目标跟踪算法
目标跟踪算法
- 一、目标跟踪算法简介
- 1.1 主要任务
- 1.1.1 Online Visual Tracker BenchMark
- 1.1.2 VOT
- 1.2 难点与挑战
- 1.3 分类
- 1.3.1 常规分类
- 1.3.2 时间分类
- 二、常用算法介绍
- 2.1 早期跟踪算法
- 2.1.1 光流算法
- 2.1.2 Meanshift
- 2.1.3 Camshift
- 2.1.4 Kalman滤波
- 2.1.5 粒子滤波
- 2.2 相关滤波(CF)
- 2.2.1 Minimum Output Sum of Squared Error (MOSSE)
- 2.2.2 CSK
- 2.2.3 CN
- 2.2.4 Kernel Correlation Filter (KCF)
- 2.2.5 SAMF
- 2.2.6 SRDCF
- 2.3 深度学习方法
- 2.3.1 C-COT
- 2.3.2 ECO
- 2.3.3 DLT
- 2.3.4 FCNT
- 2.3.5 MDNet
- 2.3.6 RTT
- 三、近年来,研究进展
一、目标跟踪算法简介
1.1 主要任务
1.1.1 Online Visual Tracker BenchMark
- 数据集
单目标跟踪
OTB50(2013年) & OTB100(2015年) - Precision plot:
踪算法估计的目标位置(bounding box)的中心点与人工标注(ground-truth)的目标的中心点,这两者的距离小于给定阈值的视频帧的百分比。 - Success plot
首先定义重合率得分(overlap score,OS),追踪算法得到的bounding box(记为a),与ground-truth给的box(记为b),重合率定义为:OS = |a∩b|/|a∪b|,|·|表示区域的像素数目。当某一帧的OS大于设定的阈值时,则该帧被视为成功的(Success),总的成功的帧占所有帧的百分比即为成功率(Success rate)。OS的取值范围为0~1,因此可以绘制出一条曲线。一般阈值设定为0.5。
1.1.2 VOT
- 数据集
2013-2019(竞赛数据集,单目标跟踪) - 评价指标
(1)平均重叠期望(EAO)是对每个跟踪器在一个短时图像序列上的非重置重叠的期望值,是VOT评估跟踪算法精度的最重要指标。
(2)准确率(Accuracy)是指跟踪器在单个测试序列下的平均重叠率(两矩形框的相交部分面积除以两矩形框的相并部分的面积。(MeanIOU)
(3)鲁棒性(Robustness)是指单个测试序列下的跟踪器失败次数,当重叠率为0时即可判定为失败。
1.2 难点与挑战
目标遮挡、目标消失、运动模糊、目标和环境的剧烈变化、目标的高速运动、相机的抖动、光照变化、背景杂波、低分辨率等。
1.3 分类
1.3.1 常规分类
- 生成式模型:反映同类别相似度。此类方法首先建立目标模型或者提取目标特征, 在后续帧中进行相似特 征搜索。逐步迭代实现目标定位。缺点:在光照变化, 运动模 糊, 分辨率低, 目标旋转形变等情况下,目标跟踪准确性不高。常用算法:光流法、粒子滤波、Meanshift 算法 、Camshift算法、KCF、SRDCF、SRDCFdecon、stable、EBT。
- 判别式模型(track by detection):反映不同类别的差异。通过对比目标模型和背景信息的差异, 将目标模型提取出来, 从而得到当前帧中的目标位置。目前主要采用的模型。常用算法:MIL,OAB,struck,MEEM,TLD、支持向量机。
1.3.2 时间分类
-
早期跟踪模型:大部分是生成式模型。细分主要包括:
(1)基于目标模型建模:基于区域匹配、基于特征点跟踪、基于主动轮廓的跟踪算法、光流法等。
(2)基于搜索的方法:为了减少搜索范围,一种方式通过预测减少搜索范围,如:Kalman滤波、粒子滤波等。另一种为内核算法,运用最速下降法的原理, 向梯度下降方向对目标模板逐步迭代, 直到迭 代到最优位置。如:Meanshift、Camshift。 -
相关滤波模型:属于判别式模型,相关滤波之前,所有的跟踪都是在时域上进行,涉及复杂的矩阵求逆计算,速度慢。相关滤波在频域上进行,利用 循环矩阵可以在频域对角化的性质,减少了运算量。常用算法:MOSSE、CSK、KCF、 BACF、SAMF。
-
深度学习模型:基于相关滤波,使用深度学习对特征提取、特征搜索等方向进行改进。
二、常用算法介绍
2.1 早期跟踪算法
2.1.1 光流算法
- 光流的三个假设条件
(1)前后两点的位移较小(可以泰勒展开的条件)
(2)移动前后光强保持恒定
(3)空间相关性,每个点的运动和他们的邻居相似(连续函数,泰勒展开) - 公式推导
在相邻的两帧图像中,点(x,y)发生了位移(u,v),那么移动前后两点的亮度应该是相等的,有如下等式:
I ( x , y , t − 1 ) = I ( x + u , y + v , t ) I(x,y,t-1)=I(x+u,y+v,t) I(x,y,t−1)=I(x+u,y+v,t)
一阶线性泰勒展开:
I ( x + u , y + v , t ) = I ( x , y , t − 1 ) + I x u + I y v + I t I(x+u,y+v,t) = I(x,y,t-1) + I_x u+I_y v+I_t I(x+u,y+v,t)=I(x,y,t−1)+Ixu+Iyv+It
上式联立有:
I x u + I y v + I t = 0 I_x u+I_y v+I_t =0 Ixu+Iyv+It=0
要求位移量 u u u和 v v v,利用第三个假设,L-K(Lucas-Kanade)求解:

利用最小二乘法求解:

改进----金字塔光流:解决有些目标移动较大的问题 - 光流按照原理分类
(1)基于梯度的光流:Horn-Schunck算法,全局平滑假设,假设在整个图像上光流的变化是光滑的,物体运动矢量是平滑的或只是缓慢变化的。
(2)基于匹配的方法:包括基于特征和区域的两种。基于特征的方法不断地对目标主要特征进行定位和跟踪,对目标大的运动和亮度变化具有鲁棒性(robustness)。基于区域的方法先对类似的区域进行定位,然后通过相似区域的位移计算光流。
(3)基于能量的方法:首先要对输入图像序列进行时空滤波处理,这是一种时间和空间整合。
(4)基于相位的方法:速度是根据带通滤波器输出的相位特性确定的。
(5)神经动力学方法:利用神经网络建立的视觉运动感知的神经动力学模型。 - 光流按照二维矢量的疏密程度分类
(1)稠密光流:针对图像或指定的某一片区域进行逐点匹配的图像配准方法,它计算图像上所有的点的偏移量,从而形成一个稠密的光流场。
(2)稀疏光流:指定一组点进行跟踪,这组点最好具有某种明显的特性。如Harris角点。
2.1.2 Meanshift
- Meanshift原理
(1)在d维空间中,任选一个点,然后以这个点为圆心,h为半径做一个高维球。
(2)落在这个球内的所有点和圆心都会产生一个向量,向量是以圆心为起点落在球内的点位终点。
(3)把这些向量都相加。相加的结果为Meanshift向量,如图黄线所示,Meanshift向量的终点作为新的球心。重复上述过程,迭代。

- Meanshift目标跟踪
(1)获取跟踪对象的位置信息(x,y,w,h)。
(2)将图像从RGB转为HSV。(消除光照影响)
(3)统计跟踪区域的颜色直方图。
(4)反向投影
(5)在下一帧使用Meanshift跟踪目标 - 反向投影的工作原理
不断的在输入图像中切割跟模板图像大小一致的图像块,并用直方图对比的方式与模板图像进行比较。
假设我们有一张100x100的输入图像,有一张10x10的模板图像,查找的过程是这样的:
步骤:
(1)从输入图像的左上角(0,0)开始,切割一块(0,0)至(10,10)的临时图像;
(2)生成临时图像的直方图;
(3)用临时图像的直方图和模板图像的直方图对比,对比结果记为c;
(4)直方图对比结果c,就是结果图像(0,0)处的像素值;
(5)切割输入图像从(0,1)至(10,11)的临时图像,对比直方图,并记录到结果图像;
(6)重复(1)~(5)步直到输入图像的右下角。
2.1.3 Camshift
Meanshift不能自适应物体大小。camshift做了改进,可以实现自适应物体大小尺寸。算法流程:

2.1.4 Kalman滤波
卡尔曼滤波主要包括两个部分:预测过程、修正过程。
- 预测过程:
x = ( F ∗ x ) + ( B ∗ u ) + w x = (F*x)+(B*u)+w x=(F∗x)+(B∗u)+w,其中 F F F为状态转移矩阵, B B B为状态控制矩阵, u u u称状态控制向量, w w w为外部影响,服从 N ( 0 , Q ) N(0,Q) N(0,Q)。(相当于速度和加速度)
P = ( F ∗ P ∗ F T ) + Q P = (F*P*F^T)+Q P=(F∗P∗FT)+Q,其中 P P P为系统方差, Q Q Q为外部因素方差。 - 修正过程:
y = z − ( H ∗ x ) y = z-(H*x) y=z−(H∗x),其中 y y y为观测余量, z z z为观测矩阵, H H H为转换矩阵,将 x x x量转换为观测量。
S = ( H ∗ P ∗ H T ) + R S = (H*P*H^T)+ R S=(H∗P∗HT)+R,其中 S S S测量余量协方差矩阵。
K = P ∗ H T ∗ S − 1 K=P*H^T*S^{-1} K=P∗HT∗S−1,其中 K K K为卡尔曼增益。
x = x + ( K ∗ y ) x = x+(K*y) x=x+(K∗y),修正后的结果。
P = ( I − K ∗ H ) ∗ P P=(I - K*H)*P P=(I−K∗H)∗P,修正的系统方差。
2.1.5 粒子滤波
步骤:
(1)初始化阶段—提取目标特征:手动选取目标,并提取目标区域的特征,即目标颜色直方图。
(2)初始化粒子:a)将粒子均匀撒在整个图像上。b)在上一帧目标附近按高斯分布散布粒子。
(3)搜索阶段:统计每个粒子的颜色直方图,与目标模型颜色直方图对比,根据巴氏距离计算权值,再对权值进行归一化处理,使得所有粒子的权值相加为1。
(4)粒子重采样:在相似度较低的地方放少量的粒子,相似度高的地方放多放粒子。(抛弃权重低的粒子)
(5)状态转移:根据 s t = A s t − 1 + w t − 1 s_t = As_{t-1}+w_{t-1} st=Ast−1+wt−1计算下一时刻粒子的位置。
(6)观测阶段:计算各个粒子与目标特征的相似度,更新粒子的权重。
(7)决策阶段:计算坐标与相似度的加权平均值,得到跟踪目标下一帧的位置。
(8)根据预测出的位置,重复(3),(4),(5),(6),(7)。
2.2 相关滤波(CF)
2010年,CVPR上《visual object tracking using adaptive correlation filters》首次将相关滤波用到跟踪算法上。后面接着出现了一些经典的相关滤波算法。这里主要介绍MOSSE、CSK、CN、KCF、SAMF、SRDCF。相关滤波大佬:Martin Danelljan(MD)。相关滤波的发展可以总结为:
(1)从单特征到多特征:CSK、CN、KCF。
(2)尺度的变换:SAMF。
(3)模型的改进:SRDCF。
2.2.1 Minimum Output Sum of Squared Error (MOSSE)
根据图像处理相关操作的原理以及最小二乘法可以推导出滤波器的模版函数:
H ∗ = 1 N ∑ i = 1 N G i ⊙ F i ∗ F i ⊙ F i ∗ H^{*} =\frac{1}{N}\sum_{i=1}^{N}\frac{G_i\odot F^*_i}{F_i\odot F^*_i} H∗=N1∑i=1NFi⊙Fi∗Gi⊙Fi∗
其中, N N N为样本数, G i G_i Gi为输出的频域表达式(预测结果), F i F_i Fi为输入的频域表达式。
算法步骤:
(1)初始化
在初始帧的训练集 f i f_i fi用的是第一帧里8个在追踪窗里随机生成干扰,训练集的输出 g i g_i gi就是通过他们的峰值生成,相当于图片的中心。
H ∗ = 1 N ∑ i = 1 N G i ⊙ F i ∗ F i ⊙ F i ∗ H^{*} =\frac{1}{N}\sum_{i=1}^{N}\frac{G_i\odot F^*_i}{F_i\odot F^*_i} H∗=N1∑i=1NFi⊙Fi∗Gi⊙Fi∗
(2)参数更新

2.2.2 CSK
CSK算法通过使用高斯核计算相邻两帧之间的相关性,取响应最大的点为预测的目标中心。该算法是固定目标大小的,对发生尺度变化的目标不鲁棒,速度150FPS。CSK是MOSSE的一个改进,改进主要包括:
(1)在滤波器的函数中,引入正则化项。
m i n w , b ∑ i n L ( y i , f ( x i ) ) + λ ∣ ∣ ω ∣ ∣ 2 min_{w,b} \sum_{i}^n L(y_i,f(x_i))+\lambda||\omega||^2 minw,b∑inL(yi,f(xi))+λ∣∣ω∣∣2
(2)生成的样本方式,不再是通过随机扰动产生。而是引入了循环矩阵得到样本。(在KCF中描述)
(3)引入核函数, w = ∑ α i ϕ ( x i ) w = \sum\alpha_i\phi(x_i) w=∑αiϕ(xi),最优 α \alpha α为:

(4)计算响应:

- 算法步骤:
(1)获取当前帧图像,初始化目标位置。并利用循环矩阵生成样本,训练回归器。
(2)获取下一帧图像,在上一帧目标位置附近利用循环矩阵采样,并用(1)中训练的回归器计算各个窗口的响应。
(3)响应最大的位置即为下一帧目标的位置。
(4)重复(1),(2),(3)
2.2.3 CN
CN是在CSK基础上的改进,采用多通道的颜色color names。
2.2.4 Kernel Correlation Filter (KCF)
KCF是CSK的改进,在CSK的基础上引入了多通道hog特征
-
KCF的基本思路:
(1)在 I t I_t It帧中,在当前位置 p t p_t pt附近采样(利用循环矩阵得到),训练一个回归器。这个回归器可以计算一个小窗口的响应。
(2)在 I t + 1 I_{t+1} It+1帧中,在前一帧位置 p t p_t pt附近采样,用前述回归器判断每个采样窗口的响应(即做相关操作)。
(3)取响应值最大的采样作为本帧的位置。
(4)重复(1),(2),(3) -
回归器的训练
(1)获取样本—循环矩阵
一维循环矩阵:

二维循环矩阵可以分别通过x和y的一位循环实现向量的位移。样例:

(2)一维脊回归
通过求解:
min ω ∣ ∣ X ω − y ∣ ∣ 2 + λ ∣ ∣ ω ∣ ∣ 2 \min_\omega||X\omega-y||^2+\lambda||\omega||^2 minω∣∣Xω−y∣∣2+λ∣∣ω∣∣2
得到:
ω = ( X H X + λ ) − 1 X H y \omega =(X^HX+\lambda)^{-1}X^Hy ω=(XHX+λ)−1XHy
(3)循环矩阵傅氏对角化
所有的循环矩阵都能够在傅氏空间中使用离散傅里叶矩阵进行对角化, X = F d i a g ( x ) F H X = Fdiag(x)F^H X=Fdiag(x)FH,其中 F F F为:

将 X X X对角化结果带入一维脊回归中:

(3)将线性映射换为非线性映射
α = F d i a g ( K x x + λ ) − 1 F H y \alpha =Fdiag(K^{xx}+\lambda)^{-1}F^Hy α=Fdiag(Kxx+λ)−1FHy
其中, K x x = ϕ ( x ) T ϕ ( X ) T K^{xx} = \phi(x)^T\phi(X)^T Kxx=ϕ(x)Tϕ(X)T。
(4)计算响应
f ( z ) = k x z ⊙ α f(z)=k^{xz}\odot\alpha f(z)=kxz⊙α

-
特征:HOG多通道特征
-
优点:速度很快,172FPS,tracking by detection。
-
缺点:不能适应尺度变化和快速变化。
-
相关滤波:CSK–CN–KCF可参考:
https://blog.csdn.net/ycc2011/article/details/84111182
2.2.5 SAMF
VOT2014第一名。7FPS,在KCF等基础上做了以下改进:
(1)多特征融合:HOG+CN+灰度。
(2)多尺度:引入尺度池,缩放比例:{0.985,0.99,0.995,1.0,1.005,1.01,1.015}。
其流程大致如下:

将当前帧的图像输入,经过尺度池,得到不同尺度的图像,然后,将这些经过缩放后的图像送入上一帧训练得到的KCF相关滤波器,得到不同尺度下的坐标以及响应值。响应值最大的即为最合适的尺度。
2.2.6 SRDCF
由于相关滤波是模板类方法, 如果目标快速运动或者发生形变, HOG 特征不能实时地跟上目标的变化, 会 产生错误样本造成分类器性能下降, 导致边界效应 的产生. SRDCF 针对这一问题, 扩大了搜索区域, 加入空间正则化约束。
加入正则化约束具体:
(1)相关滤波的响应图可以通过如下公式计算
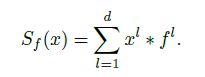
S S S是响应图, x x x是检测图像片, f f f是滤波器。
(2)优化方程为:

w w w为惩罚函数,中间小,周围大。作用:离得越远的样本对滤波器的影响越小。 w w w的图像为:

2.3 深度学习方法
深度学习的特点在于其特征提取能力,可以通过大量的数据训练,提取比传统方法更好的能够代表目标的特征。基于深度学习的跟踪可以分为:
(1)对相关滤波算法改进:C-COT、ECO。
(2)利用辅助图片数据预训练深度模型,在线跟踪时微调:DLT、SO-DLT。
(3)利用现有大规模分类数据集预训练的CNN分类网络提取特征:FCNT。
(4)利用跟踪序列预训练,在线跟踪时微调:MDNet
(5)运用递归神经网络进行目标跟踪的新思路:RTT、DeepTracking
2.3.1 C-COT
2016年VOT冠军,结合深度学习提取特征(CNN+HOG+CN)。速度较慢。

(1)第一列:针对搜索区域,提取不同分辨率的特征(VGG),不同分辨率采用插值的方式(0.96,0.98,1.00,1.02,1.04)五种缩放方式。
(2)第二列:通过针对不同层训练的相关滤波器进行计算(卷积层,训练得到,每帧以目标为中心提取一个样本)。
(3)第三列:通过对特征图卷积得到响应图(Confidence Scores)。
(4)第四列:将第三列的响应图进行加权平均,就得到了第四列的结果,响应图极大值位置就是预测的目标位置。
2.3.2 ECO
在C-COT基础上做了改进,速度比C-COT更快,60FPS。主要包括以下几个改进。
(1)减少了特征的维度,从D维特征中选择了其中C维;减少了滤波器个数,C-COT每一维对应一个滤波器,而ECO只选择了其中共献较多的滤波器。
(2)减少相同样本,ECO用了高斯混合模型(GMM)来生成不同的component,每一个component基本就对应一组比较相似的样本,不同的component之间有较大的差异性。这样就使得训练集具有了多样性。

(3)减小模型更新频率,ECO这里的做法很简单,就是简单地规定每隔Ns帧更新一次。注意这里的Ns只是对模型的更新,样本的更新是每一帧都要做的。最后的实验中,Ns设置为6。
2.3.3 DLT
首次将深度学习应用到跟踪上,2013年OTB50数据集上排名第5。
- 算法步骤:
(1)提前训练一个预训练模型。如图(b)
(2)第一帧,微调网络(c)参数,通过目标位置生成正负样本,训练分类网络。在后续帧,当所有粒子中最高的confidence低于阈值时,认为目标已经发生了比较大的表观变化,当前的分类网络已经无法适应,需要进行更新,目标的位置作为正样本,其余作为负样本。
(3)对当前帧采用粒子滤波(particle filter)的方式提取一批候选框,将这些候选框送入到分类网络,置信度最高的即为目标的位置。 - 训练步骤:
(1)预训练模型:如图(b),训练栈式降噪自编码器。
(2)微调网络:如图(c)。

- 不足:
(1) 离线预训练采用的数据集Tiny Images dataset只包含32*32大小的图片,分辨率明显低于主要的跟踪序列,因此SDAE很难学到足够强的特征表示。
(2) 离线阶段的训练目标为图片重构,这与在线跟踪需要区分目标和背景的目标相差甚大。
(3) SDAE全连接的网络结构使其对目标的特征刻画能力不够优秀,虽然使用了4层的深度模型,但效果仍低于一些使用人工特征的传统跟踪方法如Struck等。
2.3.4 FCNT
FCNT主要对VGG-16的Conv4-3和Conv5-3层输出的特征图谱(feature map)做了分析,并得出以下结论:
(1) CNN 的feature map可以用来做跟踪目标的定位。
(2) CNN 的许多feature map存在噪声或者和物体跟踪区分目标和背景的任务关联较小。
(3) CNN不同层的特征特点不一。高层(Conv5-3)特征擅长区分不同类别的物体,对目标的形变和遮挡非常鲁棒,但是对类内物体的区分能力非常差。低层(Conv4-3)特征更关注目标的局部细节,可以用来区分背景中相似的distractor,但是对目标的剧烈形变非常不鲁棒。
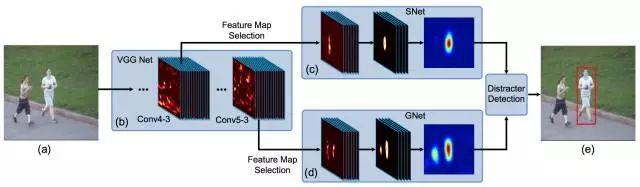
FCNT的框架:
(1) 对于Conv4-3和Conv5-3特征分别构建特征选择网络sel-CNN(1层dropout加1层卷积),选出和当前跟踪目标最相关的feature map channel。
(2) 对筛选出的Conv5-3和Conv4-3特征分别构建捕捉类别信息的GNet和区分distractor(背景相似物体)的SNet(都是两层卷积结构)。
(3) 在第一帧中使用给出的bounding-box生成热度图(heat map)回归训练sel-CNN, GNet和SNet。
(4) 对于每一帧,以上一帧预测结果为中心crop出一块区域,之后分别输入GNet和SNet,得到两个预测的heatmap,并根据是否有distractor决定使用哪个heatmap 生成最终的跟踪结果。
小结:FCNT根据对CNN不同层特征的分析,构建特征筛选网络和两个互补的heat-map预测网络。达到有效抑制distractor防止跟踪器漂移,同时对目标本身的形变更加鲁棒的效果,也是ensemble思路的又一成功实现。但实测鲁棒性不高,现有的更新策略还有提高空间。
2.3.5 MDNet

MDNet网络分为两个部分,前部分为共享层,提取特征,后部分Domain-specific层针对不同的跟踪目标建立不同的任务。
训练时:每个mini-batch训练一个类别的序列,训练完后,共享层获得了对序列共有特征的表达能力。
在线跟踪阶段,针对不同的跟踪序列:
(1) 随机初始化一个新的fc6层。
(2) 使用第一帧的数据来训练该序列的bounding box回归模型。
(3) 用第一帧提取正样本和负样本,更新fc4, fc5和fc6层的权重。
(4) 之后产生256个候选样本,并从中选择置信度最高的,之后做bounding-box regression得到最终结果。
(5) 当前帧最终结果置信度较高时,采样更新样本库,否则根据情况对模型做短期或者长期更新。
2.3.6 RTT
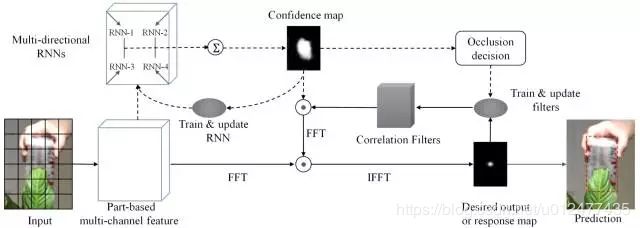
(1) 首先对每一帧的候选区域进行网状分块,对每个分块提取HOG特征,最终相连获得基于块的特征。

(2) 得到分块特征以后,RTT利用前5帧训练多方向RNN来学习分块之间大范围的空间关联。通过在4个方向上的前向推进,RNN计算出每个分块的置信度,最终每个块的预测值组成了整个候选区域的置信图(confidence map)。受益于RNN的recurrent结构,每个分块的输出值都受到其他关联分块的影响,相比于仅仅考虑当前块的准确度更高,避免单个方向上遮挡等的影响,增加可靠目标部分在整体置信图中的影响。
(3) 由RNN得出置信图之后,RTT执行了另外一条pipeline。即训练相关滤波器来获得最终的跟踪结果。值得注意的是,在训练过程中RNN的置信图对不同块的filter做了加权,达到抑制背景中的相似物体,增强可靠部分的效果。
(4) RTT提出了一个判断当前跟踪物体是否被遮挡的策略,用其判断是否更新。即计算目标区域的置信度和,并与历史置信度和的移动平均数(moving average)做一个对比,低于一定比例,则认为受到遮挡,停止相关滤波器模型更新,防止引入噪声。
三、近年来,研究进展
近年来,跟踪算法主要思路均采用判别式模型,以下是跟踪必要的几个模块:特征提取(选择特征的方法),关联匹配模块(相关滤波采用相关滤波器,部分跟踪算法则采用欧式距离),检测器(相关滤波采用训练一个回归器,部分跟踪算法则选择深度学习检测)。