elasticsearch、kibana和分词器安装测试
目录
分布式搜索引擎
1.1. 搜索引擎
1.2. 分布式存储与搜索
1.3. Lucene VS solr VS elasticsearch
Lucene
Solr 与 Elasticsearch 性能对比
Elasticsearch VS Solr
2. ElastchSearch核心术语学习
2.1. 术语学习
2.2. type为什么会去掉
什么是倒排索引
安装
elasticsearch 可视化工具
elasticsearch-head
kibana
分词器插件
小结
分布式搜索引擎
1.1. 搜索引擎
比如网络爬虫,检索排序,网页处理,大数据技术相关,都要使用到搜索引擎,对于文件信息内容进行检索,通过搜索引擎提供快速,高相关性的信息服务。
1.2. 分布式存储与搜索
分布式就是通过多个节点构成的服务,可以横向扩张,所扩展的节点可以进行请求的分摊,以及存储的扩展。
1.3. Lucene VS solr VS elasticsearch
Lucene
-
Lucene 是一套信息检索工具包(Java 开发的),并不包含搜索引擎系统。本身不具备分布式、集群、HA(高可用)等特性。
-
Solr:是基于 Lucene 开发的一个搜索引擎应用,是 Apahce下的顶级开源项目,需要独立部署在tomcat上,可以实现集群和分片,自身不支持集群结构,需要zookeeper来进行集群的支持提供服务注册,进行分布式索引查询,也是可以自己实现故障转移的(3组节点,每组2个solr,互为主从)
1) 最大的问题是建立索引的过程中,索引效率下降的极其严重,实时搜索效率不高
2)如果不考虑索引创建的同时,索引更新频率不高的情况下,solr的查询速度是略高于ES
3)支持添加多种数据格式到引擎中
- Elasticsearch:也是基于lucene的分布式搜索引擎,对外提供了很多restful风格的接口,数据交互使用json格式。
可以支持PB级别(2的50次方字节)的搜索,提供进实时的查询,可以支持PB级别的搜索,提供进实时的查询ELK(Elasticsearch、Logstash、Kibana)早期常用于进行日志分析系统的搭建
Solr 与 Elasticsearch 性能对比
1. 当单纯的对已有数据进行搜索时,Solr更快。
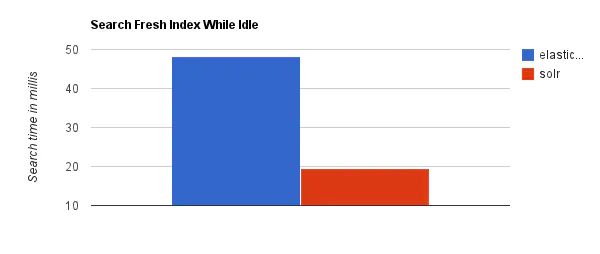
2. 当实时建立索引时, Solr会产生io阻塞,查询性能较差, Elasticsearch具有明显的优势。
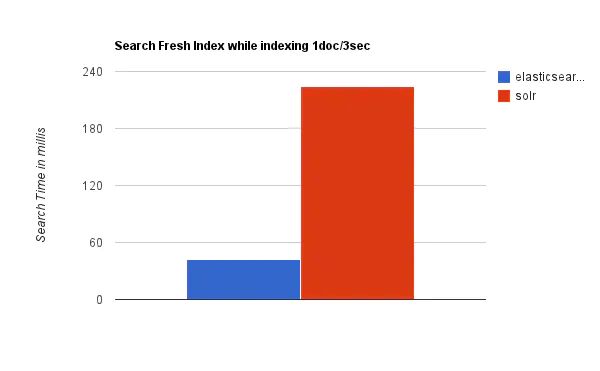
3. 随着数据量的增加,Solr的搜索效率会变得更低,而Elasticsearch却没有明显的变化。

- 综上所述,Solr的架构不适合实时搜索的应用
Elasticsearch VS Solr
1、Elasticsearch 开箱即用。Solr就会相对复杂一点点
2、Solr使用利用 Zookeeper来进行分布式管理。Elasticsearch 自带分布式协调管理功能
3、Solr 支持的数据格式比较多(XML、JSON),Elasticsearch 仅仅支JSON。
4、Solr 的官方的提供的功能的更多。Elasticsearch 更加注重 核心功能,它拥有良好的插件机制。高级功能,都是可以使用第三方插件提供。
5、Solr查询更快,索引更新时候很慢(插入和删除慢)。
- Elasticsearch 建立索引快(查询相对就会慢些),实时查询会比较快。
- Solr 是一个比较传统的应用解决方案。ES 相对来说就比较少了
6、Solr生态和用户比较大。Elasticsearch相对来说比较少(版本更新快,很多人还在用旧版本,学习成本也比较高)
2. ElastchSearch核心术语学习
2.1. 术语学习
- 索引index
- 我们可以和数据库去类比,整个的ES就相当于一个数据库服务
- 我们数据库中的表就是ES中的index
- 类型type
- 相当于一个逻辑类型
- 比如商品的分类:食品、服饰、电子产品
- ESv7.x以后就不再使用type了,5.x/6.x还有
- 文档document(doc)
- 相当于一个数据库表里的一行一行的数据
- 就是索引中一条一条的数据
- 字段field
- 数据行的某一列
- 映射的mappings
- 相当于表结构的类型定义
- NRT
- Near Real Time
- ES中新的文档被加入后可查询的时间间隔非常微弱,接近实时
- shard
- 数据分片的概念,需要进行水平扩展服务节点只需要加入新的机器到集群中即可
- 集群的每个数据节点都是HA的
- 主分片:承担数据写入的访问的作用
- replica备份分片:除了做备份以外,还承担了读数据的水平负载作用
- replica:备份分片
MySql 和 Elasticsearch 概念类比
| MySql | Elasticsearch |
|---|---|
| 数据库(database) | 索引 |
| 表(table) | types |
| 行(rows) | 文档(documents) |
| 字段(columns) | 字段(Fields) |
2.2. type为什么会去掉
1、为什么会有type?
index库-->type表-->doc记录
如果要对记录进行分组,只需要给doc加一个分组的记录field即可,然后使用ES的分组桶来统计
2、因此在7.x完全去掉type的概念了
什么是倒排索引
由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)
也可以称为反向索引。
- 思考:Redis在查询的时候:key-value?是通过key来找到的value,是否可以通过value来找key?通过value找到和这个value相似度极高的内容?
redis 只能实现正向索引。
安装
1. 下载
-
国内华为云镜像安装,目前最新版是 7.7,同步官网
https://mirrors.huaweicloud.com/elasticsearch/7.7.0/ -
kibana 也是最新 7.7,最好和 elasticsearch 版本同步。
https://mirrors.huaweicloud.com/kibana/7.7.0/
2. 解压安装包(先讲解windows的应用,后续会补上Docker上安装)
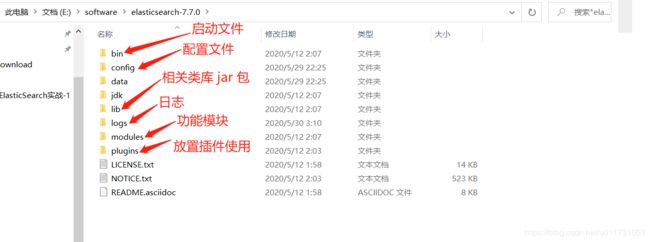
注意,注意,请注意:
1. 文件夹目录不要有 空格隔开;
2. 文件夹不要有中文;
3. 一定要安装 JDK,要安装正确
3. 启动
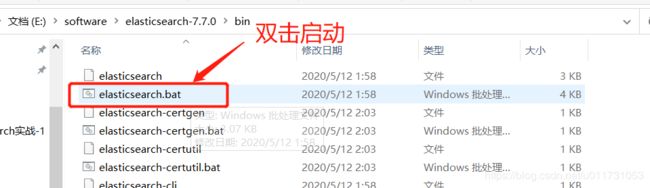
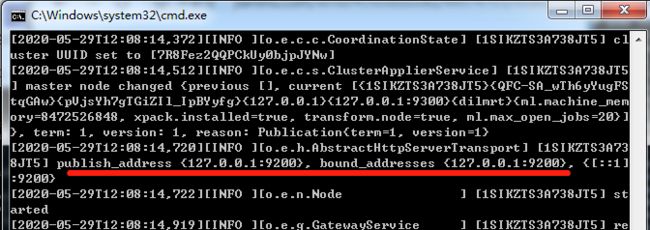
4. 访问测试 http://localhost:9200
9200:http协议,用于外部通信,提供服务
9300:Tcp协议,ES集群之间及内部服务通信的端口


elasticsearch 可视化工具
elasticsearch 本身没有界面控制,需要使用第三方工具查看。
elasticsearch-head
- 第一个工具是:elasticsearch-head,这个服务需要安装 NodeJs 环境
GitHub: https://github.com/mobz/elasticsearch-head
1)解压
2)下载依赖
# 安装了 nodejs,并且配置了cnpm
cnpm intall
npm run start
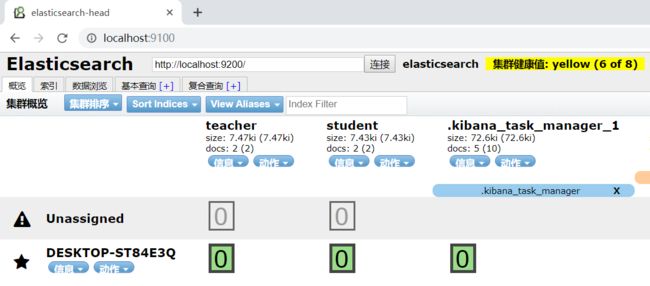
启动了 elasticsearch 会自动连接,elasticsearch、elasticsearch-head、kibana 结合使用。
kibana
2. 第二个工具 kibana
下载网址:
https://mirrors.huaweicloud.com/kibana/7.7.0/

3. 访问测试 http://localhost:5601
修改国际化
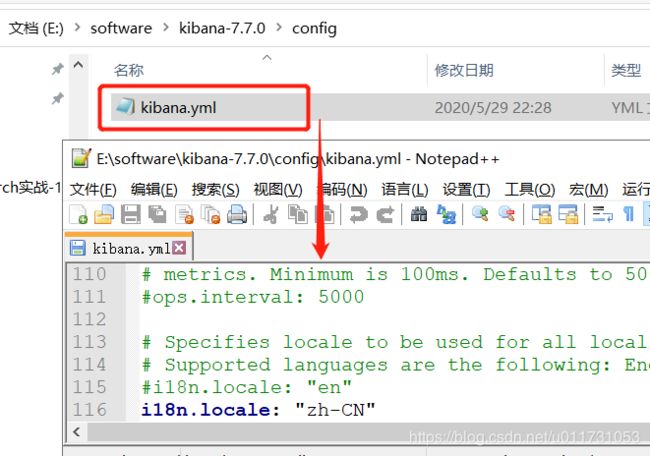
4. 操作
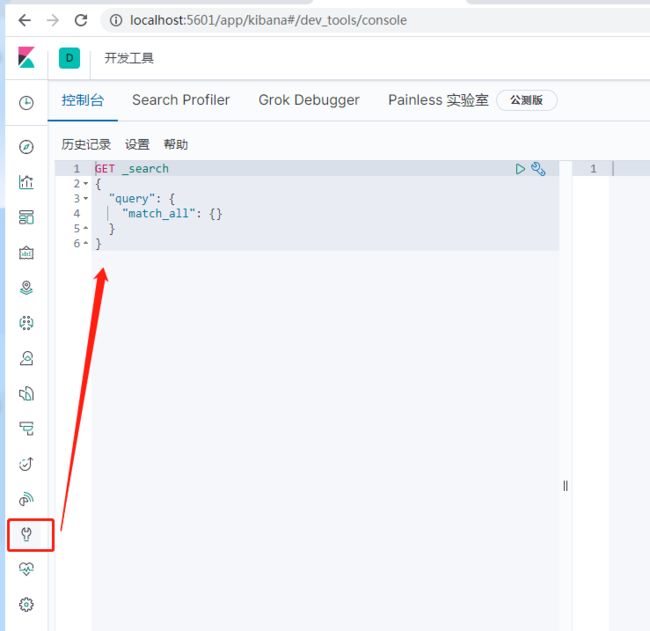

- 增删改查
# 新增
POST /teacher/_doc/3
{
"name":"MR CHEN",
"age":27,
"email":"[email protected]"
}
# 查询
GET /teacher/_doc/3
# 更新
POST /teacher/_doc/3/_update
{
"doc":{
"name":"MR GUO"
}
}
# 删除
DELETE /teacher/_doc/3
- 只支持 JSON 格式
- Restful 风格
- 上面 book:代表索引库,wuxia:代表 type (可以忽略),1:代表id
| 名称 | 作用 |
|---|---|
| PUT | 添加、更新数据 |
| GET | 获取数据 |
| DELETE | 删除数据 |
分词器插件
分词:将一个完整的词或语句,拆分成一个个关键字,搜索的时候就会进行关键字查找搜索。
例如:
金庸武侠小说之神雕侠侣:金庸 武侠 小说 神雕侠侣
默认是不符合我们的基本要求,分词,中文分词器可以使用 ik 分词器来解决这个问题。
IK 分词器提供了两种算法:ik_smart(最少切分)和 ik_max_word(最细粒度划分)
2. 解压到 elasticsearch-7.7.0 的 plugins 目录下
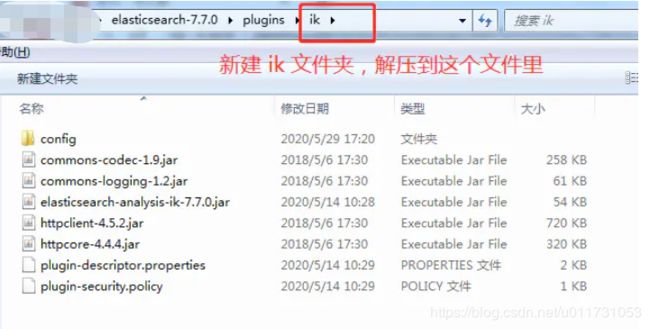
3. 自定义分词器
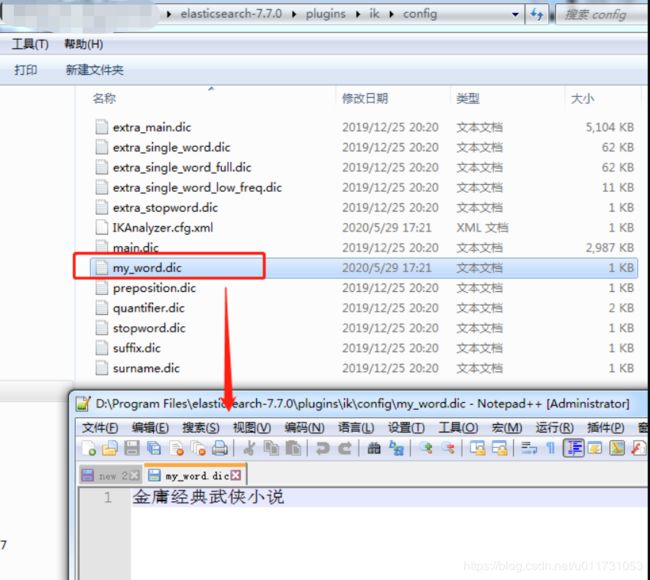
配置自定义分词器
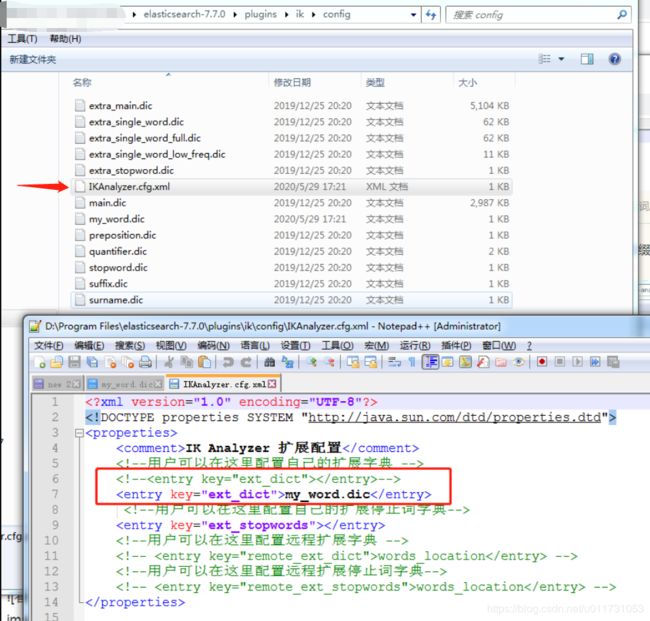
4. 重启 elasticsearch 和 kibana
小结
| method | url 风格 |
|---|---|
| PUT | localhost:9200/索引/类型名称/文档id |
| POST | localhost:9200/索引/类型名称{} |
| POST | localhost:9200/索引/类型名称/文档id/_update |
| DELETE | localhost:9200/索引/类型名称/文档id |
| GET | localhost:9200/索引/类型名称/文档id |
| POST | localhost:9200/索引/类型名称/文档id/_search |
- 所有的命令都是使用 restful 风格来操作
