NodeJS模拟登录学校教务系统+爬取成绩
今天天气甚好,并且刚刚学会基本的nodejs爬虫和抓包,然后就想着爬取学校的教务系统去尝试着爬取成绩。下面我为大家一一讲解Nodejs模拟登录学校的教务系统+爬取页面成绩并进行解析。
知识和工具准备
① Nodejs的基本知识。
②Fiddler抓包工具的使用。
③request、cheerio第三方插件的使用。
第一步:模拟登录
就拿我们学校为例,先拿到了学校的无须验证码登录的url,其他读者们,自己学校的话,可以通过fiddler抓包工具去抓包看看传到登录接口的参数还有请求接口的方法。
先抓取发送到学校服务的包并进行解析
//我们学校的hostname地址以及端口、请求方式为http请求、请求登录的路径、请求的方法、参数
const hostName = 'jwgl.just.edu.cn';
const port = 8080;
const path:'/jsxsd/xk/LoginToXk';
const method = "POST";
//传递的参数
USERNAME:"xxxx", //用户的学号
PASSWORD:'xxxxx', //用户的密码
发送请求,并且根据返回的内容进行是否登录成功进行判断并进行内容的爬取和解析。
(所有的解释直接看代码中。)
const http = require('http');
const queryString = require('querystring');
const request = require('request');
const cheerio = require('cheerio');
const hostName = 'jwgl.just.edu.cn';
const port = 8080;
//将参数转换成字符串
const postData = queryString.stringify({
USERNAME:"xxxxx",
PASSWORD:'xxxxx',
});
let cookieAll ;
//发送的请求的条件
let option = {
hostname:hostName,
method:"POST",
port:port,
path:'/jsxsd/xk/LoginToXk', //请求的路径
//头文件的配置
headers:{
'Content-Type': 'application/x-www-form-urlencoded',
'Content-Length': Buffer.byteLength(postData) //转换成buffer和字符串的合并
}
};
//进行发送的请求
const req1 = http.request(option,(res)=>{
res.setEncoding('utf8'); //对返回的字符串进行转码,转换成utf8
console.log("相应头部",res.headers);
console.log(res.headers.location);
//根据发送回来的数据,进行合并。
if(res.headers.location){
//解析并且合并cookie。
console.log(res.headers['set-cookie']);
let cookie = res.headers['set-cookie'];
let cookie1 = cookie[0].slice(0,cookie[0].indexOf(';'));
let cookie2 = cookie[1].slice(0,cookie[1].indexOf(';'));
cookieAll = cookie1+";"+cookie2;
console.log(cookieAll);
//解析结果在下方图一
//用fiddler抓包抓取url并且进行分析在下方图二
//获取可选的查询条件
request({
url:'http://jwgl.just.edu.cn:8080/jsxsd/kscj/cjcx_query?Ves632DSdyV=NEW_XSD_XJCJ',
method:'POST',
headers:{
'Content-Type':'application/x-www-form-urlencoded',
'Cookie': cookieAll,
}
},(err,red2,body)=>{
if(err){
console.log(err.message)
}else{
//这段代码进行页面的解析 解析过程和结果在图三
// console.log(body);
let $ = cheerio.load(body);
let content = $('#kksj').children(); //#kksj为页面中html中的选择框的id
console.log("选项的长度为:",content.length);
console.log("原来的content:",content);
console.log("可选择的学期:");
for(let i = 0;i<content.length;i++){
console.log(content[i].children[0].data)
}
}
});
//查询成绩的条件(学期) 传递的参数以及url进行抓包分析,在下方图四
//查询的条件
let Body = queryString.stringify({
kksj:'2018-2019-1', //查询条件
kcxz:"",
kcmc:"",
xsfs:'all'
});
let options = {
method:'POST',
url:'http://'+hostName+":"+port+'/jsxsd/kscj/cjcx_list',
headers:{
'Content-Type':'application/x-www-form-urlencoded',
'Cookie': cookieAll, //携带cookie
'Content-Length':Body.length
},
};
console.log("options为",options);
//条件查询成绩的api
request({
method:'POST',
url:`http://${hostName}:${port}/jsxsd/kscj/cjcx_list?${Body}`,
headers:{
'Content-Type':'application/x-www-form-urlencoded',
'Cookie': cookieAll,
},
},(err,red,body)=>{
if(!err&&red.statusCode === 200){ //根据返回的页面进行爬取和解析数据在下方图五
//console.log(body);
let $ = cheerio.load(body);
let content = $('#dataList tr');
//解析过程----
for(let i=1 ;i<content.length;i++){
console.log(
"课程号:"+content[i].children[5].children[0].data+" "+
"课程名称:"+ content[i].children[7].children[0].data+" "+
"成绩:"+content[i].children[9].children[0].data+" "+
"学分:"+content[i].children[11].children[0].data+""+
"总学时:"+content[i].children[13].children[0].data+""
)
}
}
})
}
res.on('data',(data)=>{
console.log(data)
});
res.on('end',()=>{
console.log("响应中已经没有数据")
});
res.on("error",()=>{
console.log("错误的信息",error.message)
})
});
req1.write(postData);
req1.end();
图一:

图二:用fiddler抓包进入可选择的条件进行抓取请求的url以及传递的参数

图三:
html页面解析中这个id中可选择的text
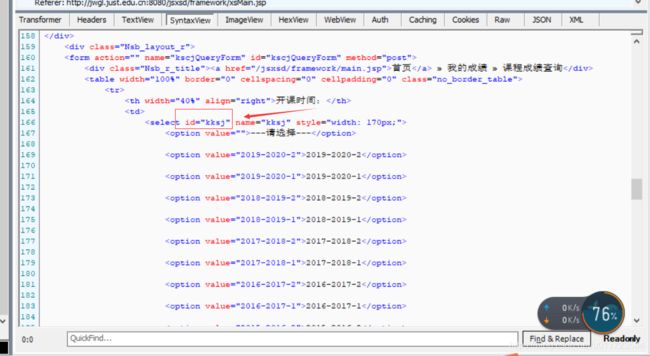
解析并且循环打印出来的结果:

图四:
分析url:

分析传递的参数:

图五:
解析的页面table

解析结果:

总结:
全部的过程到这就结束了,如何读者需要在第三方软件显示的话,就可以写一个接口然后返回给前端,前端再进行解析并且显示就完美了。
作者解析的是在返回给微信小程序,在微信小程序中进行解析。如图:
