KMP算法、AC自动机算法的原理介绍以及Python实现
KMP算法
要弄懂AC自动机算法,首先弄清楚KMP算法。
这篇文章讲的很好:
http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html
结合这篇文章,我说下我的理解
比如如下查找,上面是原始串,下面是搜索串

要从原始串中查找是否出现搜索串,现在已经查到ABCDAB都匹配了,查找到D的时候,发现不匹配,那么下一步正常的想法可能就是从原始串的下一个字符开始重新匹配,也就是第5个B。
KMP的思想就是,要充分利用前面已经比较过的信息,所以就是要决定下一步原始串究竟是往后移动几个位置。
核心就是要先针对搜索串建立一张部分匹配表: ABCDABD
表的结构是搜索到每个位置时,对应的部分匹配值,那么对应的部分匹配值是怎么算的呢?
比如搜索到ABCDABD即第7个位置D的时候,部分匹配值就是2,这个部分匹配值就是从起始A到最后一个匹配位置B这个子串的最长的前缀和后缀的公共长度
因为前缀AB=后缀AB,所以部分匹配值就是2
再比如ABCDXYABCD,那么部分匹配值就是4
再比如ABCD,那么部分匹配值就是0
那么最后匹配到搜索串每个位置(第一个不匹配位置)向后移动的位数的计算公式是:
移动位数=已匹配的字符数-对应的部分匹配值其实可以这么理解:
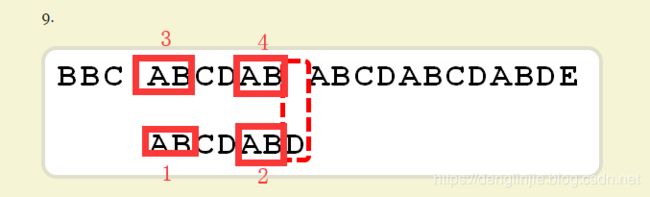
基于搜索串搜索到D位置时,部分匹配值是2,即前缀AB=后缀AB, 又因为,ABCDAB和原始串中的ABCDAB匹配, 所以:
2AB=1AB, 2AB=4AB, 所以1AB=4AB, 所以下一步可以直接移动到如下图: 即向后移动4位(6-2),这之前的都不可能和搜索串匹配,所以不用再比较

并且此时,1AB=4AB了,所以可以直接从两者的下一个字符开始继续匹配了。
所以总结下KMP算法的思路:
a、针对搜索串建立一个部分匹配表,其实可以直接建立一个移动位数表
b、开始搜索,一旦搜索到某个位置时不匹配时,查表得出搜索串的下一个匹配位置AC自动机算法
AC自动机其实就是在Trie字典树的基础上,加了类似于KMP算法的next数组
它包含两个操作:
a、将所有的模式串构建成Trie树
b、在Trie树上构建失败指针,就相当于KMP算法中失效函数next数组
假设现在有这一个Trie树: 模式串有[abcd, bcd, c] 三个
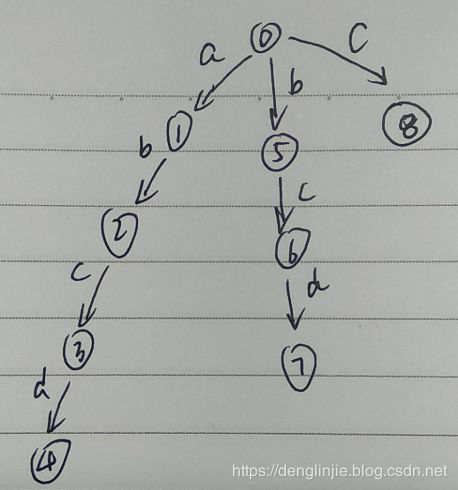
现在要查找的搜索串是efabcgh, 目标是从这个搜索串中查找所有含有的模式串,很显然头部ef都不匹配, 所以从a开始匹配,b也匹配,c也匹配,但是继续往下查找到g时,发现d != g, 那么接下来,可能就是正常的做法就是从搜索串中a的下一个字符b开始继续从Trie的根节点开始查找。
AC自动机引入了失败指针,即此时也可以利用之前已经比较过的串,通过失败指针,当匹配失败的时候,指向下一步跳到的比较位置。
肉眼看失败指针查找方式:
找搜索串从起始到当前失败的位置这个子串的后缀与所有模式串前缀匹配的最长的那个。比如efabcgh搜索串,当前搜索到g的时候,发现失败,即在状态3的时候失败了,abc是匹配的,那么就找abc的后缀与所有的模式串[abcd, bcd, c]前缀匹配的最长的那个的, abc的后缀有[c,bc], 很显然bc后缀与模式串bcd的前缀bc一致,而且是最长的那个,所以下一步就从Trie树的bcd中的c的位置开始继续找,那么节点3的失败指针就是节点6。
失败指针的递归思路:
上面是我们肉眼直接看出来的失败指针,实际在代码中找失败指针的时候其实是一个递归的过程,是基于父节点的失败指针来查找子节点的失败指针,比如当前我们要找3的失败指针,首先3的父节点2的失败指针是, 用上面同样的方式,我们知道是5, 那么这就是递归中已知的第n-1步的结果。 那么如果父节点的失败指针5在输入c字符(注意这里的c跟2到3之间的字符是一致的)后能找到一个子节点,那么这个子节点就是3的失败指针。 如果字符不匹配,则继续找父节点2的失败指针5的失败指针。通过这种方式其实就是找到的搜索串的后缀和所有模式串的前缀的公共长度最长的节点。
所以总结下AC自动机的思路: 具体的逻辑可参考下面的代码
a、构建Trie树
b、构建失败指针
c、开始查找:
循环开始
如果从Trie树中找到了匹配,那么Trie树去向子节点,并且搜索串后移
如果没有找到匹配,并且此时在根节点,那么搜索串后移,此时会重新从根节点开始查找
如果没有找到匹配,并且此时不在根节点,那么就去该节点的失败指针
回到循环开始
我实现的AC自动机算法:
#-*- coding:utf8 -*-
import time
import pdb
import sys
from collections import defaultdict
class Node:
def __init__(self):
self.patterns = []
self.children = {} #key是一个word,value是下一个Node
self.fail_node = None
class AC_Automation:
def __init__(self, patterns):
self.root = Node() #Trie树的根节点
self.fail_node = {} #存每个节点的失败指针
for pattern in patterns:
self.add_pattern(pattern)
self.build_fail()
def add_pattern(self, pattern):
curr_node = self.root
for word in pattern:
if word not in curr_node.children:
child_node = Node()
curr_node.children[word] = child_node
curr_node = curr_node.children[word]
curr_node.patterns.append(pattern)
#BFS遍历求每个节点的失败指针
def build_fail(self):
self.root.fail_node = self.root
node_queue = []
#深度为1的节点的失败指针都是root
for word in self.root.children:
child = self.root.children[word]
child.fail_node = self.root
node_queue.append(child)
index = 0
while node_queue:
print index
index += 1
node = node_queue.pop(0)
for word in node.children:
child_node = node.children[word]
node_queue.append(child_node) #子孩子入队
# 递归式:fail(child) = goto(fail(father), ch)
# 基于父节点的失败指针,递推子节点的失败指针。父节点到子节点之间的字符是ch,找到父节点的失败指针后,需要看该指针有没有子节点ch, 如果有,那子节点ch就是child的失败指针,否则,继续找father的失败指针
v = node.fail_node #先取父节点的失败指针
while v != self.root and word not in v.children:
v = v.fail_node
fail_node = v.children.get(word, self.root)
child_node.fail_node = fail_node
def search_pattern(self, text):
curr_node = self.root
patterns = []
index = 0
curr_node = self.root
while index < len(text):
print index
word = text[index]
if word not in curr_node.children:
if curr_node == self.root:
index += 1
else:
curr_node = curr_node.fail_node
else:
index += 1
curr_node = curr_node.children[word]
patterns.extend(curr_node.patterns)
#可能字符串刚匹配完的时候,恰好找到了最后,比如一个分支是def,另外有一个分支ef, 那么匹配字符串def会匹配成功,此时应该继续跳失败节点才能把ef匹配成功
while curr_node != self.root:
curr_node = curr_node.fail_node
patterns.extend(curr_node.patterns)
return patterns
if __name__ == '__main__':
patterns = ['abc', 'ab', 'def', 'acg', 'cd', 'bc', 'bcd', 'ef', 'de', 'efg', 'fg', 'ghk', 'gk', 'hk', 'a']
ac = AC_Automation(patterns)
print ac.search_pattern('abcdefghk') #输出:['a', 'ab', 'abc', 'bc', 'bcd', 'cd', 'de', 'def', 'ef', 'efg', 'fg', 'ghk', 'hk']我们知道,AC自动机有一个很大的问题是,消耗的内存特别大,当我们要做的中文字符串的查找时,如何选择最小的字符单位,会直接影响查询速度和占用内存,比如:
建造Trie树的时间、构建失败指针的时间,占用的内存等下面是我做的测试:
我的模式串总共10w个,每个串都不长,平均差不多4个汉字
搜索串的长度为489个汉字
a、以utf8为最小单位,即树的每个节点是utf8的,所以一个汉字会被拆分成两个节点,得到的结果
| 消耗内存 |
1567M |
| 建树耗时 |
18522ms |
| 建失败指针耗时 |
71630ms |
| 查询耗时 |
5ms |
| 查询次数 |
fail:365,search:1300 |
b、以unicode为最小单位,即树的每个节点都是unicode的,所以一个汉字占一个节点,得到的结果
| 消耗内存 |
636M |
| 建树耗时 |
6928ms |
| 建失败指针耗时 |
26671ms |
| 查询耗时 |
5ms |
| 查询次数 |
fail:313,search:500 |
c、以分词为单位,即树的每个节点都是一个分词的结果,所以是一个词占一个节点,得到的结果
| 消耗内存 |
362M |
| 建树耗时 |
3586ms |
| 建失败指针耗时 |
11645ms |
| 查询耗时 |
分词15ms、查询2ms |
| 查询次数 |
fail:157、search:261 |
总结:
可以看到,选择的单节点的字节数越多,消耗的内存越少,并且建树、检索的时间的时间也越短。
正常情况下可能会选择用分词的方式,这种方式的确查询效率很高,但是分词本身是需要消耗时间的,所以如果为了降低内存消耗,可以牺牲掉查询速度。如果为了提高查询速度,那么选择unicode作为单节点是比较合理的方式。
参考地址:
https://blog.csdn.net/bestsort/article/details/82947639
https://blog.csdn.net/Big_Head_/article/details/80144495
https://www.cnblogs.com/cmmdc/p/7337611.html
https://www.jianshu.com/p/93900f46068c
http://www.hyuuhit.com/2018/06/12/Aho%E2%80%93Corasick-Algorithm/
https://zhuanlan.zhihu.com/p/52477064
https://www.cnblogs.com/super-zhang-828/p/6193684.html