Web Scraping with Python: 使用 Python 爬 CSDN 博客
一、引言
昨天,在实现了使用 Python 对于 GitHub 指定用户的 Star 总数进行爬取的功能之后,我又开始寻找着其他的爬取需求(想要练习爬虫的想法总是隐隐作痒 ^_^)。
想要了解使用 Python 爬取 GitHub 用户的总 Star 数的同学可以观看我的上一篇博客:
Web Scraping with Python: 使用 Python 爬 GitHub Star 数
现在,我想要实现的功能如下:
使用 Python 实现一个爬虫,它可以爬取我的 CSDN 博客,将我的全部博客内容抽取出来写到一个 MarkDown 文件中,以表格的形式显示出来
有了昨天爬取 GitHub 用户的 Star 数的经验,这个问题想来应该不会很难。
那么,让我们开始吧!
二、分析:CSDN 博客的特点
想要爬取 CSDN 博客的内容,需要的就是获取相关的寻找信息。
1. 首先,观察下 CSDN 博客的网址:
// 我的 CSDN 博客首页
http://blog.csdn.net/u012814856
// 我的 CSDN 博客文章列表第二页
http://blog.csdn.net/u012814856/article/list/2 根据这个信息,我们可以实现入口网址的设置。也就是说,每一个 CSDN 用户有一个用户名,我们只需要替换其用户名,就可以实现不同用户的 CSDN 博客的爬取了(这里我的用户名是 u012814856 ,你可以更换成你的)。
2. 然后,观察下 html 中文章列表的特征,这是我抽取的一个文章信息的 html 内容:
<div class="list_item article_item">
<div class="article_title">
<span class="ico ico_type_Original">span>
<h1>
<span class="link_title">
<a href="/u012814856/article/details/78334422">
Web Scraping with Python: 使用 Python 爬 GitHub Star 数
a>
span>
h1>
div>
<div class="article_description">
一、引言很久没写博客了。并不是因为自己变懒惰了,而是自己开始了新的语言 Python 的学习。三个月啃完了英文版的《Head First Python 2nd》,现在又在学习《Web Scraping with Python》了。之所以选择这本书而不是《Python
CookBook》或者《Fluent Python》之类的进阶书籍,是因为我想要尽快的使用实例来锻炼自己使用 Python 的实际编程... div>
<div class="article_manage">
<span class="link_postdate">2017-10-24 20:47span>
<span class="link_view" title="阅读次数">
<a href="/u012814856/article/details/78334422" title="阅读次数">阅读a>(22)span>
<span class="link_comments" title="评论次数">
<a href="/u012814856/article/details/78334422#comments" title="评论次数" onclick="_gaq.push(['_trackEvent','function', 'onclick', 'blog_articles_pinglun'])">评论a>(0)span>
<span class="link_edit">
<a href="http://write.blog.csdn.net/postedit/78334422" title="编辑">编辑a>
span>
<span class="link_delete">
<a href="javascript:void(0);" onclick="javascript:deleteArticle(78334422);return false;" title="删除">删除a>
span>
div>
<div class="clear">div>
div>
从其中可见,每一篇文章都是以 class 属性值为 list_item article_item 的 div 样式呈现的。在这个 div 中,我们可以通过 class 属性值为 link_title 的 span 标签来获取文章标题;可以通过 class 属性值为 link_view 的 span 标签来获取阅读量;可以通过 class 属性值为 link_comments 的 span 标签来获取评论量。
3. 最后,实现多页的跳转。让我们看看下一页按钮的样式是什么:
<a href="/u012814856/article/list/2">下一页a>我们可以通过寻找 text 值为 下一页 的 a 标签来获取到下一页的网址,再在程序中进行遍历直到找不到 下一页 按钮了为止。
至此,我们已经拥有了能够写出这个爬虫的全部信息,在实现之前,我们还需要思考下,如何实现 MarkDown 表格数据的填入。
分析:MarkDown 表格生成
熟悉 MarkDown 的小伙伴一定知道,MarkDown 的表格格式其实非常简单。
我们只需要创建一个后缀为 .md 的文件,然后往里面写入如下格式的文本即可:
| title | content |
| --- | --- |
| 1 | 2 |如果上述文本使用 MarkDown 显示,即可显示成一个表格。
我们可以使用 Python 强大的文本读写能力,使用 with open as 语法简单实现上述功能。
四、代码实现
代码实现过程其实不难,主要就是以下几个需要注意的地方:
1. 异常处理:网址打不开的错误处理,以及找不到标签的错误处理
2. 字符串处理:空白字符去除,特殊字符如 \r\n 去除
接下来,展示我的代码吧:
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
import pprint
userName = input()
info = []
while True:
# 1. Open my blog's first page.
try:
html = urlopen('http://blog.csdn.net/' + userName)
except HTTPError as e:
print('Open ' + 'http://blog.csdn.net/' + userName + ' failed.')
break
# 2. Traverse all the article's information at one page.
bsObj = BeautifulSoup(html)
for article in bsObj.findAll('div', {'class': 'list_item article_item'}):
newArticle = {}
try:
newArticle['title'] = article.find('div', {'class': 'article_title'}).get_text().strip().replace('\r\n', '')
newArticle['view'] = article.find('span', {'class': 'link_view'}) \
.get_text().replace('(', '').replace(')', '').strip()
newArticle['comments'] = article.find('span', {'class': 'link_comments'}) \
.get_text().replace('(', '').replace(')', '').strip()
info.append(newArticle)
except AttributeError as e:
print('Tag not found')
continue
# 3. Move to next page.
nextPage = bsObj.find('a', text='下一页')
if nextPage is not None:
userName = nextPage.attrs['href']
print(userName)
else:
break
with open('record.md', 'w') as record:
record.write('| 文章 | 阅读量 | 评论数 |\n')
record.write('| --- | --- | --- |\n')
for article in info:
record.write('| ' + article['title'] + ' | ' + article['view'] + ' | ' + article['comments'] + ' |\n')
pprint.pprint(info)首先,用户输入自己的 CSDN 用户名(我的是 u012814856)
然后,我将全部数据都存储在了 info 的 list 中,其中每一个文章的信息存储为一个 dict,在这个 dict 中,以键值形式存储了文章的名称、阅读量、评论量信息。
最后,使用 Python 的 with open as 方法拼写了 MarkDown 表格格式,将上述的 info 信息填入了文件中去。
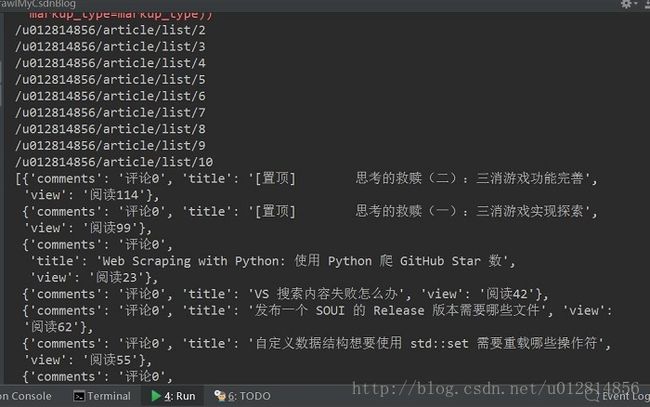
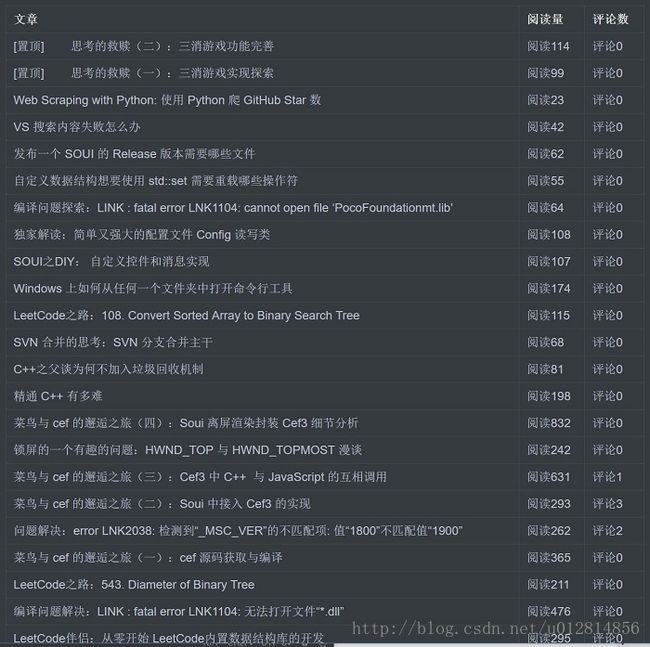
最后的实现效果如下:
控制台输出
MarkDown 文件显示
哈哈,完结撒花:)
五、总结
初学 Python 和爬虫,已经停不下来自己想要疯狂爬取的想法。
Web Scraping 还要继续!
享受编程 :)
To be Stronger !
ps: 想要获取本博客实验工程文件的同学可以点击这里
wangying2016/CrawMyCsdnBlog