用链表方式查找;
// ReservationNode本身只是为了synchronized有加锁对象而创建的空的占位节点,因此本身hash桶是没节点的,一定找不到,直接返回null)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) { // 是普通节点,使用链表方式查找
if (e.hash == h && ((ek = e.key) == key || (ek != null && key.equals(ek)))) // 这个条件在我写的678的HashMap中说过几次了,这里就不说了
return e.val;
}
}
return null;
}
public boolean containsKey(Object key) {
return get(key) != null;
}
// 使用Traverser进行只读遍历
// 因为此操作会遍历所有hash桶,但是不使用全局锁,因此返回的结果不是最新的
public boolean containsValue(Object value) {
if (value == null)
throw new NullPointerException();
Node[] t;
if ((t = table) != null) {
Traverser it = new Traverser(t, t.length, 0, t.length);
for (Node p; (p = it.advance()) != null; ) {
V v;
if ((v = p.val) == value || (v != null && value.equals(v)))
return true;
}
}
return false;
}
// 上面说了,size方法可能会超出int型,而返回不正确的结果,这个方法就是用来替代size的,1.8才新增的方法
public long mappingCount() {
long n = sumCount();
return (n < 0L) ? 0L : n; // ignore transient negative values
}
// 1.8新增的一个好用的方法
public V getOrDefault(Object key, V defaultValue) {
V v;
return (v = get(key)) == null ? defaultValue : v;
}
public boolean contains(Object value) {
return containsValue(value);
} public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException(); // 处理null
int hash = spread(key.hashCode()); // 计算hash值
int binCount = 0; // 只使用链表保存时,此变量可以看出是添加新节点前,这个hash桶中所有保存实际数据的节点数目;
// 红黑树保存时,固定为2,保证put后更改计数值时能够进行扩容检查,同时不触发红黑树化操作
for (Node[] tab = table;;) {
Node f; int n, i, fh;
if (tab == null || (n = tab.length) == 0) // 处理初始化,并发的情况在initTable中处理,这里不考虑
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node(hash, key, value, null))) // 使用CAS添加第一个节点
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED) // 发现转发节点,表明此时正在进行扩容,去帮助扩容
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) { // 锁住f
if (tabAt(tab, i) == f) { // 保证锁住的是hash桶的第一个节点,这样阻止其他写操作进入,如果锁住的不是第一个节点,那么重新开始循环
if (fh >= 0) {
binCount = 1; // 因为第一个节点处理了,这里赋值为1
for (Node e = f;; ++binCount) {
K ek;
// 找到“相等”的节点,看看是否需要更新value的值
if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node pred = e;
// 遍历到链表末尾还没碰见“相等”,那么就添加新节点到链表的末尾
// 1.8开始是末尾添加,后面的remove/replace也会尝试锁住第一个节点,这样就能保证锁住hash桶的第一个节点能够阻塞其他基本的写操作
if ((e = e.next) == null) {
pred.next = new Node(hash, key, value, null);
break;
}
}
}
else if (f instanceof TreeBin) { // 红黑树就使用红黑树的方式进行添加
Node p;
binCount = 2; // 设置为2,保证addCount中能够进行扩容判断,同时也不会触发链表转化为红黑树的操作
if ((p = ((TreeBin)f).putTreeVal(hash, key, value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) { //
if (binCount >= TREEIFY_THRESHOLD) // 添加之前,一个hash桶中的节点数目达到阈值,尝试转化为红黑树保存
treeifyBin(tab, i);
if (oldVal != null) // 表明实质上是replace操作,不用更改计数值
return oldVal;
break;
}
}
}
addCount(1L, binCount); // 计数值加1
return null;
}
// 预先扩容,循环put
public void putAll(Map m) {
tryPresize(m.size());
for (Map.Entry e : m.entrySet())
putVal(e.getKey(), e.getValue(), false);
}
public V remove(Object key) {
return replaceNode(key, null, null);
}
/**
* Implementation for the four public remove/replace methods:
* Replaces node value with v, conditional upon match of cv if non-null. If resulting value is null, delete.
*/
// remove删除,可以看成是用null替代原来的节点,因此合并在这个方法中,由这个方法一起实现remove/replace
final V replaceNode(Object key, V value, Object cv) {
int hash = spread(key.hashCode());
for (Node[] tab = table;;) {
Node f; int n, i, fh;
if (tab == null || (n = tab.length) == 0 || (f = tabAt(tab, i = (n - 1) & hash)) == null) // 没有节点,删除不了,直接退出
break;
else if ((fh = f.hash) == MOVED) // 发现转发节点,表明此时正在进行扩容,去帮助扩容
tab = helpTransfer(tab, f);
else {
V oldVal = null;
boolean validated = false;
synchronized (f) { // 这里跟put一样,尝试锁住hash桶的第一个结点,要保证锁住的是第一个结点
if (tabAt(tab, i) == f) {
if (fh >= 0) {
validated = true;
for (Node e = f, pred = null;;) {
K ek;
if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) {
V ev = e.val;
if (cv == null || cv == ev || (ev != null && cv.equals(ev))) {
oldVal = ev;
if (value != null)
e.val = value;
else if (pred != null)
pred.next = e.next;
else
setTabAt(tab, i, e.next); // 删除的是第一个节点,就重设第一个节点,此时相当于已经释放了锁
}
break;
}
pred = e;
if ((e = e.next) == null)
break;
}
}
else if (f instanceof TreeBin) { // 处理红黑树的情况
validated = true;
TreeBin t = (TreeBin)f;
TreeNode r, p;
if ((r = t.root) != null && (p = r.findTreeNode(hash, key, null)) != null) {
V pv = p.val;
if (cv == null || cv == pv || (pv != null && cv.equals(pv))) {
oldVal = pv;
if (value != null)
p.val = value;
else if (t.removeTreeNode(p)) // 处理退化为链表的情况
setTabAt(tab, i, untreeify(t.first));
}
}
}
}
}
// 下面这一段判断是否是删除操作,是删除操作就把计数值减1
if (validated) {
if (oldVal != null) {
if (value == null)
addCount(-1L, -1);
return oldVal;
}
break;
}
}
}
return null;
}
/** Removes all of the mappings from this map. */
public void clear() {
long delta = 0L; // negative number of deletions 计数值的预期变化值,删除n个,delta就为-n
int i = 0;
Node[] tab = table;
while (tab != null && i < tab.length) {
int fh;
Node f = tabAt(tab, i);
if (f == null)
++i;
else if ((fh = f.hash) == MOVED) {
tab = helpTransfer(tab, f);
i = 0; // restart
}
else {
synchronized (f) { // 跟put/remove/replace一样
if (tabAt(tab, i) == f) {
Node p = (fh >= 0 ? f :
(f instanceof TreeBin) ? ((TreeBin)f).first : null);
while (p != null) {
--delta;
p = p.next;
}
setTabAt(tab, i++, null); // 清空这个hash桶
}
}
}
}
if (delta != 0L)
addCount(delta, -1);
}
public boolean remove(Object key, Object value) {
if (key == null)
throw new NullPointerException();
return value != null && replaceNode(key, null, value) != null;
}
public boolean replace(K key, V oldValue, V newValue) {
if (key == null || oldValue == null || newValue == null)
throw new NullPointerException();
return replaceNode(key, newValue, oldValue) != null;
}
public V replace(K key, V value) {
if (key == null || value == null)
throw new NullPointerException();
return replaceNode(key, value, null);
}
十一、视图以及迭代器
这个使用上没什么变化,实现上主要的改动,在第九点的只读遍历器Traverser中已经说了。理解了前面的,以及之前版本的,这个就没什么好说的了。
十二、函数式、Stream相关的方法
这部分占据了大概40%的代码量(1.7_80的源码总共只有1620行,1.8_111的源码总共有6313行),除了本身实现变复杂了,加之更难抽象(有很多代码反复出现)外,大部分都是用来实现这两个了。
因为还没怎么研究过,截止到现在也用得不是那么多,就放在以后再说。
结语:1.8的看了很久,特别是扩容那块,扩容重叠非常难以理解。感觉上单个单个的都能解释了,但整体看来还有对不上的地方。
那几个不完全对不上的地方,留待以后顿悟,现在感觉快看吐了的,走进了死胡同。
以上内容,如有问题,烦请指出,谢谢!