spark-概念
本文长篇介绍了spark基本概念和spark Streaming 、spark sql 请仔细阅读,红色标注的是我认为比较重要的部分。
运行环境

基本概念
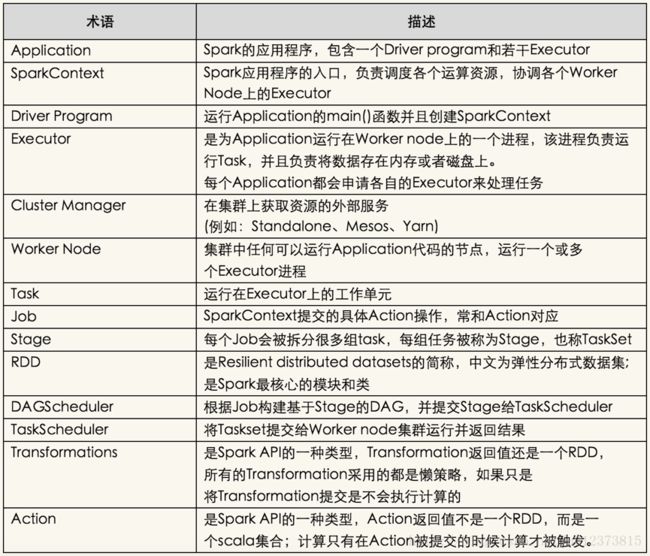
Spark生态圈
以Spark Core为核心,从HDFS、Amazon S3和HBase等持久层读取数据,以MESS、YARN和自身携带的Standalone为资源管理器调度Job完成Spark应用程序的计算。 这些应用程序可以来自于不同的组件,如Spark Shell/Spark Submit的批处理、Spark Streaming的实时处理应用、Spark SQL的即席查询、BlinkDB的权衡查询、MLlib/MLbase的机器学习、GraphX的图处理和SparkR的数学计算等等。
spark官方文档的翻译精读。基于1.6版本。
1. spark概述

2. Rdd 基本概念

Spark更适合于迭代运算比较多的ML和DM运算。因为在Spark里面,有RDD的概念。
RDD可以cache到内存中,那么每次对RDD数据集的操作之后的结果,都可以存放到内存中,下一个操作可以直接从内存中输入,省去了MapReduce大量的磁盘IO操作。这对于迭代运算比较常见的机器学习算法来说,效率提升比较大
• RDD(Resilient Distributed Dataset) 弹性分布数据集介绍
弹性分布式数据集(基于Matei的研究论文)或RDD是Spark框架中的核心概念。可以将RDD视作数据库中的一张表。其中可以保存任何类型的数据。Spark将数据存储在不同分区上的RDD之中。
RDD可以帮助重新安排计算并优化数据处理过程。
此外,它还具有容错性,因为RDD知道如何重新创建和重新计算数据集。
RDD是不可变的。你可以用变换(Transformation)修改RDD,但是这个变换所返回的是一个全新的RDD,而原有的RDD仍然保持不变。
RDD支持两种类型的操作:
• 变换(Transformation)
• 行动(Action)
变换:变换的返回值是一个新的RDD集合,而不是单个值。调用一个变换方法,不会有任何求值计算,它只获取一个RDD作为参数,然后返回一个新的RDD。变换函数包括:map,filter,flatMap,groupByKey,reduceByKey,aggregateByKey,pipe和coalesce。
行动:行动操作计算并返回一个新的值。当在一个RDD对象上调用行动函数时,会在这一时刻计算全部的数据处理查询并返回结果值。
行动操作包括:reduce,collect,count,first,take,countByKey以及foreach。
• 共享变量(Shared varialbes)
o 广播变量(Broadcast variables)
o 累加器(Accumulators)
2.1 并行集合

2.2.外部数据集

2.2.1 RDD操作

传递函数导spark集群
spark API很大程度上需要依靠在驱动程序里传递函数导集群上运行
- 匿名函数,可以在短代码中实现
- 全局单利对象的静态方法
这里需要传递包含方法的整个对象到每个work,而不是一个方法引用

2.2.2 RDD 持久化


2.3 共享变量


3. SprakStream基本概念


容错性:对于流式计算来说,容错性至关重要。首先我们要明确一下Spark中RDD的容错机制。每一个RDD都是一个不可变的分布式可重算的数据集,其记录着确定性的操作继承关系(lineage),所以只要输入数据是可容错的,那么任意一个RDD的分区(Partition)出错或不可用,都是可以利用原始输入数据通过转换操作而重新算出的。
对于Spark Streaming来说,其RDD的传承关系如下图所示,图中的每一个椭圆形表示一个RDD,椭圆形中的每个圆形代表一个RDD中的一个Partition,图中的每一列的多个RDD表示一个DStream(图中有三个DStream),而每一行最后一个RDD则表示每一个Batch Size所产生的中间结果RDD。我们可以看到图中的每一个RDD都是通过lineage相连接的,由于Spark Streaming输入数据可以来自于磁盘,例如HDFS(多份拷贝)或是来自于网络的数据流(Spark Streaming会将网络输入数据的每一个数据流拷贝两份到其他的机器)都能保证容错性,所以RDD中任意的Partition出错,都可以并行地在其他机器上将缺失的Partition计算出来。这个容错恢复方式比连续计算模型(如Storm)的效率更高。
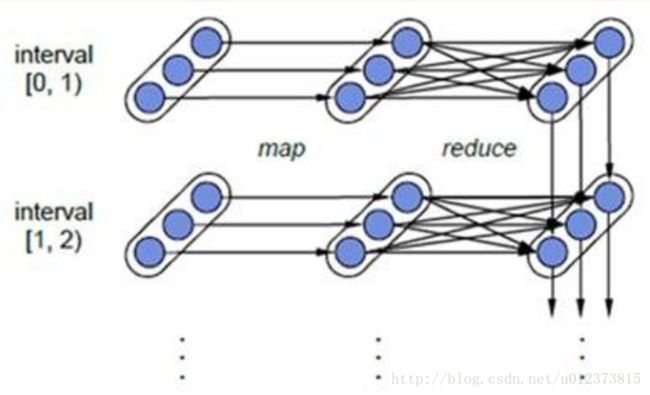
3.1 离散流DStream
此处介绍一个wordcount的小李子

通过spark引擎计算这些隐含的RDD算子,DStream操作隐藏了大部分的细节
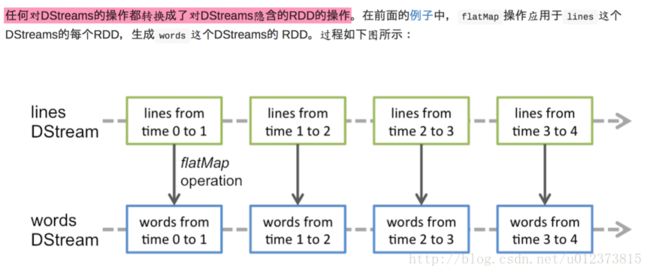
3.2 输入DStream和Receive

感悟:这就是为什么在kafka的那个小李子中,只会拿取数据而不处理,等到stop 任务的时候才处理,是因为我只是给他本地运行的一个核心,只有当任务停止的时候核心才会从接受消息的receiver中空余出来进行数据处理。
3.2.1 基本源

针对于第三点也就是说不能持续的写此文件。持续写,后来写入的数据不被处理,这个功能测试使用,比较鸡肋。不太管用。可以把每个文件当作一个RDD因为RDD不可改变。所以这个文件改变了,也不会生成新的RDD 所以改变新加的数据,不会被处理。
3.2.2 高级源

这些高级源在spark-shell中不能被使用。

3.3 DStream 的转换(transformation)

union 不去重


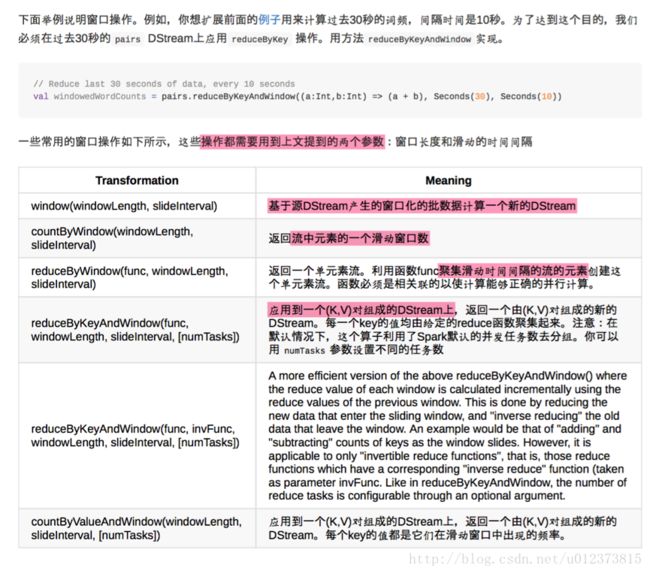
3.4 DStream的输出

3.4.1 foreachRDD



3.5 缓存和持久化



3.6 Streaming配置、升级和监控



3.7 性能调优
提高sparkStreaming应用程序的性能,需要考虑两件事
高效的利用集群资源减少批数据的处理时间
设置正确的批处理容量(size)使数据的处理速度能跟上数据的接收速度
减少批数据的执行时间
内存调优
3.7.1 减少批处理时间


此处的粗粒度指的是什么?
Mesos 是一个集群资源管理器,粗粒度和细粒度是两种管理模式,粗粒度是直接把人物所需资源准备好,然后执行任务。细粒度是拿到任务对任务按照优先级排序。然后再给资源安优先级执行任务。
3.7.2 设置正确的批处理容量

3.7.3 内存调优

3.8 容错语义


4 .Spark Sql
4.1 SQL
Spark SQL的一种用法是直接执行SQL查询语句,你可使用最基本的SQL语法,也可以选择HiveQL语法。Spark SQL可以从已有的Hive中读取数据。更详细的请参考Hive Tables 这一节。如果用其他编程语言运行SQL,Spark SQL将以DataFrame返回结果。你还可以通过命令行command-line 或者 JDBC/ODBC 使用Spark SQL。
4.2 DataFrames
DataFrame是一种分布式数据集合,每一条数据都由几个命名字段组成。概念上来说,她和关系型数据库的表 或者 R和Python中的data frame等价,只不过在底层,DataFrame采用了更多优化。DataFrame可以从很多数据源(sources)加载数据并构造得到,如:结构化数据文件,Hive中的表,外部数据库,或者已有的RDD。
DataFrame API支持Scala, Java, Python, and R。
4.3 Datasets
Dataset是Spark-1.6新增的一种API,目前还是实验性的。Dataset想要把RDD的优势(强类型,可以使用lambda表达式函数)和Spark SQL的优化执行引擎的优势结合到一起。Dataset可以由JVM对象构建(constructed )得到,而后Dataset上可以使用各种transformation算子(map,flatMap,filter 等)。
Dataset API 对 Scala 和 Java的支持接口是一致的,但目前还不支持Python,不过Python自身就有语言动态特性优势(例如,你可以使用字段名来访问数据,row.columnName)。对Python的完整支持在未来的版本会增加进来。
spark 1.2升级到1.3 SchemaRDD重命名为DataFrame
4.4 创建DataFrame
Spark应用可以用SparkContext创建DataFrame,所需的数据来源可以是已有的RDD(existing RDD),或者Hive表,或者其他数据源(data sources.)
以下是一个从JSON文件创建DataFrame的小栗子:
4.5 DataFrame操作
DataFrame提供了结构化数据的领域专用语言支持,包括Scala, Java, Python and R.
这里我们给出一个结构化数据处理的基本示例:
4.6 创建Dataset
Dataset API和RDD类似,不过Dataset不使用Java序列化或者Kryo,而是使用专用的编码器(Encoder )来序列化对象和跨网络传输通信。如果这个编码器和标准序列化都能把对象转字节,那么编码器就可以根据代码动态生成,并使用一种特殊数据格式,这种格式下的对象不需要反序列化回来,就能允许Spark进行操作,如过滤、排序、哈希等。
4.7 和RDD互操作
Spark SQL有两种方法将RDD转为DataFrame。
- 使用反射机制,推导包含指定类型对象RDD的schema。这种基于反射机制的方法使代码更简洁,而且如果你事先知道数据schema,推荐使用这种方式;
- 编程方式构建一个schema,然后应用到指定RDD上。这种方式更啰嗦,但如果你事先不知道数据有哪些字段,或者数据schema是运行时读取进来的,那么你很可能需要用这种方式。
4.7.1 利用反射推导schema
Spark SQL的Scala接口支持自动将包含case class对象的RDD转为DataFrame。对应的case class定义了表的schema。case class的参数名通过反射,映射为表的字段名。case class还可以嵌套一些复杂类型,如Seq和Array。RDD隐式转换成DataFrame后,可以进一步注册成表。随后,你就可以对表中数据使用SQL语句查询了。
4.7.2 编程方式定义Schema
如果不能事先通过case class定义schema(例如,记录的字段结构是保存在一个字符串,或者其他文本数据集中,需要先解析,又或者字段对不同用户有所不同),那么你可能需要按以下三个步骤,以编程方式的创建一个DataFrame:
- 从已有的RDD创建一个包含Row对象的RDD
- 用StructType创建一个schema,和步骤1中创建的RDD的结构相匹配
- 把得到的schema应用于包含Row对象的RDD,调用这个方法来实现这一步:SQLContext.createDataFrame
4.8 数据源
4.8.1 通用加载/保存函数
在最简单的情况下,所有操作都会以默认类型数据源来加载数据(默认是Parquet,除非修改了spark.sql.sources.default 配置)。
val df = sqlContext.read.load("examples/src/main/resources/users.parquet")
df.select("name", "favorite_color").write.save("namesAndFavColors.parquet")4.8.2 手动指定选项
你也可以手动指定数据源,并设置一些额外的选项参数。数据源可由其全名指定(如,org.apache.spark.sql.parquet),而对于内建支持的数据源,可以使用简写名(json, parquet, jdbc)。任意类型数据源创建的DataFrame都可以用下面这种语法转成其他类型数据格式。
val df = sqlContext.read.format("json").load("examples/src/main/resources/people.json")
df.select("name", "age").write.format("parquet").save("namesAndAges.parquet")4.8.3 直接对文件使用SQL
Spark SQL还支持直接对文件使用SQL查询,不需要用read方法把文件加载进来。
val df = sqlContext.sql("SELECT * FROM parquet.`examples/src/main/resources/users.parquet`")4.8.4 保存模式
Save操作有一个可选参数SaveMode,用这个参数可以指定如何处理数据已经存在的情况。很重要的一点是,这些保存模式都没有加锁,所以其操作也不是原子性的。另外,如果使用Overwrite模式,实际操作是,先删除数据,再写新数据。

4.8.5 保存到持久化表
在使用HiveContext的时候,DataFrame可以用saveAsTable方法,将数据保存成持久化的表。与registerTempTable不同,saveAsTable会将DataFrame的实际数据内容保存下来,并且在HiveMetastore中创建一个游标指针。持久化的表会一直保留,即使Spark程序重启也没有影响,只要你连接到同一个metastore就可以读取其数据。读取持久化表时,只需要用用表名作为参数,调用SQLContext.table方法即可得到对应DataFrame。
默认情况下,saveAsTable会创建一个”managed table“,也就是说这个表数据的位置是由metastore控制的。同样,如果删除表,其数据也会同步删除。
4.9 数据集
两种实现方式,


4.10 性能调优

Parquet列式存储
Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目
列式存储
列式存储和行式存储相比有哪些优势呢?
- 可以跳过不符合条件的数据,只读取需要的数据,降低IO数据量。
- 压缩编码可以降低磁盘存储空间。由于同一列的数据类型是一样的,可以使用更高效的压缩编码(例如Run Length Encoding和Delta Encoding)进一步节约存储空间。
- 只读取需要的列,支持向量运算,能够获取更好的扫描性能。
4.11 数据类型

