前言
好久没有给大家更新爬虫的项目了,说来也有点惭愧,本着和广大Python爱好者一起学习的目的,这次给大家带来了Scrapy的分布式爬虫。
爬虫逻辑
本次我们的爬虫目的是爬取知乎信息,即爬取你所要爬取的知乎用户和其关注者以及其关注者的信息,这里有点绕,我不知道大家听懂了没有。相当于算法里的递归,由一个用户扩散到关注者用户,再到其关注者。爬取的初始链接页面如下。

我们发现people后面的是用户名,即你可以修改你想要爬取的指定用户,follower是关注者,如果你想爬取你所关注的人信息的话,改成following即可。我们打开开发者工具,发现当前信息页面并没有我们要提取的信息,究其原因是因为此页面是Ajax加载形式,我们需要切换到XHR栏中找到我们需要的链接。如下图所示。

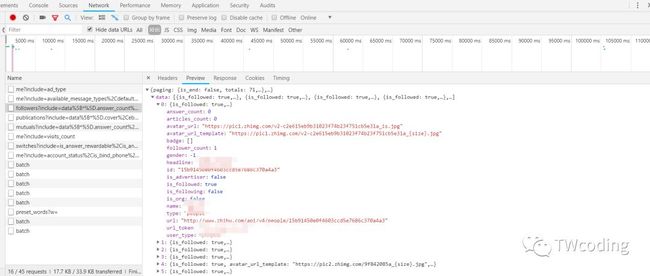
最终我们发现其加载页面,并获得其加载链接,发现其数据格式是Json格式,那么这就对我们的数据采集来说就方便很多了。如果我们想要爬取更多的关注者,就只需要把limit里的数值改成20的倍数就可以了。至此我们的爬虫逻辑就已经讲解清楚了。
源码部分
1.不使用分布式
class ZhihuinfoSpider(Spider):
name = 'zhihuinfo'
#radis_key='ZhihuinfoSpider:start_urls'
allowed_domains = ['www.zhihu.com']
start_urls = ['https://www.zhihu.com/api/v4/members/bu-xin-ming-71/followers?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset=20&limit=20']
def parse(self, response):
responses=json.loads(response.body.decode('utf-8'))["data"]
count=len(responses)
if count<20:
pass
else:
page_offset=int(re.findall('&offset=(.*?)&',response.url)[0])
new_page_offset=page_offset+20
new_page_url=response.url.replace(
'&offset='+str(page_offset)+'&',
'&offset=' + str(new_page_offset) + '&'
)
yield Request(url=new_page_url,callback=self.parse)
for user in responses:
item=ZhihuItem()
item['name']=user['name']
item['id']= user['id']
item['headline'] = user['headline']
item['url_token'] = user['url_token']
item['user_type'] = user['user_type']
item['gender'] = user['gender']
item['articles_count'] = user['articles_count']
item['answer_count'] = user['answer_count']
item['follower_count'] = user['follower_count']
with open('userinfo.txt') as f:
user_list=f.read()
if user['url_token'] not in user_list:
with open('userinfo.txt','a') as f:
f.write(user['url_token']+'-----')
yield item
new_url='https://www.zhihu.com/api/v4/members/'+user['url_token']+'/followers?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset=20&limit=20'
yield Request(url=new_url,callback=self.parse)
2.使用分布式
class ZhihuinfoSpider(RedisCrawlSpider):
name = 'zhihuinfo'
radis_key='ZhihuinfoSpider:start_urls'
allowed_domains = ['www.zhihu.com']
#start_urls = ['https://www.zhihu.com/api/v4/members/bu-xin-ming-71/followers?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset=20&limit=20']
def parse(self, response):
responses=json.loads(response.body.decode('utf-8'))["data"]
count=len(responses)
if count<20:
pass
else:
page_offset=int(re.findall('&offset=(.*?)&',response.url)[0])
new_page_offset=page_offset+20
new_page_url=response.url.replace(
'&offset='+str(page_offset)+'&',
'&offset=' + str(new_page_offset) + '&'
)
yield Request(url=new_page_url,callback=self.parse)
for user in responses:
item=ZhihuItem()
item['name']=user['name']
item['id']= user['id']
item['headline'] = user['headline']
item['url_token'] = user['url_token']
item['user_type'] = user['user_type']
item['gender'] = user['gender']
item['articles_count'] = user['articles_count']
item['answer_count'] = user['answer_count']
item['follower_count'] = user['follower_count']
with open('userinfo.txt') as f:
user_list=f.read()
if user['url_token'] not in user_list:
with open('userinfo.txt','a') as f:
f.write(user['url_token']+'-----')
yield item
new_url='https://www.zhihu.com/api/v4/members/'+user['url_token']+'/followers?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset=20&limit=20'
yield Request(url=new_url,callback=self.parse)
可以发现使用Scrapy分布式只需要改动两处就可以,再在之后的配置文件中加上配置即可。如果是分布式运行,最后开启多个终端即可。不使用分布式就只需要在一个终端上运行就可以了
运行页面

运行结果
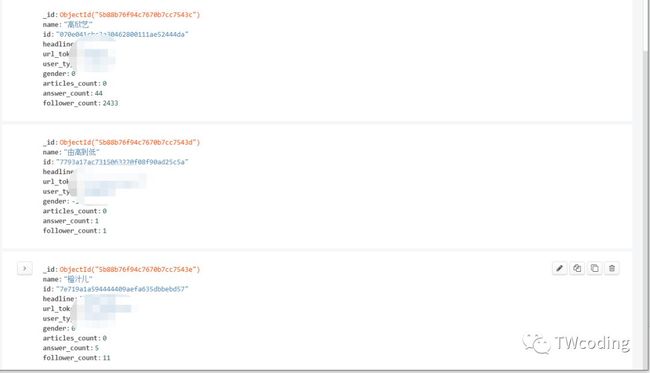
分布式爬虫的速度很快,经小编测试半分钟不到就已经采集了两万多条数据。感兴趣的小伙伴们可以先尝试下,对于没有Scrapy框架基础的小伙伴,也没有关系,爬虫逻辑都是一样的。你们只需要复制爬虫部分代码也可以运行。
推荐阅读:
爬虫进阶之去哪儿酒店(国内外)
Scrapy之抓取淘宝美食
大型爬虫案例:爬取去哪儿网
对爬虫,数据分析,算法感兴趣的朋友们,可以加微信公众号 TWcoding,我们一起玩转Python。
If it works for you.Please,star.
自助者,天助之
