LSTM神经网络的详细推导及C++实现
LSTM隐层神经元结构:
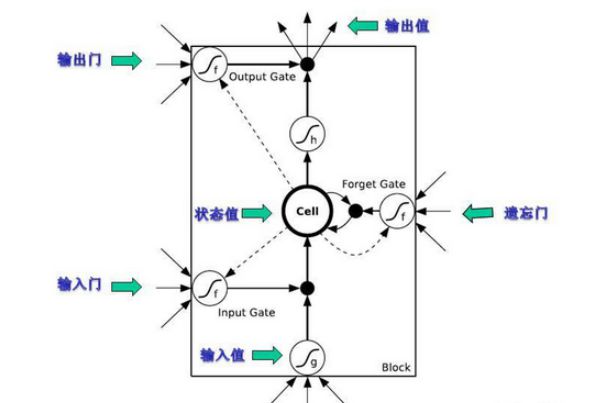
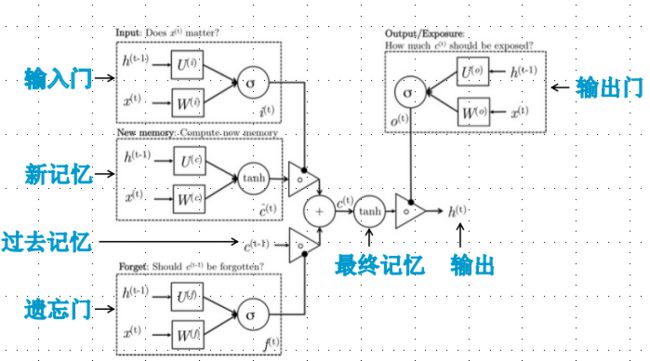
LSTM隐层神经元详细结构:




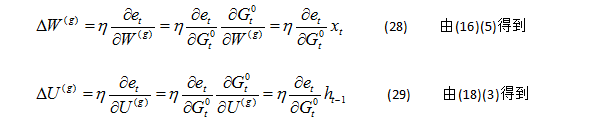
//让程序自己学会是否需要进位,从而学会加法
#include "iostream"
#include "math.h"
#include "stdlib.h"
#include "time.h"
#include "vector"
#include "assert.h"
using namespace std;
#define innode 2 //输入结点数,将输入2个加数
#define hidenode 26 //隐藏结点数,存储“携带位”
#define outnode 1 //输出结点数,将输出一个预测数字
#define alpha 0.1 //学习速率
#define binary_dim 8 //二进制数的最大长度
#define randval(high) ( (double)rand() / RAND_MAX * high )
#define uniform_plus_minus_one ( (double)( 2.0 * rand() ) / ((double)RAND_MAX + 1.0) - 1.0 ) //均匀随机分布
int largest_number = ( pow(2, binary_dim) ); //跟二进制最大长度对应的可以表示的最大十进制数
//激活函数
double sigmoid(double x)
{
return 1.0 / (1.0 + exp(-x));
}
//激活函数的导数,y为激活函数值
double dsigmoid(double y)
{
return y * (1.0 - y);
}
//tanh的导数,y为tanh值
double dtanh(double y)
{
y = tanh(y);
return 1.0 - y * y;
}
//将一个10进制整数转换为2进制数
void int2binary(int n, int *arr)
{
int i = 0;
while(n)
{
arr[i++] = n % 2;
n /= 2;
}
while(i < binary_dim)
arr[i++] = 0;
}
class RNN
{
public:
RNN();
virtual ~RNN();
void train();
public:
double W_I[innode][hidenode]; //连接输入与隐含层单元中输入门的权值矩阵
double U_I[hidenode][hidenode]; //连接上一隐层输出与本隐含层单元中输入门的权值矩阵
double W_F[innode][hidenode]; //连接输入与隐含层单元中遗忘门的权值矩阵
double U_F[hidenode][hidenode]; //连接上一隐含层与本隐含层单元中遗忘门的权值矩阵
double W_O[innode][hidenode]; //连接输入与隐含层单元中遗忘门的权值矩阵
double U_O[hidenode][hidenode]; //连接上一隐含层与现在时刻的隐含层的权值矩阵
double W_G[innode][hidenode]; //用于产生新记忆的权值矩阵
double U_G[hidenode][hidenode]; //用于产生新记忆的权值矩阵
double W_out[hidenode][outnode]; //连接隐层与输出层的权值矩阵
double *x; //layer 0 输出值,由输入向量直接设定
//double *layer_1; //layer 1 输出值
double *y; //layer 2 输出值
};
void winit(double w[], int n) //权值初始化
{
for(int i=0; i//均匀随机分布
}
RNN::RNN()
{
x = new double[innode];
y = new double[outnode];
winit((double*)W_I, innode * hidenode);
winit((double*)U_I, hidenode * hidenode);
winit((double*)W_F, innode * hidenode);
winit((double*)U_F, hidenode * hidenode);
winit((double*)W_O, innode * hidenode);
winit((double*)U_O, hidenode * hidenode);
winit((double*)W_G, innode * hidenode);
winit((double*)U_G, hidenode * hidenode);
winit((double*)W_out, hidenode * outnode);
}
RNN::~RNN()
{
delete x;
delete y;
}
void RNN::train()
{
int epoch, i, j, k, m, p;
vector<double*> I_vector; //输入门
vector<double*> F_vector; //遗忘门
vector<double*> O_vector; //输出门
vector<double*> G_vector; //新记忆
vector<double*> S_vector; //状态值
vector<double*> h_vector; //输出值
vector<double> y_delta; //保存误差关于输出层的偏导
for(epoch=0; epoch<11000; epoch++) //训练次数
{
double e = 0.0; //误差
int predict[binary_dim]; //保存每次生成的预测值
memset(predict, 0, sizeof(predict));
int a_int = (int)randval(largest_number/2.0); //随机生成一个加数 a
int a[binary_dim];
int2binary(a_int, a); //转为二进制数
int b_int = (int)randval(largest_number/2.0); //随机生成另一个加数 b
int b[binary_dim];
int2binary(b_int, b); //转为二进制数
int c_int = a_int + b_int; //真实的和 c
int c[binary_dim];
int2binary(c_int, c); //转为二进制数
//在0时刻是没有之前的隐含层的,所以初始化一个全为0的
double *S = new double[hidenode]; //状态值
double *h = new double[hidenode]; //输出值
for(i=0; i0;
h[i] = 0;
}
S_vector.push_back(S);
h_vector.push_back(h);
//正向传播
for(p=0; p//循环遍历二进制数组,从最低位开始
{
x[0] = a[p];
x[1] = b[p];
double t = (double)c[p]; //实际值
double *in_gate = new double[hidenode]; //输入门
double *out_gate = new double[hidenode]; //输出门
double *forget_gate = new double[hidenode]; //遗忘门
double *g_gate = new double[hidenode]; //新记忆
double *state = new double[hidenode]; //状态值
double *h = new double[hidenode]; //隐层输出值
for(j=0; j//输入层转播到隐层
double inGate = 0.0;
double outGate = 0.0;
double forgetGate = 0.0;
double gGate = 0.0;
double s = 0.0;
for(m=0; mdouble *h_pre = h_vector.back();
double *state_pre = S_vector.back();
for(m=0; mdouble s_pre = state_pre[j];
state[j] = forget_gate[j] * s_pre + g_gate[j] * in_gate[j];
h[j] = in_gate[j] * tanh(state[j]);
}
for(k=0; k//隐藏层传播到输出层
double out = 0.0;
for(j=0; j//输出层各单元输出
}
predict[p] = (int)floor(y[0] + 0.5); //记录预测值
//保存隐藏层,以便下次计算
I_vector.push_back(in_gate);
F_vector.push_back(forget_gate);
O_vector.push_back(out_gate);
S_vector.push_back(state);
G_vector.push_back(g_gate);
h_vector.push_back(h);
//保存标准误差关于输出层的偏导
y_delta.push_back( (t - y[0]) * dsigmoid(y[0]) );
e += fabs(t - y[0]); //误差
}
//误差反向传播
//隐含层偏差,通过当前之后一个时间点的隐含层误差和当前输出层的误差计算
double h_delta[hidenode];
double *O_delta = new double[hidenode];
double *I_delta = new double[hidenode];
double *F_delta = new double[hidenode];
double *G_delta = new double[hidenode];
double *state_delta = new double[hidenode];
//当前时间之后的一个隐藏层误差
double *O_future_delta = new double[hidenode];
double *I_future_delta = new double[hidenode];
double *F_future_delta = new double[hidenode];
double *G_future_delta = new double[hidenode];
double *state_future_delta = new double[hidenode];
double *forget_gate_future = new double[hidenode];
for(j=0; j0;
I_future_delta[j] = 0;
F_future_delta[j] = 0;
G_future_delta[j] = 0;
state_future_delta[j] = 0;
forget_gate_future[j] = 0;
}
for(p=binary_dim-1; p>=0 ; p--)
{
x[0] = a[p];
x[1] = b[p];
//当前隐藏层
double *in_gate = I_vector[p]; //输入门
double *out_gate = O_vector[p]; //输出门
double *forget_gate = F_vector[p]; //遗忘门
double *g_gate = G_vector[p]; //新记忆
double *state = S_vector[p+1]; //状态值
double *h = h_vector[p+1]; //隐层输出值
//前一个隐藏层
double *h_pre = h_vector[p];
double *state_pre = S_vector[p];
for(k=0; k//对于网络中每个输出单元,更新权值
{
//更新隐含层和输出层之间的连接权
for(j=0; j//对于网络中每个隐藏单元,计算误差项,并更新权值
for(j=0; j0.0;
for(k=0; kfor(k=0; k0.0;
I_delta[j] = 0.0;
F_delta[j] = 0.0;
G_delta[j] = 0.0;
state_delta[j] = 0.0;
//隐含层的校正误差
O_delta[j] = h_delta[j] * tanh(state[j]) * dsigmoid(out_gate[j]);
state_delta[j] = h_delta[j] * out_gate[j] * dtanh(state[j]) +
state_future_delta[j] * forget_gate_future[j];
F_delta[j] = state_delta[j] * state_pre[j] * dsigmoid(forget_gate[j]);
I_delta[j] = state_delta[j] * g_gate[j] * dsigmoid(in_gate[j]);
G_delta[j] = state_delta[j] * in_gate[j] * dsigmoid(g_gate[j]);
//更新前一个隐含层和现在隐含层之间的权值
for(k=0; k//更新输入层和隐含层之间的连接权
for(k=0; kif(p == binary_dim-1)
{
delete O_future_delta;
delete F_future_delta;
delete I_future_delta;
delete G_future_delta;
delete state_future_delta;
delete forget_gate_future;
}
O_future_delta = O_delta;
F_future_delta = F_delta;
I_future_delta = I_delta;
G_future_delta = G_delta;
state_future_delta = state_delta;
forget_gate_future = forget_gate;
}
delete O_future_delta;
delete F_future_delta;
delete I_future_delta;
delete G_future_delta;
delete state_future_delta;
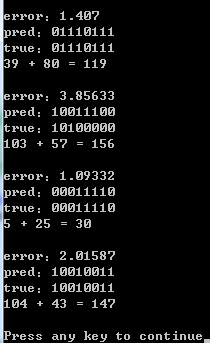
if(epoch % 1000 == 0)
{
cout << "error:" << e << endl;
cout << "pred:" ;
for(k=binary_dim-1; k>=0; k--)
cout << predict[k];
cout << endl;
cout << "true:" ;
for(k=binary_dim-1; k>=0; k--)
cout << c[k];
cout << endl;
int out = 0;
for(k=binary_dim-1; k>=0; k--)
out += predict[k] * pow(2, k);
cout << a_int << " + " << b_int << " = " << out << endl << endl;
}
for(i=0; idelete I_vector[i];
for(i=0; idelete F_vector[i];
for(i=0; idelete O_vector[i];
for(i=0; idelete G_vector[i];
for(i=0; idelete S_vector[i];
for(i=0; idelete h_vector[i];
I_vector.clear();
F_vector.clear();
O_vector.clear();
G_vector.clear();
S_vector.clear();
h_vector.clear();
y_delta.clear();
}
}
int main()
{
srand(time(NULL));
RNN rnn;
rnn.train();
return 0;
} 
参考:
http://lib.csdn.net/article/deeplearning/45380
http://www.open-open.com/lib/view/open1440843534638.html