数据挖掘中的模式发现(八)轨迹模式挖掘、空间模式挖掘
这是模式挖掘、数据挖掘的一部分应用。
空间模式挖掘(Mining Spatiotemporal Patterns)
两个空间实体之间存在若干拓扑关系,这些关系基于两个实体的位置:
- 分离
- 相交
- 包含

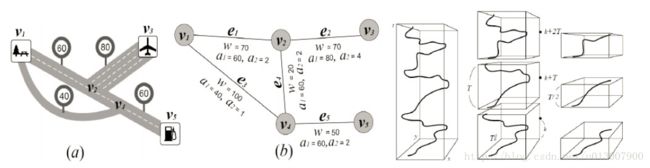
如图所示地表示位置信息,可以提取类似下面的规则:
is_a(x,large_town)⋀intersect(x,highway)→adjacent_to(x,water)[7%,85%]
逐步求精(Progressive Refinement)
我们可以知道语言中有很对二义性的词语,并且可以用不同的词汇表达相同或者相近的意思。
比如,我们表示“靠近”,可以用“临近”、“接近”、“比邻”等等。那么我们就可以用Progressive Refinement来解决,因此空间关系可以应用在一个更加粗糙或者更精细的层次上。
Step 1
粗略计算,用于筛选
使用MBR(Minimum Bounding Rectangle)或者R-tree粗略估计。
Step2
更加细节的处理算法,用于精细处理
只处理那些通过粗略计算的数据(不小于最小支持度),从而节约时间与空间。
共置模式(Colocation pattern)
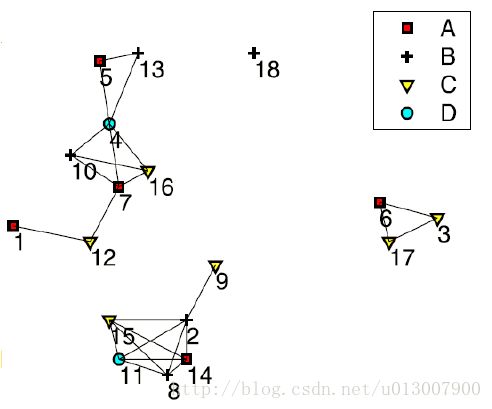
现有如图所示地拓扑结构,用数字表示每一个样本点,其符号是表示样本点的种类。
共置模式指的是一组空间事件或者物体经常发生在相同的区域,在拓扑图中这样的事件用线连在一起。
其中{3, 6, 17}, {4, 7, 10, 16}, {2, 8, 11, 14, 15}, {2, 9}就是一个Colocation pattern。
rowset集合
而rowset(SET)则表示SET集合中每一个元素都出现在的Colocation pattern。
条件概率
Condition Probability
定义如下
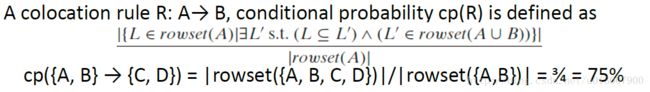
计算条件概率必须按照定义来。
![]() 不是恒等于的。
不是恒等于的。
例如,求 cp(A→B) 。
其中 Rowset(A)={1,5,6,7,14} , Rowset({A,B}) 如上文的例子。
在 Rowset({A,B}) 中包含14的有两个元素,但是根据定义也只能计算一次。
所以 cp(A→B)=35
Participation Ratio
定义如下
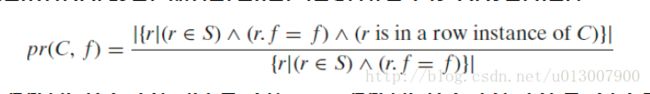
Participation ratio pr(C,f) : probability that C is observed in a neighbor-set wherever feature f is observed。
表示在 f 发生的情况下,有多少情况是在 C 情况下发现的。(注意,我这不是原原本本地翻译,但是应该是等价的翻译。)
例如,
我们可以看到总共有 5 个 A ,但是只有 2 个 A 发生在 {A,B,C,D} 的情况下。
类Apriori算法
算法思想和Apriori算法是一致的。
产生候选集的理论依据是Participation Ratio的单调性:
现有两个Co-location pattern: C′ 和 C ,且 C′⊂C ,那么对于任意 f ,我们都可以得到 pr(C′,f)≥pr(C,f) 。
轨道模式挖掘(Mining and Aggregating Patterns over Multiple Trajectories)
轨迹的挖掘任务
轨迹聚类:基于空间/时空的几何估计进行分组
轨迹联合:给定两个轨迹数据库,检索所有的相似对
通过挖掘能够处理多种问题,包括,路线规划、城市规划、识别物体、模式分类。
基本定义
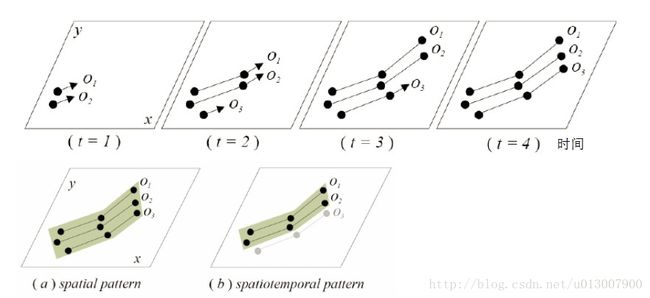
基本运动模式
描述移动事件,不考虑绝对位置
- Constance:连续时间序列的相等运动属性,即保持运动方向不变
- Concurrence:有相等运动属性的多个对象,在某个时刻运动方向相同的多个物体
- Trendsetter:—组的共享目标的运动图形(constance + concurrence)
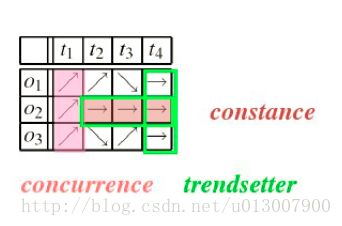
上图中箭头表示运动方向,横坐标表示时间,纵坐标表示物体。
空间运动模式
基本运动模式+空间约束
- Track:单个对象,保持相同运动(constance + 空间约束)
- Flock:一组对象,同时保持相同运动(concurrence + 空间约束)
- Leadership:—个领导,踉着一组具有相同的运动物体(trendsetter + 空间约束)

- Flock(m,k,r):在半径r内,m个对象,k个连续点
- Meet(m,k):至少m个对象,在半径r内,至少K个连续点
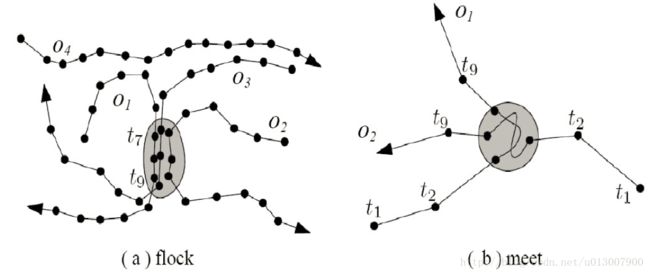
聚合/分离运动模式
描述聚合和分离对象的运动
- Encounter(m,r) : 至少m个对象同时到达半径为r的范围内
- Convergence (m,r) : 至少m个对象经过达半径为r的范围内(不需要同时)
- Divergence : 与Convergence相反
- Breakup : 与Encounter相反
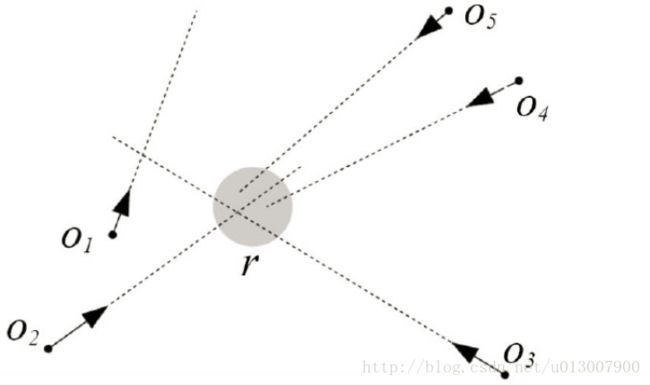
基于密度的轨迹模式
- TRACLUS
- 密度相连轨迹段的聚类
- 不考虑时间
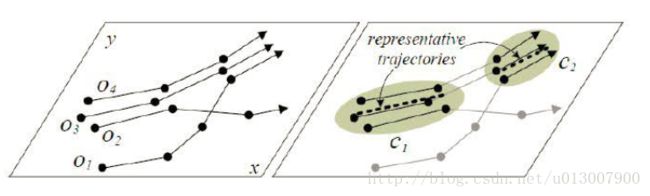
Moving Cluster
- 在一个时间段内,一组对象相互靠近
Convoy
- 基于密度链接的 “Flock (m,k,r).”
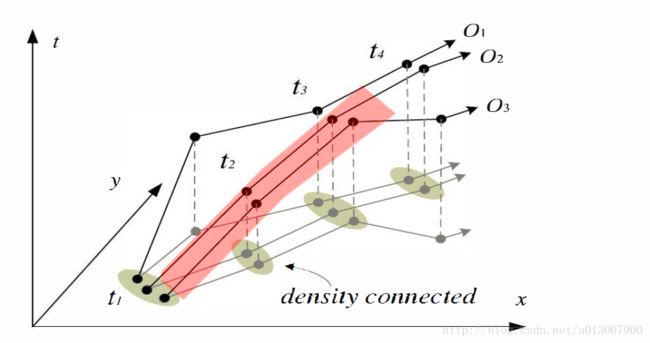
- Swarm
- Time-relaxed convoy. 对象在时间上的倒数
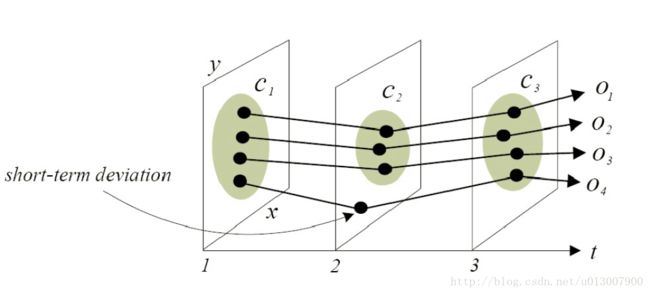
挖掘语义丰富的运动模式(Mining Semantics-Rich Movement Patterns)
- 频繁移动模式:频繁出现在输入轨迹数据库中的移动序列
- 频繁移动模式与频繁连续模式:
- 两者都旨在从输入序列数据库找到频繁的子序列
- 对于挖掘频繁运动模式,类似地方(例如下图右图以功能分类)可能需要分组以共同形成频繁子序列
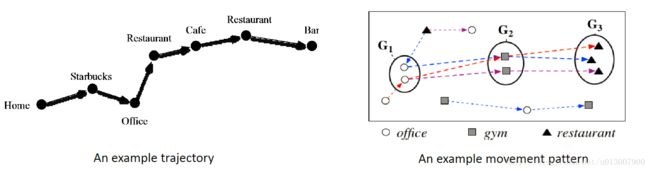
- 语义丰富的运动模式:
- 除了知道人们如何移动,从一个地区到另一个地区,我们也想了解地区的功能
- 例如,office和home可能是在相同的地方,有着相同的功能;也可能在不同的地方,有着不同的功能。如上图左图所示。
Step1
找到一组反映人们粗糙的语义级转换的模式。例如,办公室→餐馆,家庭→健身房。
粗糙的语义在之前讲的progressive refinement中说过,是一些粗糙的语义定义,比如,办公室、办公场所,甚至是一些更加具体的名词,如政府办等。
Step2
通过分组,将每个粗糙分类的相似图案分成几个细粒度图案运动片段。
论文:C. Zhang et al., Splitter: Mining Fine-Grained Sequential Patterns in Semantic Trajectories, VLDB 2014