Mysql学习
- 什么是数据库
数据库是“按照数据结构来组织、存储和管理数据的仓库”。是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。
- 数据库分类
- 关系数据库:Mysql、oracle、SQL server、DB2、SQLL李特
- 非关系数据库(NoSql===》Not Only SQL):redis、MongoDB
- Mysql(https://www.mysql.com/)
- 配置文件在mysql的安装目录下的my.ini
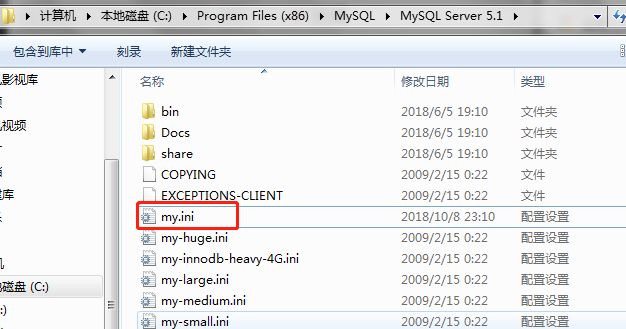
-
- “--”单行SQL的注释、“/* */”多行SQL的注释
- 操作数据库
--创建数据库 create database [if not exists] dataname --删除数据库 drop database [if not exists] dataname --使用数据库 use dataname --查看所有数据库 show databases
- 数据库的列类型
- 数值
TINYINT: 微整型,一个字节, 范围 -128~127
SMALLINT: 小整型,2个字节,范围 -32768~32767
INT: 整型,4个字节
BIGINT: 大整型,8个字节
FLOAT: 单精度浮点型,4个字节,最大3.4e38,可能产生误差
DOUBLE: 双精度浮点型,8个字节,可能产生误差
DECIMAL(M,D): 定点小数,小数点不会变化,几乎也不会产生误差,M代表总的有效数,D代表小数点后的有效位数(工资、价格.....)
BOOL/BOOLEAN: 通常用于存储两个值得数据, TRUE/FALSE。真正存储时 true转为1,FALSE转为0。因为Mysql中没有真正的布尔型,最终会自动转为微整型TINYINT。
-
- 日期时间型
DATE: 日期型 YYYY-MM-DD
TIME: 时间型 HH:mm:ss
DATETIME: 日期时间型 YYYY-MM-DD HH:mm:ss
-
- 字符串型
VARCHAR(M): 变长字符串,不会产生空间浪费,操作速度相对慢,M的最大值为65535
CHAR(M): 定长字符,可能会产生空间浪费,操作速度相对快,往往存储一些固定长度的数据(如手机号码、身份证号等),M的最大值为255
TEXT(M): 大型变长字符串,M的最大值是2G.
-
- null
- 数据库的字段属性(重点)
- unsigned:无符号的整数,不能为负
- zerofill:0填充,不足的0补上
- 自增:在基础上自增1
- 非空:not null
- 默认:如果插入没有值则选择默认值
- mysql的引擎
参考:https://www.cnblogs.com/psyu/p/10883332.html
- mysql数据管理
--插入数据 insert into tablename (xxx,xxx,xxx) values(xxx,xxx,xxx) --查询 select xxx from tablename --删除 delete from tablename where xxx --清空表 truncate table --修改 update tablename where set name=newvalue
- select
-
SELECT [ALL | DISTINCT | DISTINCTROW ] [HIGH_PRIORITY] [STRAIGHT_JOIN] [SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT] [SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS] select_expr [, select_expr] ... [into_option] [FROM table_references [PARTITION partition_list]] [WHERE where_condition] [GROUP BY {col_name | expr | position}, ... [WITH ROLLUP]] [HAVING where_condition] [WINDOW window_name AS (window_spec) [, window_name AS (window_spec)] ...] [ORDER BY {col_name | expr | position} [ASC | DESC], ... [WITH ROLLUP]] [LIMIT {[offset,] row_count | row_count OFFSET offset}] [into_option] [FOR {UPDATE | SHARE} [OF tbl_name [, tbl_name] ...] [NOWAIT | SKIP LOCKED] | LOCK IN SHARE MODE] [into_option] into_option: { INTO OUTFILE 'file_name' [CHARACTER SET charset_name] export_options | INTO DUMPFILE 'file_name' | INTO var_name [, var_name] ... }
-
-
- where
- in
- null
- not null
- having
- like
- join in
- as
- desc
- asc
- order by
- group by
- limit
- 聚合函数
- count()
- sum()
- avg()
- max()
- min()
- 事务(要么都成功,要么都失败)
原子性(Atomicity):原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
一致性(Consistency):事务前后数据的完整性必须保持一致。
隔离性(Isolation):事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
持久性(Durability):持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响
脏读:指一个事务读取了另外一个事务未提交的数据。
不可重复读:在一个事务内读取表中的某一行数据,多次读取结果不同。(这个不一定是错误,只是某些场合不对)
幻读(虚读):是指在一个事务内读取到了别的事务插入的数据,导致前后读取不一致。(一般是行影响,多了一行)
- 索引:简单来说就像一本书的目录
-
- 普通索引:仅加速查询 最基本的索引,没有任何限制,是我们大多数情况下使用到的索引。
- 唯一索引:与普通索引类型,不同的是:加速查询 + 列值唯一(可以有null)
- 全文索引:全文索引(FULLTEXT)仅可以适用于MyISAM引擎的数据表;作用于CHAR、VARCHAR、TEXT数据类型的列。
- 组合索引:将几个列作为一条索引进行检索,使用最左匹配原则。
- 参考:http://blog.codinglabs.org/articles/theory-of-mysql-index.html
- 数据库三大范式
- 第一范式:原子性,属性不可再分
- 第二范式:在1下,属性完全依赖于主键,在一张表只描述一件事
- 第三范式:在2下,每一列只依赖主键