《CUDA并行程序设计-GPU编程指南》读书笔记--(1)线程网格、线程块以及线程
线程网格、线程块以及线程
SPMD模型
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}__global__前缀是告诉编译器在编译这个函数的时候生成的是GPU代码而不是CPU代码,并且这段GPU代码在CPU上是全局可见的。
我们可以将线程ID用作数组的下标对数组进行访问。线程0中threadIdx.x值为0,线程1的为1,依此类推,线程127中的threadIdx.x值为127。
CPU和GPU有各自独立的内存空间,因此在GPU代码中,不可以直接访问CPU端的参数,反过来在CPU代码中,也不可以直接访问GPU端的参数。
为了传递一个数据集到GPU端进行计算,我们需要使用cudaMalloc与cudaFree来申请 和释放显存,然后再使用cudaMemcpy将数据集从CPU端复制到GPU端,这样,才可以开始计算。
执行
线程都是以每32个一组,当所有32个线程都在等待诸如内存读取这样的操作时,它们就会被挂起。术语上,这些线程组叫做线程束(32个线程)或半个线程束(16个线程)。
将这128个线程分成4组,每组32个线程。首先让所有的线程提取线程标号,计算得到数组地址,然后发出一条内存获取的指令。接着下一条指令是做乘法,但这必须是在从内存读取数据之后。由于读取内存的时间很长,因此线程会挂起。当这组中的32个线程全部挂起,硬件就会切换到另一个线程束。
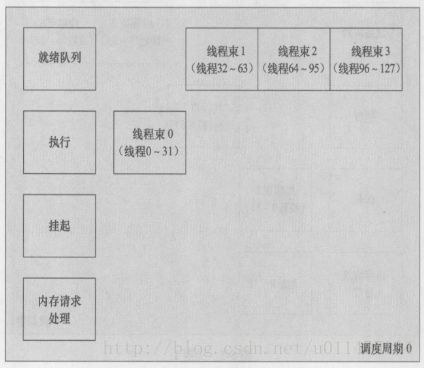
当线程束0由于内存读取操作而挂起时,线程束1就成为了正在执行的线程束。GPU一直以此种方式运行直到所有的线程束到成为挂起状态。
当连续的线程发出读取内存的指令时,读取操作会被合并或组合在一起执行。由于硬件在管理请求时会产生一定的开销,因此这样做将减少延迟(响应请求的时间)。由于合并,内存读取会返回整组线程所需要的数据,一般可以返回整个线程束所需要的数据。


假设数组下标为0~31的元素在同一时间返回,线程束0进入就绪队列。如果当前没有任何线程束正在执行,则线程束0将自动进入执行状态。渐渐地其他所有挂起的线程束也都完成了内存读取操作,紧接着它们也会返回到就绪队列。
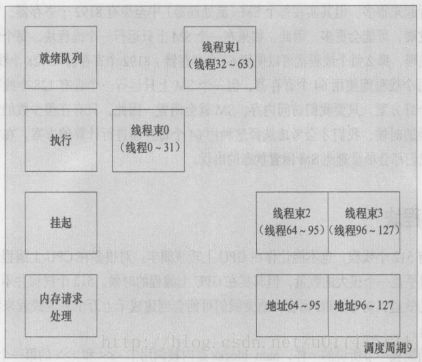
调用CUDA内核
addKernel<<>>(param1, param2, ...); 参数num_blocks表示线程块数量
参数num_threads表示执行内核函数的每个线程块所启动的线程数量
addKernel<<<2, 64>>>(dev_c, dev_a, dev_b);__global__ void addKernel(int *c, const int *a, const int *b)
{
int i =(blockIdx.x * blockDim.x) + threadIdx.x;
c[i] = a[i] + b[i];
}对第一个线程块而言,blockIdx.x是0,因此i直接就等于之前使用过的threadldx.x。然而,对于第二个线程块而言,它的blockIdx.x的值是1,blockDim.x表示本例中所要求的每个线程块启动的线程数量,它的值是64,那么对第二个线程块而言,在计算i时,要在threadIdx.x的基础上加上一个1x64线程的基地址。
线程网格
thread–线程;block–线程块;grid–线程网格;warp–线程束。
CUDA编程——GPU架构,由sp,sm,thread,block,grid,warp说起
假设我们现在正在看一张标准高清图片,这张图片的分辨率为1920×1080。通常线程块中线程数量最好是一个线程束大小的整数倍,即32的整数倍。由于设备是以整个线程束为单位进行调度,如果我们不把线程块上的线程数目设成32的整数倍,则最后一个线程束中有一部分线程是没有用的,因此我们必须设置一个限制条件进行限制,防止处理的元素超出x轴方向上所规定的范围。
为了防止不合理的内存合并,我们要尽量做到内存的分布与线程的分布达到一一映射的关系。如果我们没能做到这点,程序的性能可能会降低5倍或者更多。
在程序中,要尽量避免使用小的线程块,因为这样做无法充分利用硬件。在本例中,我们将在每个线程块上开启192个线程,在这里,选择192这个数是因为x轴方向处理的数据大小1920是它的整数倍,192又是线程束大小的整数倍。通常,192是我们所考虑的最少的线程数目。

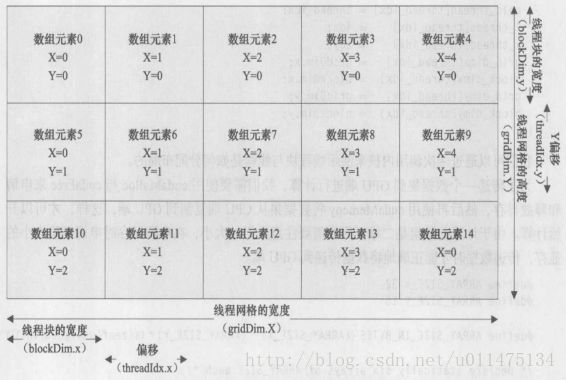
const unsigned int idx = (bloackIdx.x*bloackDim.x)+threadIdx.x;
const unsigned int idy = (bloackIdx.y*bloackDim.y)+threadIdx.y;
some_array[idy][idx] += 1.0;bloackDim.x与bloackDim.y分别表示x轴和Y轴这两个维度上线程块的数目。现在,我们来修改当前的程序,让它计算一个32×16维的数组。假设调度四个线程块,我们可以让这四个线程块像条纹布一样布局,然后让数组与线程块上的线程形成一一映射的关系,也可以像方块一样布局。
dim3 threads_rect(32,4);
dim3 blocks_rect(1,4);
some_kernel_func<<>>(a,b,c); 或
dim3 threads_rect(16,8);
dim3 blocks_rect(2,2);
some_kernel_func<<>>(a,b,c); dim3是CUDA中一个比较特殊的数据结构,我们可以用这个数据结构创建一个二维的线 程块与线程网格。
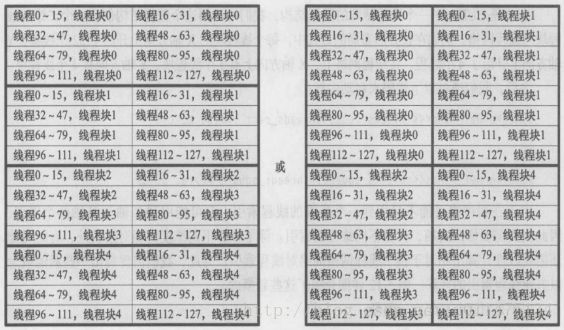
那么,我们为什么选择长方形的布局而不是选择正方形的布局?这主要有两个原因。第一个原因是同一个线程块中的线程可以通过共享内存进行通信,这是线程协作中一种比较快的方式。第二个原因是在同一个线程束中的线程存储访问合并在一起了,而在当前费米架构的设备中,高速缓冲存储器的大小是128个字节,一次直接访问连续的128字节比两次分别访问64字节要高效得多。在正方形的布局中,0~15号线程映射在一个线程块中,它们访问一块内存数据,但与这块内存相连的数据区则是由另一个线程块访问的,因此,这两块连续的内存数据通过两次存储访问才获得,而在长方形的布局中,这只需要一次存储访问的操作。但如果我们处理的数组更大,例如64×16,那么32个线程就能进行连续存储访问,每次读出128字节的数据,也就不会出现刚刚所说的那种情况了。
- gridDim.x:线程网格x维度上线程块的数量
- gridDim.y:线程网格y维度上线程块的数量
- blockDim.x:一个线程块x维度上的线程数量
- blockDlm.y:一个线程块y维度上的线程数量
- theadIdx.x:线程块x维度上的线程索引
- theadIdx.y:线程块y维度上的线程索引
线程束
一个线程束是一个单独的执行单元,使用分支(例如,使用if、else、for、while、do、swith等语句)可以产生不同的执行流。
GPU在执行完分支结构的一个分支后会接着执行另一个分支。对不满足分支条件的线程,GPU在执行这块代码的时候会将它们设置成未激活状态。当这块代码执行完毕之后,GPU继续执行另一个分支,这时,刚刚不满足分支条件的线程如果满足当前的分支条件,那么它们将被激活,然后执行这一段代码。最后,所有的线程聚合,继续向下执行。
__global__ some_func(){
if(some_condition){
action_a();
}else{
action_b();
}
}代码中,假设索引为偶数的线程满足条件为真的情况,执行函数action_a(),索引为奇数的线程满足条件为假的情况,执行函数action_b()。由于硬件每次只能为一个线程束获取一条指令,线程束中一半的线程要执行条件为真的代码段,一半线程执行条件为假的代码段,因此,这时有一半的线程会被阻塞,而另一半线程会执行满足条件的那个分支。如此,硬件的利用率只达到了50%。
事实上,在指令执行层,硬件的调度是基于半个线程束,而不是整个线程束。这意味着,只要我们能将半个线程束中连续的16个线程划分到同一个分支中,那么硬件就能同时执行分支结构的两个不同条件的分支块,例如,示例程序中if-else的分支结构。这时硬件的利用率就可以达到100%。
__global__ some_func(){
if((thread_idx % 32) < 16){
action_a();
}else{
action_b();
}
}在理想状态下,如果执行函数action_a()的16个线程都访问一个浮点数或者一个整数,那么将获取64个字节的内存数据, 如果另外一半线程束也进行同样的操作,那么就可以只发起一个128字节的内存访问命令,同时将这两半线程束所需的数据取得。但这种现象发生的条件很苛刻,只有当缓存大小与线程束需要获取的内存数据大小相同而且数据在内存分布上是连续的才会发生。
为了最大限度地利用设备,使程序性能得到提升,我们应尽量将每个线程块开启的线程数设为192或256。
SM容纳线程块的数目会受到内核中是否用到同步的影响。而所谓的同步,就是当程序的线程运行到某个点时,运行到该点的线程需要等待其他还未运行到该点的线程,只有当所有的线程都运行到这个点时,程序才能继续往下执行。例如,我们执行一个读内存的操作,在这个读操作完成之后进行线程同步,所有的线程都要进行读操作,但由于不同线程执行有快有慢,有的线程束很快就完成操作,有的则需要更长的时间,执行完的线程需要等待还未完成读操作的线程,只有当所有的线程都完成读操作,程序才能继续向下执行。
每个线程块只有当它执行完全部指令时才会从SM撤走,因此,有时会出现这种情况,所有的线程束都闲置地等待一个线程束执行完毕,SM因为这个原因也闲置了,这大大降低了程序的性能。由此可见,每个线程块开启的线程数越多,就潜在地增加了等待执行较慢的线程束的可能性。
线程块的调度
在线程块调度者为每个SM初始化分配了线程块之后,就会处于闲置状态,直到有线程块执行完毕。当线程块执行完毕之后就会从SM中撤出,并释放其占用的资源。由于线程块都是相同的大小,因此一个线程块从SM中撤出后另一个在等待队列中的线程块就会被调度执行。所有的线程块的执行顺序是随机、不确定的。因此,当我们在编写一个程序解决一个问题的时候,不要假定线程块的执行顺序,因为线程块根本就不会按照我们所想的顺序去执行。
保证在每个GPU中,线程块的数目都是SM数目的整数倍,以此提高设备的利用率。