【论文总结】weakly- and semi-supervised learning of a DCNN for semantic Image Segmentation
一、概述
这篇文章研究了如何从弱注释的训练数据(如边界框或图像级标签)或少量强标记图像和许多弱标记图像的组合中学习DCNN用于语义图像分割的问题,在弱超监督和半监督条件下提出了期望最大化(EM)方法。
代码:https://bitbucket.org/deeplab/deeplab-public(caffe框架)
二、研究内容及方法
文章将焦点放在用弱标签训练调参上,所以训练阶段没使用CRF,只在测试阶段使用。
编码:m表示像素,Ym表示像素m的标签。如果图片上出现了第![]() 个标签,即
个标签,即 ![]() 则 zl = 1 。
则 zl = 1 。
(一)像素级标注(看不到)通过mini-batch梯度下降优化损失函数J(θ)。
(二)图像级标注(可看到):提出EM方法学习模型参数θ,分为EM-Fixed 和 EM-Adapt。
EM-Fixed 如下图Algorithm 1所示:

算法先将logP(z|y) 因式分解,这样可以独立计算每个像素的E-step分割。设定前景偏置(fg bias)大于背景偏置(bg bias),避免将某些像素归为背景里。过程如下图所示:

EM-Adapt:
if ![]() 则将
则将![]() 部分设为
部分设为![]() 类,if
类,if ![]() ,则假设图片上没有
,则假设图片上没有![]() 类。设置图像和类依赖的偏置
类。设置图像和类依赖的偏置![]() ,以便按规定比例分配给前景和背景,详细的就不知道了。
,以便按规定比例分配给前景和背景,详细的就不知道了。
EM vs MIL:两种MIL方法,一种是基于局部标签的每类空间最大值定义MIL分类目标,另一种采用softmax功能。虽然MIL方法在图像分类任务中运行良好,但由于它不促进全面的对象覆盖,不太适合分割:DCNN被调整为专注于最独特的对象部分(例如人脸) 而不是捕捉整个对象(例如人体)。
(三)边界框标注(三种可选方法)

1.Bbox-Rect: 将长方形边界框里的所有像素都当作正样本处理,如果某像素在多个框里,则把它归为最小框的类,这种方法容易把背景当作正样本,因此提出了第二种Bbox-Seg;
2.Bbox-Seg: 为了去除背景像素,采用与deeplab中一样的CRF,设置CRF的一元项限制框里中心区域(![]() 的像素)为前景,框外像素为背景,通过交叉验证CRF参数来最大限度地提高分割精确度,并在一小组完整注释的图像中进行分割。
的像素)为前景,框外像素为背景,通过交叉验证CRF参数来最大限度地提高分割精确度,并在一小组完整注释的图像中进行分割。
这两种方法如上图所示,是将边界框注释的分割图作为预处理进行估计,然后将这些估计的标签视为ground truth采用像素级标注的方式训练。
3.Bbox-EM-Fixed:EM-Fixed的变体,可以在整个训练过程中,细化预测的分割图,增加边界框内的前景对象分数。
(四)混合强弱标注
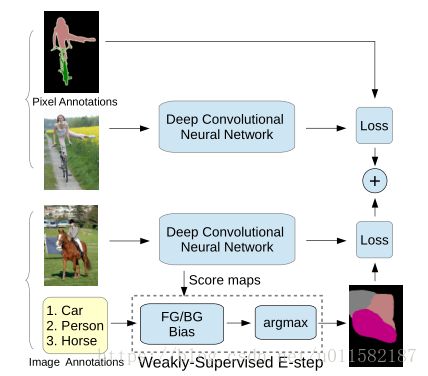
强标注就是像素级标注,弱标注是图像级标注,文章结合两者,在DCNN的SGD训练过程中,同时喂入这两种数据,采用EM算法在每次迭代中估计弱注释图像的潜在语义分割。
三、实验结果
dataset: PASCAL VOC 2012分割标准,选取该数据集上1464(train),1449(val)和1456(test)张图片,另外又额外标注了 10582 (train_aug) and 12031 (trainval_aug) 增强数据集(MS-COCO),以IOU为测试标准
为了模拟只有弱注释可用并且比较公平的情况(例如,对于所有设置使用相同的图像),文章从像素级标注生成弱标注。 通过汇总像素级标注很容易生成图像级标签,而通过在数据集中绘制包含每个对象实例(PASCAL VOC 2012还提供实例级注释)的矩形来生成边界框注释。
VGG16 ImageNet模型初始化参数,利用deeplab的两种DCNN结构做实验,发现它们在接受视野(FOV)大小方面有所不同。当训练图像包含像素级标注时,大视场(224×224)效果最好,而只有图像级别注释时,小视场(128×128)效果更好。使用EM方法学习deeplab-CRF模型的DCNN结构时,batch-size为20-30,初始学习率为0.001(最后分类层为0.01),固定迭代次数之后学习率乘以0.1,动量0.9,权重衰减率为0.0005,采用PASCAL VOC 2012数据集,在NVIDIA Tesla K40 GPU上fune-tuning大约需要12个小时。DCNN和密集CRF分开训练,通过交叉验证学习CRF参数以保证在PASCAL 验证集上达到最大化IOU。文章使用10个平均场迭代进行密集CRF后处理,IOU提升了3-5%。
(像素级标注)下图是文章在PASCAL VOC 2012 数据集上复现deeplab-CRF-LargeFOV模型的结果( 67.6% on val and 70.3% on test):

(图像级标注)用增强的10582张PASCAL VOC 2012 数据集训练deeplab-CRF模型,评估EM方法。结果如上图所示,EM-Fixed中设bias_fg=5,bias_bg=3,发现结果对两者之差比较敏感,对绝对值反倒不敏感。在自适应EM-Adapt中,ρbg = 40%,ρfg=前景图像区域的20%(由弱标签集指定) 。还研究了在不同数量像素级标注下的半监督学习方法,使用PASCAL VOC 2012 数据集中部分训练集子集做强标注数据集,另一部分不重叠的增强训练集做弱标注训练集,在使用EM-Fixed方法对只有图像级的图像做验证,发现在半监督学习中效果要比EM-Adapt好,详细结果看上图吧。
下图是测试文章中的方法与比较有竞争力的方法结果对比:

(边界框标注)使用来自train_sug边界框标注的数据训练deeplab-CRF网络,Bbox-Rect和Bbox-Seg法预处理数据,100个全标注的VOC验证集,交叉验证参数α,α从20%变化到80%,发现当α= 20%可以最大限度地从边界框中恢复ground truth前景的IOU的准确性。结果如下图:
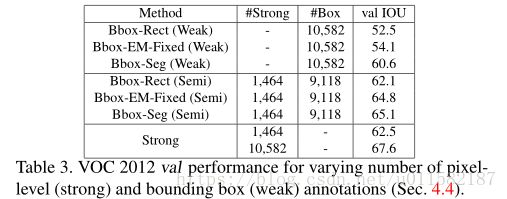
下图是测试结果,可以看出当有足够的像素级图像时,E-step能够很好的估测分割。

对比图像级和边界框级标注,可以看到当足够数量的像素级注释也可用时,边界框标注相对于图像级标注几乎没有什么价值。
(Exploiting Annotations Across Datasets): MS-COCO数据集学习deeplab模型,对PASCAL VOC 2012做分割。比较结果如下图:

Cross-Pretrain(strong):在MS-COCO上预训练,替换顶层网络的权重,在VOC上fune-tuning,两者都是像素级标注。
Cross-Joint(Strong):在MS-COCO和VOC上共同预训练网络,对共有的类共享顶层权重,两者都是像素级标注。
Cross-Joint(semi):和Cross-Joint(Strong)一样,区别是使用VOC的像素级标注,MS-COCO的像素标注和图像集标注。
可以看到Cross-Joint(semi)验证效果还是不错的。
文章使用VOC测试集对论文里提出的方法以及其他分割网络进行了实验,结果如下:73.9%的结果还是不错的。

四、总结
文章探讨了在训练一种先进的语义图像分割模型中使用弱或部分注释。 对具有挑战性的PASCAL VOC 2012数据集进行大量实验表明:(1)仅在图像级使用弱注释似乎不足以训练高质量的分割模型。(2)对训练集中的图像使用弱边界框注释和仔细的分割推理就足以训练一个竞争模型。(3)在半监督设置中将少量像素级注释图像与大量弱注释图像组合在一起时获得优异的性能,几乎匹配所有训练图像具有像素级注释时获得的结果。(4)利用来自其他数据集的额外弱或强注释结果会有很大的提高。