设计范式:
第一范式:字段是原子性
第二范式:存在可用主键
第三范式:任何表都不应该有依赖于其它表非主键的字段
创建数据库、设计数据表
字段:字段名、数据类型、约束(通过键来实现,而键其实可以当做索引来用)
获取程序默认使用的配置:
[root@localhost ~]# mysqld --print-defaults;
获取可用参数列表:mysqld --help -verbose
获取运行中的mysql进程使用各个服务器参数及其值:
mysql> SHOW GLOBAL VARIABLES; mysql> SHOW [SESSION] VARIABLES;
注:其中有些参数支持运行时修改,会立即生效;有些参数不支持,且只能通过修改配置文件,并重启服务器程序生效;
有些参数作用域是全局的,且不可改变;有些可以为每个用户提供单独的设置
修改服务器变量的值:
mysql>help SET
全局:mysql>SET GLOBAL|@@global. system_var_name=value;
会话:mysql>SET [SESSION|@@session. | @@] system_var_name=value;
状态变量:用于保存mysqld运行中的统计数据的变量 (不可修改)
mysq> SET GLOBAL STATUS;
mysq> SET [SESSION] STATUS;
=======================================================================================
DDL:CREATE、DROP、ALTER
DML:INSERT(REPLACE)、DELETE、UPDATE 、SELECT
DCL:GRANT、REVOKE
数据类型: datatype 字符: 定长字符: 不区分大小写 char(#) 用或不用,给1个占10个 区分大小写 binary(#) 变长字符: 不区分大小写 varchar(#) 有结束符,占用一个, 给1个,占2个 区分大小写 varbinary(#) 对象存储:大文本存储 TEXT 不区分大小写 BLOB 区分----二进制的大对象 内置类型: ENUM 枚举(给你几种,最多有几种选择) SET 集合 数值: 精确:整型[int]、十进制[decimal] int tinyint 1byte smallint 2bytes mediumint 3bytes int 4bytes bigint 8bytes 范围: 0 - 2^64-1 近似: 单精度浮点[float]、双精度浮点[double]
日期时间型:
日期:DATE
时间:TIME
日期时间:TIMESTAMP
年份:YEAR(2),YEAR(4)
修饰符:
所有类型: NOT NULL :非空约束 DEFAULT NULL :设定默认值
UNIQUE KEY
PRIMARY KEY
数值型适用:
UNSIGNED :(对整型和数值型)无符号---不能表示负数,仅用于表示正数
AUTO_INCREMENT :自增长--整型
二、数据库基础应用:
2.1、DDL
2.1.1、创建表:
(1)直接创建
CREATE TABLE [IF NOT EXISTS] 'tbl_name' (col1 type1,col2 type2, ...)
col1 type1:
PRIMARY KEY(col1,...)
INDEX(col1,...)
UNIQUE KEY(col1,...)
(2)通过查询现存的表创建:新表会被直接插入查询而来的数据:
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
(create_definition,...)
[table_options]
[partition_options]
(3)通过复制现存的表的表结构创建:不复制数据
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name { LIKE old_tbl_name | (LIKE old_tbl_name) }
注:Storage Engine是指表类型,也即在表创建时指明其使用的存储引擎:
同一个库中表要使用同一种存储引擎类型
查询默认引擎:
mysql>SHOW ENGINES;
获取帮助:
mysql>HELP CREATE TABLE;
获取表创建命令:
mysql> SHOW CREATE TABLE students;
查询表状态:
mysql>SHOW TABLE STATUS LIKE 'tbl_name' \G; \G--把每一行数据竖排显示
删除表
mysql> DROP TABLE [IF EXISTS] 'tbl_name';
查看表上的索引
mysql> SHOW INDEXES FROM [db_name.]tbl_name;
查看表结构
mysql> DESC tbl_name;
查看某库中的表
mysql> SHOW TABLES FROM database_name;
mysql> SHOW GLOBAL VARIABLES LIKE '%default%';
E.G
定义单字段的唯一键:
mysql> CREATE TABLE students (id int UNSIGNED NOT NULL PRIMARY KEY,name VARCHAR(20) NOT NULL,Age tinyint UNSIGGNED);

多字段组合式唯一键(两者联合起来不一样就可以):
mysql> CREATE TABLE tbl2 (id int UNSIGNED NOT NULL ,name VARCHAR(20) NOT NULL,Age tinyint UNSIGNED,PRIMARY KEY(id,name));

2.1.2、ALTER 修改表
帮助:
mysql>HELP ALTER TABLE;
ALTER [COLUMN] col_name {SET DEFAULT literal | DROP DEFAULT} 设定默认值或移除默认值这两个属性
CHANGE [COLUMN] old_col_name new_col_name column_definition 修改字段名字和字段定义
[FIRST|AFTER col_name]
MODIFY [COLUMN] col_name column_definition 只修改字段定义 或字段的排序
[FIRST | AFTER col_name]
语法:
ALTER TABLE 'tb_name'
a) 字段:
添加字段:add
| ADD [COLUMN] col_name column_definition [FIRST | AFTER col_name]
e.g mysql> ALTER TABLE students ADD gender ENUM('m','f') AFTER name;
删除字段:drop
e.g mysql> ALTER TABLE students drop gender ;
修改字段:alter(删除字段默认值)、change(该字段名称)、modify(字段属性定义)
注:该字段名字的时候,还必须把字段的属性定义出来,任何字段都有其字段定义 类型修饰符必须紧跟在类型后面 如果主键定义过,可以不需要重新定义。 e.g 修改字段名称
mysql> ALTER TABLE students CHANGE id sid int UNSIGNED NOT NULL PRIMARY KEY; ERROR 1068 (42000): Multiple primary key defined mysql> ALTER TABLE students CHANGE id sid int UNSIGNED NOT NULL ; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0
b) 索引: 键都是索引,但索引不是键
添加索引:add
添加唯一键约束: | ADD [CONSTRAINT [symbol]] UNIQUE [INDEX|KEY] [index_name] e.g mysql> ALTER TABLE students ADD UNIQUE KEY(name); 添加索引: | ADD {INDEX|KEY} [index_name] e.g mysql> ALTER TABLE students ADD INDEX(age);
删除索引:drop
注:每个索引都有Key_name字段值,如果定义索引时没给索引名字,那么索引名字就是字段名字;如果索引在多键上,那么索引名字就是多键上的第一个字段名字
c) 表选项 (副作用大一般不用)
2.1.3、索引:是特殊数据结构;定义在查找时作为查找条件的字段;只用添加和删除
索引类型:
聚集索引、非聚集索引:数据是否与索引存储在一起;
主键索引、辅助索引
稠密索引、稀疏索引:是否索引了每一个数据项
优点:加速查询操作
缺点:额外占用空间;插入数据时需要插入2次-----原表中插入一行的同时索引中也要插入一行,更重要的是索引是排序的
管理索引的途径:
创建索引:创建表时指定;
创建或删除索引:修改表的命令
Mysql 是左前缀索引
a)、帮助:
mysql> HELP CREATE|DROP INDEX;
b)、语法:
创建索引:
CREATE INDEX index_name ON tbl_name (inde_col_name,...) 注:索引只要用不上了就立刻删除,否则会产生多余IO,影响性能
删除索引:
DROP INDEX index_name ON tbl_name
查询索引:
SHOW INDEXES FROM tb_name;
EXPLAIN :分析这个查询语句过程当中是否用到索引以及如何实现数据获取
mysql> EXPLAIN SELECT * FROM students WHERE sid=1 \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: students
partitions: NULL
type: const
possible_keys: PRIMARY #主键查询导致const类型(一对一查询结果)
key: PRIMARY
key_len: 4
ref: const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
mysql> EXPLAIN SELECT * FROM students WHERE name='zhaoming' \G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: students partitions: NULL type: ALL possible_keys: NULL #NULL,类型为ALL 则是全表扫描然后对比WHERE 的条件一个一个过滤符合的显示出来 key: NULL key_len: NULL ref: NULL rows: 4 filtered: 25.00 Extra: Using where 1 row in set, 1 warning (0.00 sec)
添加索引后:
mysql> EXPLAIN SELECT * FROM students WHERE name='zhaoming' \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: students
partitions: NULL
type: ref
possible_keys: name #类型ref:查询时还额外的消耗其它操作
key: name
key_len: 22
ref: const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
e.g
mysql> DROP INDEX name ON students;
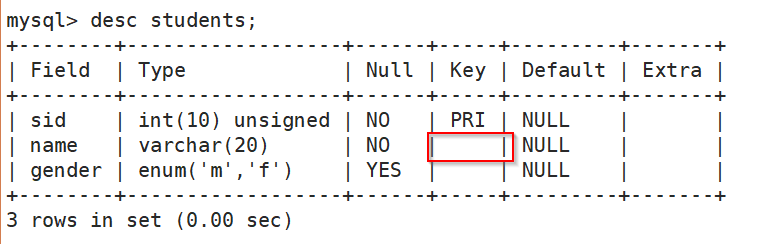
三、DML: INSERT、DELETE、SELECT、UPDATE
3.1、INSERT:一次插入一行或多行数据
a)帮助信息:
mysql> HELP INSERT;
b)语法:
INSERT [INTO] tbl_name [(col1_name,col2_name,...)] {VALUES | VALUE} (value1_list),(value2_list),(...),...
INSERT [INTO] tb_name SET coll_name='VALUE',coll_name='VALUE';
e.g mysql> INSERT INTO students VALUES(1,'yangguo','m'),(2,'guoxiang','F');
mysql> INSERT INTO students (sid,name) VALUES (3,'zhangwuji'),(4,'zhaoming');
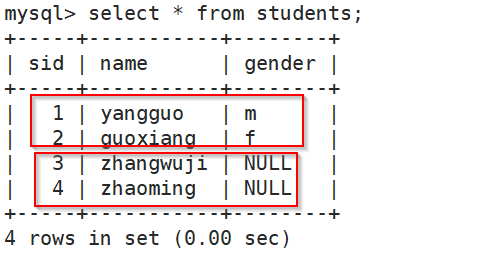
3.2、DELETE
3.2.1、语法:
DELETE FROM tbl_name [WHERE clause] [ORDER BY 'col_name'[DESC]][LIMIT [m,]n]
#只写到WHERE前面会清空整张表(慎)
e.g mysql> DELETE FROM students WHERE sid=3;
3.3、SELECT
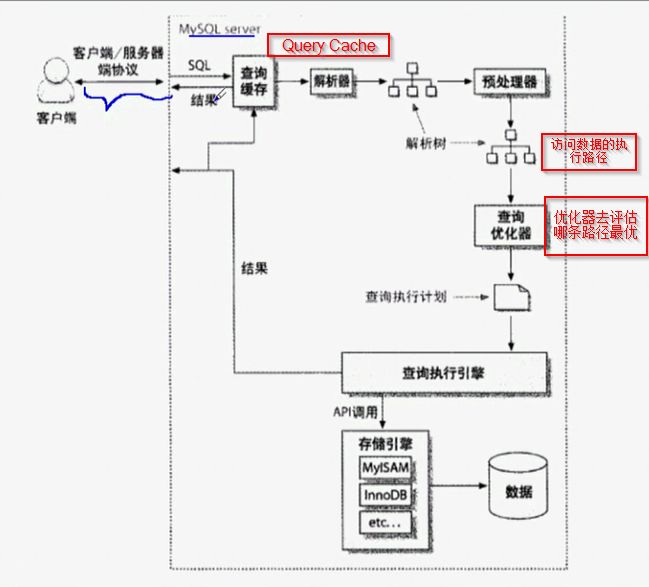
Query Cache :查询结果为确定性结果时才会缓存
查询执行路径中的组件:
mysql> select now(); #显示当前系统时间 +---------------------+ | now() | +---------------------+ | 2020-06-20 16:33:54 | +---------------------+ 1 row in set (0.00 sec)
一个select语句在启动时判断流程:
FROM Clause ---> WHERE Clause ---->GROUP BY ----->having Clause ----->ORDER BY ----->SELECT----->LIMIT
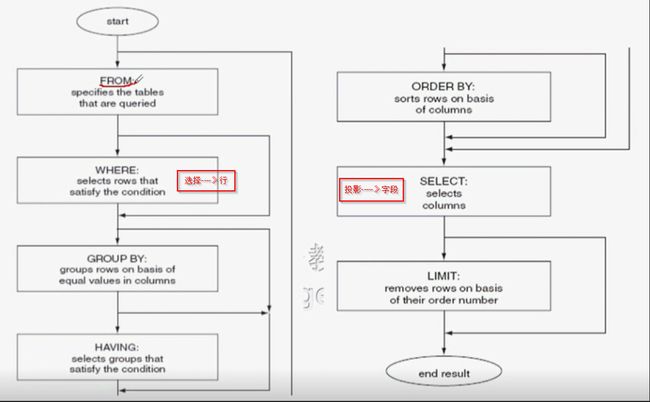
3.3.1、语法
Syntax:
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[SQL_CACHE | SQL_NO_CACHE]
select_expr [, select_expr ...]
[FROM table_references
[PARTITION partition_list]
[WHERE where_condition]
[GROUP BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
DISTINCT :数据去重
SQL_CACHE:显示指定存储查询结果与缓存之中
SQL_NO_CACHE:显示查询结构不予缓存
SELECT col1,col2,... FROM tbl_name [WHERE clause] [ ORDER BY 'col_name' [ASC|DESC] ] [LIMIT [m,]n] #指定字段显示 [#指定字段并判断显示 ] [排序【升序|降序】]
DISTINCT
mysql> SELECT DISTINCT gender FROM students;
+--------+
| gender |
+--------+
| m |
| f |
+--------+
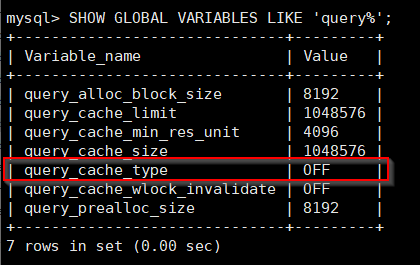
注:query_cache_type的值为“ON”时,查询缓存功能打开
SELECT的结果符合缓存条件即会缓存,否则,不予缓存;
显式指定SQL_NO_CACHE,不予缓存
query_cache_type的值为“DEMAND”时,查询缓存功能按需进行
显式指定SQL_CACHE的SELECT语句才会缓存,其它均不予缓存
mysql> SHOW GLOBAL VARIABLES LIKE 'query%';
命中率=查询命中次数/查询次数
mysql> SHOW GLOBAL STATUS LIKE "Qcache%"; 查询命中次数
mysql> SHOW GLOBAL STATUS LIKE "Com_se%"; 查询次数
mysql> SHOW GLOBAL STATUS LIKE "Qcache%"; +-------------------------+---------+ | Variable_name | Value | +-------------------------+---------+ | Qcache_free_blocks | 1 | | Qcache_free_memory | 1031832 | | Qcache_hits | 0 | | Qcache_inserts | 0 | | Qcache_lowmem_prunes | 0 | | Qcache_not_cached | 42 | | Qcache_queries_in_cache | 0 | | Qcache_total_blocks | 1 | +-------------------------+---------+ 8 rows in set (0.00 sec) mysql> SHOW GLOBAL STATUS LIKE "Com_se%"; +----------------+-------+ | Variable_name | Value | +----------------+-------+ | Com_select | 47 | | Com_set_option | 0 | +----------------+-------+ 2 rows in set (0.00 sec)
LIMIT
SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset LIMIT 子句可以被用于强制 SELECT 语句返回指定的记录数。
LIMIT 接受一个或两个数字参数。参数必须是一个整数常量。如果给定两个参数,
第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行的最大数目。初始记录行的偏移量是 0(而不是 1):
为了与 PostgreSQL 兼容,MySQL 也支持句法: LIMIT # OFFSET #。
3.3.2、字段表示法:
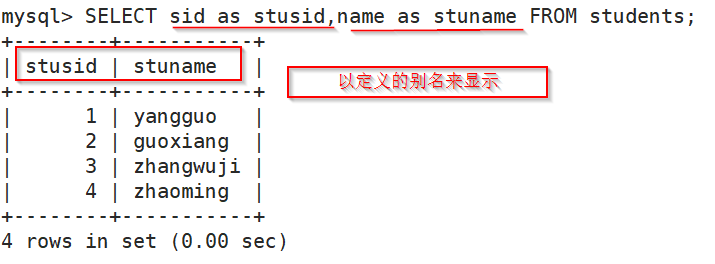
*: 所有字段 as: 字段别名 col1 AS alias1
mysql> SELECT sid as stusid,name as stuname FROM students;
注:不允许一个经常拿来做查找条件字段出现空值
GROUP BY:根据指定的条件把查询结果进行“分组”以用于做“聚合”运算: avg(),max(), min(), count(), sum() HAVING:对分组聚合运算后的结果指定过滤条件 ORDER BY:根据指定的字段对查询结果进行排序 升序:ASC 默认 降序:DESC 对查询结果中的数据请求施加“锁”:
FOR UPDATE:写锁,排它锁
LOCK IN SHARE MODE: 读锁,共享锁
函数聚合运算: mysql> SELECT avg(Age) as AAge,Gender FROM students GROUP BY gender HAVING AAge>20 ORDER BY ;
E.G
a)mysql> SELECT * FROM students WHERE sid>3;

b)mysql> SELECT * FROM students WHERE gender='m';

根据name字段排序 默认升序
c)mysql> SELECT * FROM students ORDER BY name;

d)降序排序
mysql> SELECT * FROM students ORDER BY name DESC;
e)限制显示前2行:
mysql> SELECT * FROM students ORDER BY name DESC LIMIT 2;

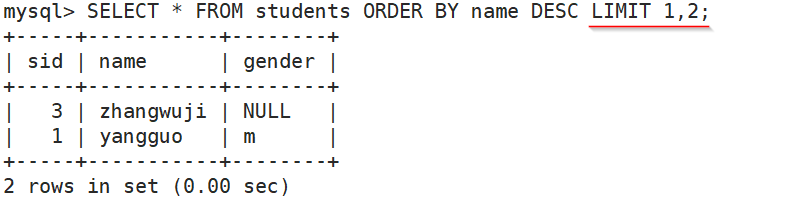
f)偏移量为1,最大数目是2行;
mysql> SELECT * FROM students ORDER BY name DESC LIMIT 1,2;
3.3.3、WHERE clase
算数操作符:+、-、*、/、%
比较操作符:>、>=、<、 <= 、 = 、!=或<>、
BETWEEN .... AND .... IN(element1,element2,...)
基于字符串比较的 LIKE :模糊匹配 %:任意长度的任意字符 _: 任意单个字符 RLIKE :基于正则表达式匹配 (能不用就不用---基于引擎查找) IS NULL IS NOT NULL
条件逻辑操作: and 、or 、not
E.G
mysql> select * from students GROUP BY Age;
ERROR 1055 (42000): Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'testdb.students.sid' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
找原因:查看mysql版本命令:select version();
查看sql_model参数命令:
SELECT @@GLOBAL.sql_mode;
SELECT @@SESSION.sql_mode;

解决方法:
命令行输入 :
set sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';
only_full_group_by模式:在这个模式下,我们使用分组查询时,出现在select字段后面的只能是group by后面的分组字段,或使用聚合函数包裹着的字段。
E.G
mysql> SELECT * FROM students WHERE Age+30 >50;
mysql> SELECT * FROM students WHERE sid>=2 and sid <=4;
mysql> SELECT * FROM students WHERE sid BETWEEN 2 AND 4;
匹配 "z" 开头字段
mysql> SELECT * FROM students WHERE name LIKE 'z%';
3.3.4 多表查询
交叉连接:笛卡尔乘积
内连接:
等值连接:让表之间的字段以“等值”建立连接关系(重点使用)
mysql>SELECT * FROM students,teachers WHERE studenst.TeacherID=teachers.TID;
mysql>SELECT s. Name AS StuName, t.Name AS TeaName FROM students AS s ,teachers AS t WHERE s.TeacherID=t.TID;
自然连接关系
不等值连接
自连接
外连接:
左外连接:以左边字段为准,不管右边显示的数据(无论是否为空,只需要保证有显示即可)
FROM tb1 LEFT JOIN tb2 ON tb1.col=tb2.col
右外连接 :
FROM tb1 RIGHT JOIN tb2 ON tb1.col=tb2.col
mysql>SELECT s. Name , c.Class FROM stduents AS s LEFT JOIN classes AS c ON s.Class=c.Class
子查询:在查询语句嵌套着查询语句
基于某语句的查询结构再次进行查询,比如视图
用在WHERE子句中的子查询:
a.用于比较表达式中的子查询:子查询仅能返回单个值
mysql> SELECT name,Age FROM testdb.students WHERE Age>(SELECT avg(Age) FROM testdb.students);
b.用于IN中的子查询:子查询应该单键查询并返回一个或多个值构成列表
mysql> SELECT name,Age FROM students WHERE Age IN(SELECT Age FROM teachers);
c.用于EXISTS
联合查询:UNION
mysql>SELECT name,Age FROM students UNION SELECT Name,Age FROM teachers;
3.4、UPDATE
语法
UPDATE tbl_name SET col1_name=val1, col2_name=val2,... [WHERE clause] [ORDER BY 'col_name'[DESC]][LIMIT [m,]n]
e.g mysql> UPDATE students SET gender='f' WHERE sid=4;
注:一定要有限制条件,否则将修改所有行的指定字段,限制条件:WHERE和LIMIT
注:5.7版本已经不再使用password来作为密码的字段了 而改成了authentication_string
mysql> SELECT User,Host,authentication_string FROM mysql.user;
mysql> update user set authentication_string=password('123') where user='root'; Query OK, 1 row affected, 1 warning (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 1
练习:导入hellodb.sql生成数据库
(1) 在students表中,查询年龄大于25岁,且为男性的同学的名字和年龄;
MariaDB [hellodb]> select Name,Age from students where Age>25 and Gender='M';
(2) 以ClassID为分组依据,显示每组的平均年龄;
MariaDB [hellodb]> select ClassID,avg(age) as avg_age from students group by ClassID;
(3) 显示第2题中平均年龄大于30的分组及平均年龄;
MariaDB [hellodb]> select ClassID,avg(age) as avg_age from students group by ClassID having avg_age>30;
(4) 显示以L开头的名字的同学的信息;
MariaDB [hellodb]> select * from students where Name like 'L%';
MariaDB [hellodb]> select * from students where Name rlike '^L';
(5) 显示TeacherID非空的同学的相关信息;
MariaDB [hellodb]> select * from students where TeacherID is NOT NULL;
(6) 以年龄排序后,显示年龄最大的前10位同学的信息;
MariaDB [hellodb]> select * from students order by Age desc limit 10;
(7) 查询年龄大于等于20岁,小于等于25岁的同学的信息;用三种方法;
MariaDB [hellodb]> select * from students where age>=20 and age<=25;
MariaDB [hellodb]> select * from students where age between 20 and 25;
练习:导入hellodb.sql,以下操作在students表上执行
1、以ClassID分组,显示每班的同学的人数;
MariaDB [hellodb]> select classid,count(name) from students group by classid;
2、以Gender分组,显示其年龄之和;
MariaDB [hellodb]> select gender,sum(age) from students group by gender;
3、以ClassID分组,显示其平均年龄大于25的班级;
select classid from students group by classid having avg(age) > 25;
4、以Gender分组,显示各组中年龄大于25的学员的年龄之和;
MariaDB [hellodb]> select gender,sum(age) from (select age,gender from students where age>25) as t group by gender;
练习:导入hellodb.sql,完成以下题目:
1、显示前5位同学的姓名、课程及成绩;
MariaDB [hellodb]> select name,course,score from (select * from students limit 5) as t,courses,scores where t.stuid=scores.stuid and scores.courseid=courses.courseid;
2、显示其成绩高于80的同学的名称及课程;
select name,course,score from students,(select * from scores where score > 80) as s,courses where students.stuid=s.stuid and s.courseid=courses.courseid;
3、求前8位同学每位同学自己两门课的平均成绩,并按降序排列;
select name,a from (select * from students limit 8) as s,(select stuid,avg(score) as a from scores group by stuid) as c where s.stuid=c.stuid order by a desc;
4、显示每门课程课程名称及学习了这门课的同学的个数;
select course,count(name) from (select name,course from students,courses,scores where students.stuid=scores.stuid and scores.courseid=courses.courseid) as a group by course;
select courses.course,count(stuid) from scores left join courses on scores.courseid=courses.courseid group by scores.courseid;
思考:
1、如何显示其年龄大于平均年龄的同学的名字?
MariaDB [hellodb]> select name from students where age > (select avg(age) from students);
2、如何显示其学习的课程为第1、2,4或第7门课的同学的名字?
MariaDB [hellodb]> select name from students,(select distinct stuid from (select * from scores where courseid in (1,2,4,7)) as a) as b where b.stuid=students.stuid;
select students.name from students,(select distinct stuid from scores where courseid in (1,2,4,7))as s where s.stuid=students.stuid;
3、如何显示其成员数最少为3个的班级 的同学中年龄大于同班同学平均年龄的同学?
MariaDB [hellodb]> select student.name,student.age,student.classid,second.avg_age from (select students.name as name ,students.age as age,students.classid as classid from students left join (select count(name) as num,classid as classid from students group by classid having num>=3) as first on first.classid=students.classid) as student,(select avg(age) as avg_age,classid as classid from students group by classid) as second where student.age>second.avg_age and student.classid=second.classid;
4、统计各班级中年龄大于全校同学平均年龄的同学。
select name,age,classid from students where age > (select avg(age) as a from students);