Python使用requests库模拟登陆网站的方式--以豆瓣为例
初次接触爬虫的时候,总会看到模拟登录网站的字眼,然后又是get、post等一堆不知道什么意思的字眼。百度get、post之后也不太清楚什么意思,只知道好像是打开网址的时候顺便提交一些数据。然后又在想:我怎么知道哪些网址需要post,又要post什么数据?哪些网址又是需要get的?
后来慢慢接触的多了就知道了,get方式其实没什么,看网址就知道了,比如百度搜索关键词:‘get’,那么只需要http://www.baidu.com/s?wd=%s把%s换为get就可以了。而post方式很多时候会用在登录网站的时候。本片文章就将以python模拟登录豆瓣顺便讲讲post。
1. 通过post方式模拟登录。
post方式登录网站,需要先将必要信息填充到一个dict中,例如:
Data={‘username’:username,’password’:password}然后使用requests的post方式进行登录:
requests.get(url,data=data)这里有几个问题:一是我怎么知道需要 哪些信息填写到dict中 呢?二是我怎么知道需要 post的地址url是哪个 呢?
对于这两个问题,以豆瓣为例。
首先打开豆瓣的登录页面
可以看到需要post的地址就是url=’http://account.douban.com/login’,怎么样?第二个问题是不是很简单?
那么需要哪些数据进行post呢?我们使用firefox浏览器,里面有一个工具叫httpfox,如果没有看到请自行下载。如果不是使用Firefox浏览器,可以下载一个软件叫fiddler。
下面我将以httpfox工具讲述如何知道需要post的数据。
我们先打开httpfox。它张这样子:
然后在登录页面填写账号密码。再点击登录
点击登录之后去查看httpfox,找到一个Method是post的一行,点击它(点击登录前建议先清空httpfox列表)。
然后点击POST Data
然后就可以看到需要post哪些数据了。对于login那个乱码,我们可以忽略它。然后我们就可以愉快的填写post报头了。:
Data={'source':None,
'redir':'http://www.douban.com',
'form_email':username,
'form_password':password,
'remember':'on'}可以看到上面就是需要post的数据了,其实必要的就两个,一个是form_email,还有一个是form_password,其他都不重要。
有data后就可以直接用requests进行登录了。
requests.post(url,data=data)当然,有时候会遇到验证码!!!遇到验证码可真抓瞎!本来遇到验证码我是这样想的:先像上面一样post一下,然后把验证码图片抓下来,然后手动输入验证码,接着data中增加输入的验证码再post。。。:
url='https://accounts.douban.com/login'
data={'redir':'http://www.douban.com',
'form_email':'[email protected]',
'form_password':'xxxxx',
'remember':'on'}
#获得验证码id
captchid=req.get('http://www.douban.com/j/new_captcha',headers=headers).content
#得到验证码
captchurl='http://douban.com/misc/captcha?size=m&id='+captchid
#下面三步为显示验证码
f=cStringIO.StringIO(urllib2.urlopen(captchurl).read())
img=Image.open(f)
img.show()
#输入验证码
codeimg=raw_input('plz input the veritify cpde:')
data['captcha-solution']=codeimg
data['captcha_id']=captchid
#s=req.post(url,data=data,headers=headers)结果不行!!!
反正豆瓣遇到验证码我是没办法了!
难道我就不登录了吗??显然还有其他办法。下面就介绍第二种办法。
2. 通过外部获得cookies模拟登陆。新手建议用这个
其实第一种方法也是要先获得cookies,然后再在有cookies的情况下去抓取数据。既然只是要cookies,那么为什么不可以直接从外部引入cookies呢?
好,既然这样,我们就先从如何获取cookies说起吧!
首先,还是请来我们的老朋友:httpfox。Httpfox真的挺不错的~~我们还是以豆瓣为例。我们先打开httpfox,登录豆瓣。
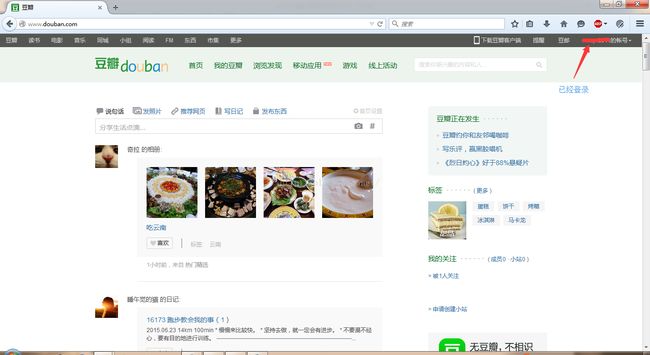
然后随便浏览一个页面,比如“我的豆瓣”,点击它进去以后,切换到httpfox。(浏览之前先清空httpfox列表)
切换到httpfox之后就可以看到第一行数据。
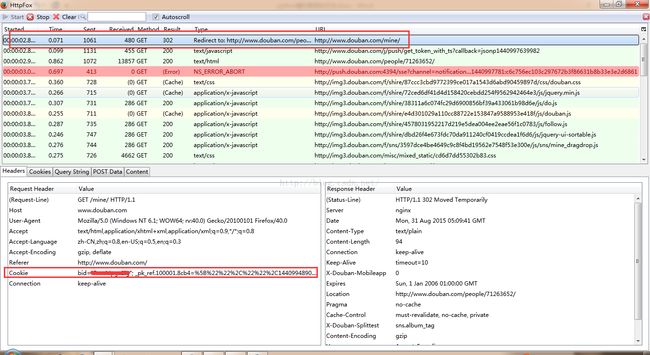
点击它,就可以在下方看到cookies了。我们把cookies复制下来就得到了cookies了!!是不是很简单呢?
得到cookies之后,requests还不能直接用,还需要处理一下。
我们可以看到的是,得到的cookies格式是这样的:
bid=xxxxx;_pk_ref.100001.8cb4=xxxxxxx;__utma=xxxxx;…
我们只需要把这种格式的cookies转换成字典就可以了。
cookies={}
for line in raw_cookies.split(';'):
key,value=line.split('=',1)#1代表只分一次,得到两个数据
cookies[key]=value
testurl='http://www.douban.com/people/71263652/'
s=req.get(testurl,cookies=cookies)