navicat导入专题
一、背景介绍(可以忽略)
就我而言,选择navicat的一个重要原因就是它的导入导出功能,尤其是dbf格式数据。目前各种数据库连接工具很少有支持dbf的。之前的做法一直是采用excel作为中转工具,通过另存为的方式,来改变实现excel和dbf的切换。但是这种方式不是没有问题,当存在大量长短不一的字符型字段时,这种转换很容易出错。另外,excel2003只能容纳65535条记录,这也是一个限制。
另外navicat支持连接常用的各种数据库,一个软件,各种数据数据库统统搞定,这对于经常做数据迁移的人是多么可爱的事。为了能够放心的使用这一神器,测试是必不可少,任何软件都不是完美的,只有知道他的特长,使用才能得心应手。
二、navicat导入相关参数
测验目的:
一、数据的正确性。
二、导入导出速度。
测试原材料:
表一:60万条记录(7个字段;共25.2M;不含中文、空字段、特殊字符)
表二:5万条记录(43个字段;共55.8M;含中文、空字段、特殊字段)
软件版本:
navicat premium 11.2.7 64位版
mysql 5.7 64位版
sqlserver 2008 r2 64位版
oracle 11g 64位版
软件环境:
所有数据库都采用本地连接,所有数据库都运行在同一块ssd硬盘上,所有数据软件均采用默认安装配置,未进行调优。
三、navicat导入dbf
1、操作步骤
点击目标数据库(表空间)——对象—-导入向导——dbase文件(*.dbf)——选择文件及编码方式(dbf默认为简体中文,应选936GBK)——输入表名——确定字段类型及大小——选择导入模式为添加——开始
2、测试结果
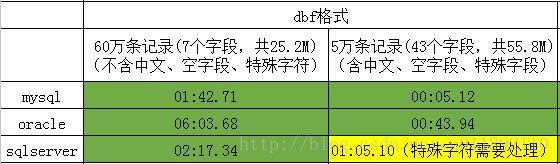
3、总结体会
因为navicat导入sqlserver其本质是使用insert语句插入数据数据,如果数据中含有单引号或者双引号等特殊字符,会导致insert语句结构错误,而导致该条语句无法运行。在导入数据过程如果出现数据内容,则表示导入出错了。
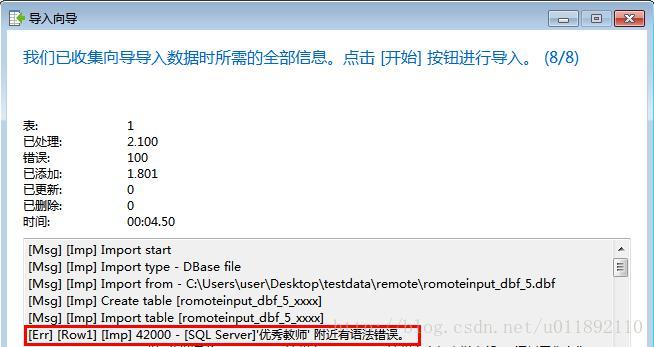
在分析错误原因是由于单引号和双引号造成的,编写prg程序,遍历行列将双引号和单引号替换为空。代码如下:
USE test.DBF
FOR i=1 TO FCOUNT()
_field=FIELD(i)
?_field
replace "&_field." WITH CHRTRAN(&_field,'"','') , "&_field." WITH CHRTRAN(&_field,"'","") all
ENDFOR 四、navicat导入txt
1、操作步骤
点击目标数据库(表空间)——对象—-导入向导——文本文件(*.txt)——选择文件及编码方式(txt默认为简体中文,应选936GBK;如果保存的时选择编码类型为uft-8,则选65501utf-8)——选择记录分隔符、字段分隔符、文本限定符——选择字符名和数据开始的行数(一般为默认)——输入表名——确定字段类型及大小——选择导入模式为添加——开始
2、测试结果
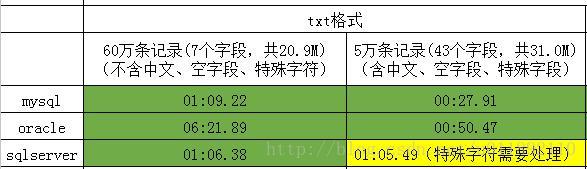
3、总结体会
使用txt文件导入导出,最重要的就是选择三种符号(记录分隔符、字段分隔符、文本限定符),三种符号在导出和导入的时候应该保持一致。符号的选择要根据字符内容而定,例如:文本限定符不能是在字段文本内容里出现过的符号。文本限定符可以为空,但如果字段里有大量的空值的时候就不要将文本限定符设置为空。
txt类型文件,如果数据本身含有单引号和双引号,在导入sqlserver时同样会出错,解决办法使用其他字符为文本限定符号(例如~),然后使用查找替换将单引号和双引号替换为空。
五、navicat导入xls
1、操作步骤
点击目标数据库(表空间)——对象—-导入向导——excel数据(*.xls)——选择excel文件及表——选择字符名和数据开始的行数,一般为默认——输入表名——确定字段类型及大小——选择导入模式为添加——开始
2、测试结果
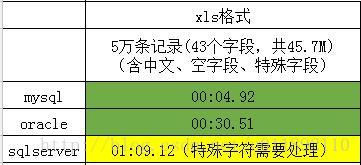
3、总结体会
目前使用navicat 11.2.7系类,只能支持excel2003。最新的navicat12系类,可以支持excel2007,但是目前官方版本存在中文乱码情况,所以只做了excel2003版本的测试,等navicat12系类成熟且有破解版的时候,再更新测试。
xls类型文件,如果数据本身含有单引号和双引号,在导入sqlserver时同样会出错,解决办法使用查找替换将单引号和双引号替换为空。
六、navicat导入sql文件
1、操作步骤
右击目标数据库(表空间)——运行sql文件—-选择文件及编码方式——开始
2、测试结果
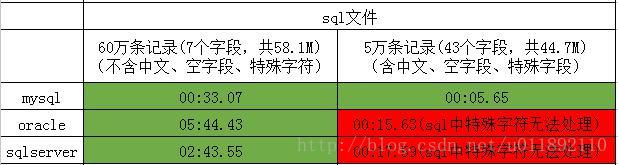
3、总结体会
目前测试用的sql文件是通过navicat导出的,navicat在导出的时候没有对特殊字符进行转义,所以如果数据中存在单引号或双引号等特殊字符,在sql文件中是不能够处理的,数据也是失效了。