chromium是如何实现http解析的
上一节我们介绍了Chrome对于DNS协议的解析,今天我们继续介绍一个更为大家所熟知的协议,HTTP协议。
HTTP协议是一种很常见的协议,在chromium网络库中,对HTTP的解析主要是分为两部分,一部分是去缓存数据的获取,另外一部分则是重新加载网络资源。简单点说就是当我们在浏览器中输入 http://www.bytedance.net 的时候,优先去浏览器中的缓存数据查找是否存在相应的资源,如果存在则直接加在缓存中的数据,否则就需要建立TCP连接,进行网络数据的加载。对于刚才举的那个例子,要看在chrome中是否已经有缓存数据存在,只需要在浏览器中输入 chrome://cache/ 即可查看:
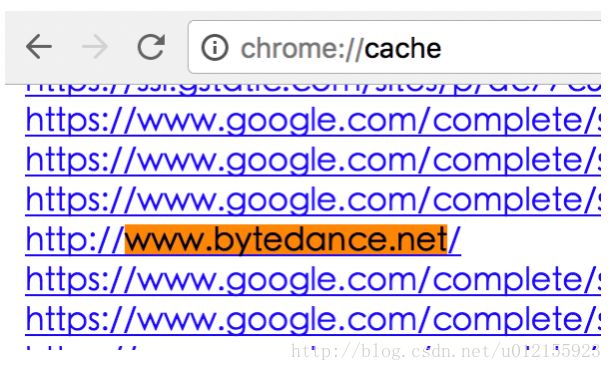
和DNS一样,在net网络库中的HTTP源码文件多达上百个,一个个去看效率低并且也学不到什么有用的东西,还是像上次一样先找出其主流程,分析关键函数,了解整个过程的来龙去脉,最后才是逐个击破。
可以把HTTP的资源加载看作是浏览器解析一个用户指定的URL的过程(实际上URL不仅仅包含http,还包含https、ftp等等协议),而整个chrome的net库对外的一个大的接口函数就是UrlRequest,顾名思义,这个函数代表一个URL请求,net库就是要根据这个请求,快速准确地返回相应的数据,这个函数的文件位于 /net/url_request。 当我们在浏览器中输入 http://www.bytedance.net 时,通过URL解析,得到其scheme是http,这个时候就会调用到HTTP模块进行相应的处理,关于这一部分的详细过程,后续我会再找机会详细分析URL的解析过程。
当HTTP模块收到这个URL解析请求时,就像我们最先提到的那样,会先去调用HttpCache::Transaction::Start 这个方法,这个函数的部分代码如下:
int HttpCache::Transaction::Start(const HttpRequestInfo* request,
const CompletionCallback& callback,
const BoundNetLog& net_log) {
…
next_state_ = STATE_GET_BACKEND;
int rv = DoLoop(OK);
// Setting this here allows us to check for the existence of a callback_ to
// determine if we are still inside Start.
if (rv == ERR_IO_PENDING) {
callback_ = tracked_objects::ScopedTracker::TrackCallback(
FROM_HERE_WITH_EXPLICIT_FUNCTION(
"422516 HttpCache::Transaction::Start"),
callback);
}
return rv;
}可以看到这部分代码主要是启动了一个状态机,并且制定了初始状态STATE_GET_BACKEND 和 结束状态 ERR_IO_PENDING。关于这个结束状态,是为了防止状态机阻塞后不能及时结束而导致程序无法继续执行,因此当状态码为ERR_IO_PENDING,则直接跳出该状态机循环。启动这个状态机是为了从缓存中获取我们想要的数据,这部分的流程分支有很多,光状态机的state就有40种之多,作者也将一些流程分支都整理了出来(这里只贴了一部分,想看完整版的可以去http_cache_transaction.cc 这个文件中看)

大概看了下,好家伙,有14种状态,这还只是作者列出来的,一些异常情况还未考虑进来,但是从根本上来看,大致可以分为两种情况:
情况一就是Cached entry,这部分状态就代表我们从缓存数据中找到了想要的资源,直接拿过来用就可以了,不需要再去进行网络请求。
情况二就是Not-cached entry,这部分状态代表我们并没有从缓存中找到想要的数据,因此我们需要调用 SendRequest 来实现网络加载资源的请求,如果调用成功,即我们通过网络请求获取了想要的资源,除了将资源返回给用户之外,还需要调用CacheWriteData 来更新缓存中的数据,这样等下次访问时,就可以直接在cache命中。
再来看一下读取缓存数据的流程:
首先是状态变更:GetBackend* -> InitEntry -> OpenEntry* -> AddToEntry* -> CacheReadResponse* -> CacheDispatchValidation
用文字解读一下就是,初始化Entry,打开这个Entry,根据URL获取Entry数据,读取数据并且构造响应消息体。

这里的cache_key_实际上就是URL,通过这个值便可以唯一检索到缓存中的数据。
以上是HttpCache::Transaction状态机的实现概述,简单点说就是以URL为key值在缓存中查找数据,如果匹配成功则直接返回,如果不成功则需要发送网络请求,这就涉及到我们接下来要介绍的HttpNetworkTransaction了。
当我们需要调用网络加载所需资源时,就要把状态机状态置为STATE_SEND_REQUEST,此时就会调用到下面这个函数:
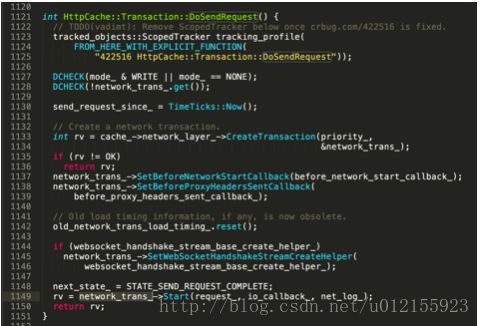
我们注意到这个函数最后是调用了network_trans中的Start方法,此时便会调用到
int HttpNetworkTransaction::Start 这个函数里来,同样的,在该函数中也新启动了一个状态机,并且将初始状态设置为 STATE_NOTIFY_BEFORE_CREATE_STREAM :

NetworkTransaction层的状态机状态码有以下几种,比之前的cache层要少很多

顺着这个状态码整理NetworkTransaction层的大致流程如下:
DoCreateStream —> DoInitStream —> DoGenerateProxyAuthToken —> DoGenerateServerAuthToken —> DoInitRequestBody —> DoBuildRequest —> DoSendRequest —> DoReadHeaders —> DoReadBody
用文字解释一下就是:创建strem,初始化参数,建立连接,初始化请求主体,发送请求,并且读取相应的返回信息,最后根据需要处理连接。
这里要提一下的是DoSendRequest方法,它实际上调用的是HttpBasicStream::SendRequest的方法,而HttpBasicStream则调用HttpStreamParser中的SendRequest方法来实现,其大致思路就是创建连接,构造消息体,调用tcp socket进行消息头和数据的传输,最终将结果返回给NetworkTransaction层,有兴趣的同学可以去看一下代码的具体实现,这部分代码位于 http_stream_parser.cc 文件中。
介绍完NetworkTransaction层的网络传输层以后,还会做一个动作,那就是将得到的数据写入到cache中去,这个我们在之前已经提到过,这里就不再赘述了。
关于HTTP的解析就先介绍到这里,简单总结一下,对于一个URL请求,当解析为HTTP请求时,先去cache层中查找,如果找到了,则构造数据并返回;如果没找到,再去调用network层发起网络请求,通过调用底层的tcp socket实现数据的传输,当完成加载以后,再将其写入到cache层中。当然,这只是最常见的一种流程,关于HTTP还有许多需要探索和学习的地方,这些都留在以后的章节吧。