Python计算数据相关系数(person、Kendall、spearman)
pandas中DataFrame对象corr()方法的用法,该方法用来计算DataFrame对象中所有列之间的相关系数(包括pearson相关系数、Kendall Tau相关系数和spearman秩相关)。
pandas相关系数-DataFrame.corr()参数详解
DataFrame.corr(method='pearson', min_periods=1)
参数说明:
method:可选值为{‘pearson’, ‘kendall’, ‘spearman’}
pearson:Pearson相关系数来衡量两个数据集合是否在一条线上面,即针对线性数据的相关系数计算,针对非线性数据便会有误差。
kendall:用于反映分类变量相关性的指标,即针对无序序列的相关系数,非正太分布的数据
spearman:非线性的,非正太分析的数据的相关系数min_periods:样本最少的数据量
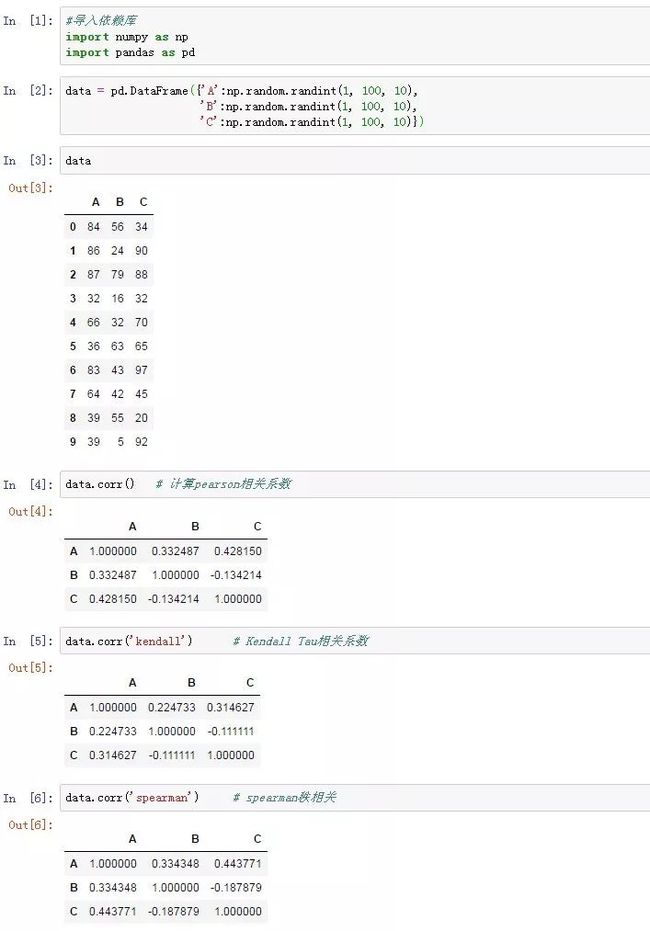
计算积距pearson相关系数,连续性变量才可采用;计算Spearman秩相关系数,适合于定序变量或不满足正态分布假设的等间隔数据; 计算Kendall秩相关系数,适合于定序变量或不满足正态分布假设的等间隔数据。
计算相关系数:当资料不服从双变量正态分布或总体分布未知,或原始数据用等级表示时,宜用 spearman或kendall相关。
Pearson 相关复选项积差相关 计算连续变量或是等间距测度的变量间的相关分析。
Kendall复选项 等级相关 计算分类变量间的秩相关,适用于合并等级资料
Spearman复选项 等级相关 计算斯皮尔曼相关,适用于连续等级资料
注:
1、若非等间距测度的连续变量 因为分布不明-可用等级相关/也可用Pearson 相关,对于完全等级离散变量必用等级相关
2、当资料不服从双变量正态分布或总体分布型未知或原始数据是用等级表示时,宜用 Spearman 或 Kendall相关。
3、 若不恰当用了Kendall 等级相关分析则可能得出相关系数偏小的结论。则若不恰当使用,可能得相关系数偏小或偏大结论而考察不到不同变量间存在的密切关系。对一般情况默认数据服从正态分布的,故用Pearson分析方法。
两个连续变量间呈线性相关时,使用Pearson积差相关系数,用来衡量两个数据集合是否在一条线上面,它用来衡量定距变量间的线性关系。(前提:作散点图主观判断下先)。按照高中数学水平来理解, 它很简单, 可以看做将两组数据首先做Z分数处理之后, 然后两组数据的乘积和除以样本数。
Spearman相关系数又称秩相关系数,是利用两变量的秩次大小作线性相关分析,对原始变量的分布不作要求,属于非参数统计方法,适用范围要广些。斯皮尔曼等级相关是根据等级资料研究两个变量间相关关系的方法。它是依据两列成对等级的各对等级数之差来进行计算的,所以又称为“等级差数法”
斯皮尔曼等级相关对数据条件的要求没有积差相关系数严格,只要两个变量的观测值是成对的等级评定资料,或者是由连续变量观测资料转化得到的等级资料,不论两个变量的总体分布形态、样本容量的大小如何,都可以用斯皮尔曼等级相关来进行研究
对于服从Pearson相关系数的数据亦可计算Spearman相关系数,但统计效能要低一些。Pearson相关系数的计算公式可以完全套用 Spearman相关系数计算公式,但公式中的x和y用相应的秩次代替即可。
Kendall's tau-b等级相关系数:用于反映分类变量相关性的指标,适用于两个分类变量均为有序分类的情况。对相关的有序变量进行非参数相关检验;取值范围在-1-1之间,此检验适合于正方形表格;肯德尔(Kendall)W系数又称和谐系数,是表示多列等级变量相关程度的一种方法。适用这种方法的数据资料一般是采用等级评定的方法收集的,即让K个评委(被试)评定N件事物,或1个评委(被试)先后K次评定N件事物。等级评定法每个评价者对N件事物排出一个等级顺序,最小的等级序数为1 ,最大的为N,若并列等级时,则平分共同应该占据的等级,如,平时所说的两个并列第一名,他们应该占据1,2名,所以它们的等级应是1.5,又如一个第一名,两个并列第二名,三个并列第三名,则它们对应的等级应该是1,2.5,2.5,5,5,5,这里2.5是2,3的平均,5是4,5,6的平均。
肯德尔(Kendall)U系数又称一致性系数,是表示多列等级变量相关程度的一种方法。该方法同样适用于让K个评委(被试)评定N件事物,或1个评委(被试)先后K次评定N件事物所得的数据资料,只不过评定时采用对偶评定的方法,即每一次评定都要将N个事物两两比较,评定结果如下表所示,表格中空白位(阴影部分可以不管)填入的数据为:若i比j好记1,若i比j差记0,两者相同则记0.5。一共将得到K张这样的表格,将这K张表格重叠起来,对应位置的数据累加起来作为最后进行计算的数据,这些数据记为γij。