zookeeper在大数据生态的应用
- 一、简述
- 二、基本概念
- 1.数据结构
- 2.Znode你应该了解的
- (1)节点类型
- (2)节点属性
- 三、基本功能
- 1.文件系统
- 2.集群管理
- (1) 节点的加入和退出
- (2) Master的选举
- 3.分布式锁机制
- (1) 排他锁
- (2) 共享锁
- 4.监听与通知机制
- 四、实际应用
- 1.hadoop
- 2.hbase
- 3.kafka
- 4.hive
- 五、总结
一、简述
在一群动物掌管的世界中,动物没有人类聪明的思想,为了保持动物世界的生态平衡,这时,动物管理员—zookeeper诞生了
打开Apache zookeeper的官网,一句话定义zookeeper:Apache ZooKeeper致力于开发和维护可实现高度可靠的分布式协调的开源服务器。
zookeeper是个服务,服务的对象我们都成为客户端,在大数据生态里面的客户,hadoop、hbase、hive…组件都是分布式部署,这些组件们利用zookeeper的服务做了一些维持自身平衡的事情,比如集群管理、master选举、消息发布订阅、数据存储、分布式锁等等。作为整个集群的心脏的存在,zookeeper本身也是分布式,只有在分布式的基础上才能实现高度可靠,否则任何单点的可靠都是在耍流氓。
二、基本概念
1.数据结构
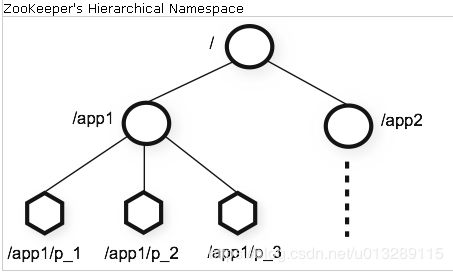
直观的一看,zk的数据结构类似一颗树,所有的节点都称为znode,所有带子节点的znode也就是图中的圈圈,我们都可以通俗理解为linux系统的目录,最底层的znode,也就是图中的菱形,可以理解为文件。通过zookeeper可视化客户端ZooInspector可以清晰地看到里面的目录文件结构
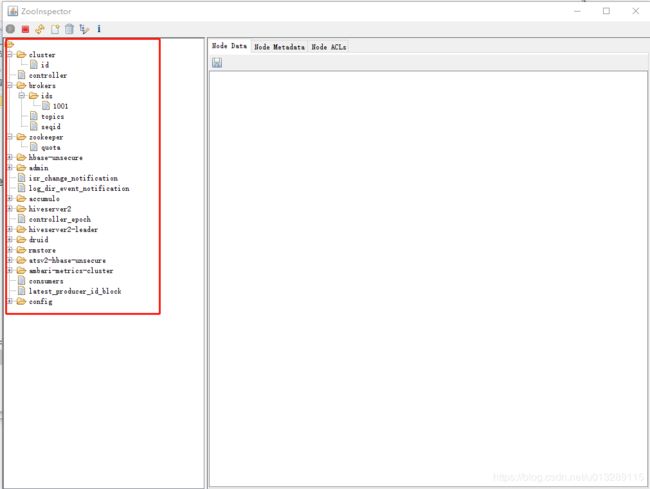
通过客户端,我们既能直观的看到zk内部的目录结构,可以直观的判断哪些组件用到了zk,看到一些熟悉的身影。
2.Znode你应该了解的
(1)节点类型
Znode 分为两种:
- 临时节点:该节点的生命周期依赖于创建它们的会话。一旦会话结束,临时节点将被自动删除,当然可以也可以手动删除。 临时节点不允许拥有子节点。
- 永久节点:该节点的生命周期不依赖于会话,并且只有在客户端显示执行删除操作的时候,他们才能被删除。
Znode还有一个有序的特性,直白的说,当你创建一个节点名的时候,zk会总动在节点名后面加一串10位的数字,比如0000000001,来操作一遍。在安装了zk机器上执行zookeeper-client进入zk命令行
# -s表示创建有顺序节点,这里创建的节点是/diaozhatian,创建的znode名自动添加了后缀序号0000000037
[zk: localhost:2181(CONNECTED) 2] create -s /diaozhatian aaaaaa
Created /diaozhatian0000000037
# 所以获取数值的时候也要用全名/diaozhatian0000000037获取
[zk: localhost:2181(CONNECTED) 5] get /diaozhatian0000000037
aaaaaa
#下面是默认情况下创建永久节点和获取数据的方法
[zk: localhost:2181(CONNECTED) 3] create /diaozhadi bbbbbbbb
Created /diaozhadi
[zk: localhost:2181(CONNECTED) 6] get /diaozhadi
bbbbbbbb
这样便会存在四种类型的 Znode 节点, 分别对应:
| Znode节点类型 | 说明 |
|---|---|
| PERSISTENT | 永久节点 |
| EPHEMERAL | 临时节点 |
| PERSISTENT_SEQUENTIAL | 有序的永久节点 |
| EPHEMERAL_SEQUENTIAL | 有序的临时节点 |
(2)节点属性
每个 znode 都包含了一系列的属性,通过命令 get, 可以获得节点的属性。
# -s -e 参数表示创建一个有序的临时节点
[zk: localhost:2181(CONNECTED) 7] create -s -e /niubility 666
Created /niubility0000000039
# 获取数据和属性
[zk: localhost:2181(CONNECTED) 8] get /niubility0000000039
666 # 节点数据
cZxid = 0x70159 # Znode 创建的事务 id
ctime = Sun Apr 05 10:59:45 CST 2020 # 节点创建时的时间戳
mZxid = 0x70159 # Znode 被修改的事务 id
mtime = Sun Apr 05 10:59:45 CST 2020 # 节点最新一次更新发生时的时间戳
pZxid = 0x70159 # 该节点的子节点(或该节点)的最近一次 创建/删除对应
cversion = 0 # 子节点的版本号。当 znode 的子节点有变化时, cversion 的值就会增加 1
dataVersion = 0 # 数据版本号,每次对节点进行 set 操作, dataVersion 的值都会增加 1
aclVersion = 0 # ACL 的版本号
ephemeralOwner = 0x17147dcc5e3001d # 如果该节点为临时节点, ephemeralOwner 值表示与该节点绑定的 session id. 如果不是, ephemeralOwner 值为 0
dataLength = 3 # 数据长度,上面是666,所以这里是3
numChildren = 0 # 子节点个数
三、基本功能
1.文件系统
文件系统是干嘛的?存数据用的。zk既然有文件系统的功能,自然就少不了数据的存储和管理。zk和 linux 的文件系统很像,也是树状,这样就可以确定每个路径都是唯一的。但是Znode又跟linux不一样,严格来说,zk的带有子节点的Znode不能当成目录,因为zk的所有Znode不管父子节点都能带数据,但linux的目录不能,所以zk里面的路径不能叫文件夹也不能叫文件,统一称为Znode,上代码来比较直观的理解下:
[zk: localhost:2181(CONNECTED) 2] create /father zhangsan
Created /father
[zk: localhost:2181(CONNECTED) 4] create /father/child lisi
Created /father/child
[zk: localhost:2181(CONNECTED) 5] get /father
zhangsan
[zk: localhost:2181(CONNECTED) 6] get /father/child
lisi
可以清晰地看到不论是父子节点,都可以存放数据。要注意的是,Zookeeper Server启动时会把所有Znode加载进内存,所以zk不适合存储太大的数据,否则造成oom,作为心脏停止跳动,后果不堪设想!后面会专门写一篇文章记录一次线上事故
zookeeper的文件系统的特点:
- zk的文件系统和Linux的文件系统目录结构一样,从”/“开始
- zk的访问路径只有绝对路径,没有相对路径。
- zk中没有文件和目录的概念,只有znode节点,Znode既有文件的功能,又有目录的功能
2.集群管理
在大数据生态中,各种各样的集群需要zk维护,zk做集群管理的功能无非就两个:
(1) 节点的加入和退出

首先,在zk中创建持久节点 /GroupMembers 作为父节点,父节点监听子节点的变化,client通过注册到zk,会在/GroupMembers下创建临时节点,临时节点的特性时当客户端与zk断开连接时会自动删除,不论是创建和删除,zk server都会监听,通过Watcher监听与通知机制,并且会把变动的结果通知到到其它client,这样,其它所有client都知道了其它兄弟们的存活情况
(2) Master的选举
有很多应用都是master-slave架构,master必须7*24小时工作,但是每次只能一个master在工作,这时需要一个选举机制,确定一个active状态的master,当active的master出现故障挂掉的时候,standby的master顶上去,这里主要讲zk这端的实现。Master选举的功能,其实就是各个master注册到zk的目录下,创建临时节点,成功在zk创建临时节点的目录,也就被选举为Master,其它备用的Master就会收到监听zk里面临时节点的变化,一旦删除,就会争夺创建临时节点的权利成为新的Master。
本质其实是利用zookeeper的临时节点的特性:临时节点随着会话的消亡二消亡,同一个临时节点只能创建一个,创建失败的节点(从master)对创建成功节点(主master)进行监控,一旦创建成功的节点(主master)会话消失,之前创建失败的节点(从master)就会监听到去抢夺创建临时节点
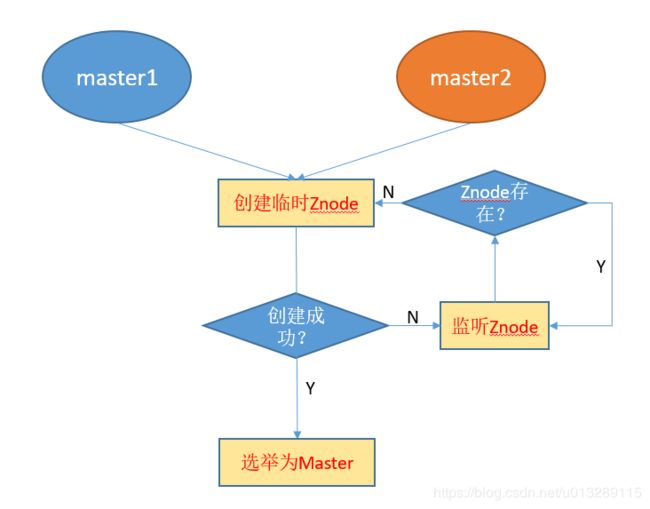
如上图,master1和master2为争夺上位之战,都试图在zk里面创建一个临时的Znode,但是同一个路径只能创建一次,先创建的那个被选举为Master,未创建成功的则订阅监听Znode是否存在,如果不存在,则上位成Master。上图用的是排他锁,共享锁用的是后面10位数字最小的那个作为获取锁的节点,原理都差不多,先到先得的原则。下面会具体讲这两种锁。
3.分布式锁机制
锁的定义:用于多线程环境下控制只有一个线程可以访问某一个资源,不能多个线程同时访问,锁旨在强制实施互斥排他、并发控制策略。
分布式锁的定义:在分布式系统中,应用可能部署在多台机器上,应用不在同一个jvm里面,这个时候还需要维护一个互斥排他的策略,需要一个跨jvm的锁同步,为了解决跨系统、跨jvm的锁,我们就必须引入分布式锁。
这里要搞清一个概念,所谓锁,并不是一个实际的对象或代码层面抽象存在的一种东西,锁是一种策略,这里初学者很容易搞混
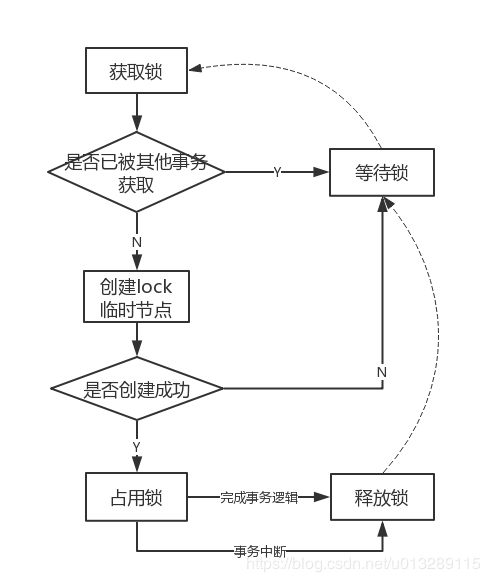
(1) 排他锁
排他锁,又称写锁或独占锁。如果事务T1对数据对象O1加上了排他锁,那么在整个加锁期间,只允许事务T1对O1进行读取或更新操作,其他任务事务都不能对这个数据对象进行任何操作,直到T1释放了排他锁。
排他锁核心是保证当前有且仅有一个事务获得锁,并且锁释放之后,所有正在等待获取锁的事务都能够被通知到。
Zookeeper 的强一致性特性,能够很好地保证在分布式高并发情况下节点的创建一定能够保证全局唯一性,即Zookeeper将会保证客户端无法重复创建一个已经存在的数据节点。可以利用Zookeeper这个特性,实现排他锁
(2) 共享锁
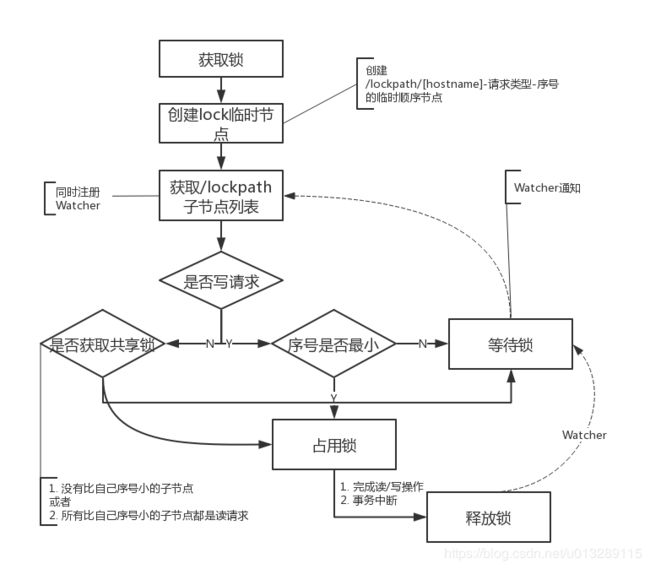
共享锁,又称读锁。如果事务T1对数据对象O1加上了共享锁,那么当前事务只能对O1进行读取操作,其他事务也只能对这个数据对象加共享锁,直到该数据对象上的所有共享锁都被释放。
共享锁与排他锁的区别在于,加了排他锁之后,数据对象只对当前事务可见,而加了共享锁之后,数据对象对所有事务都可见
4.监听与通知机制
Watcher机制官方解释:一个Watch事件是一个一次性的触发器,当被设置了Watch的数据发生了改变的时候,则服务器将这个改变发送给设置了Watch的客户端,以便通知它们。
其实上面描述的很多功能都用到了watcher机制,比如master选举的Znode监听,当备用的master发现Znode已经被其它master创建后,这是备用master会注册监听这个Znode的变化。还有锁机制,毋庸置疑,也是基于监听机制上才能实现,比如释放锁的时候,需要告诉其它访问的应用这个Znode代表的锁已经释放,通知其它应用可以获取锁以进行下一步操作。
Watcher机制的特点:
- 注册的监听是一次的,如果你还需要监听第二次,那么就要重新注册。数据发生改变时,一个watcher event会被发送到client,但是client只会收到一次这样的信息
- watcher event异步发送 watcher 的通知事件从server发送到client是异步的
四、实际应用
1.hadoop
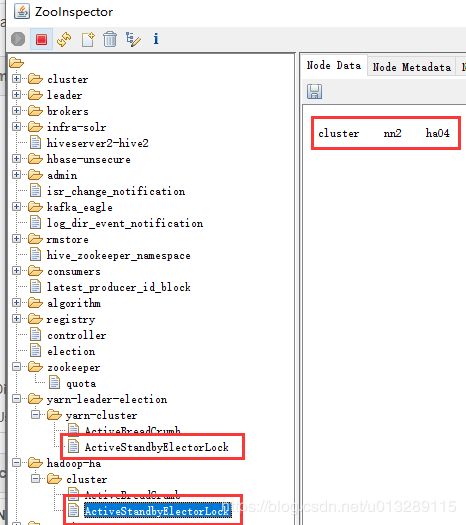
Hadoop HA:不论是namenode的HA或是yarn的HA,都通过zkfc机制来选举控制只有一个active状态的namenode和resourcemanager在工作,这里通过上面描述的master的选举功能,采用的是排他锁完成的选举,我们通过zk可视化客户端可以清晰地看到上图Znode的结构,yarn和hdfs的路径下各有一把锁的标记文件,同时文件的内容也带有active节点的信息。
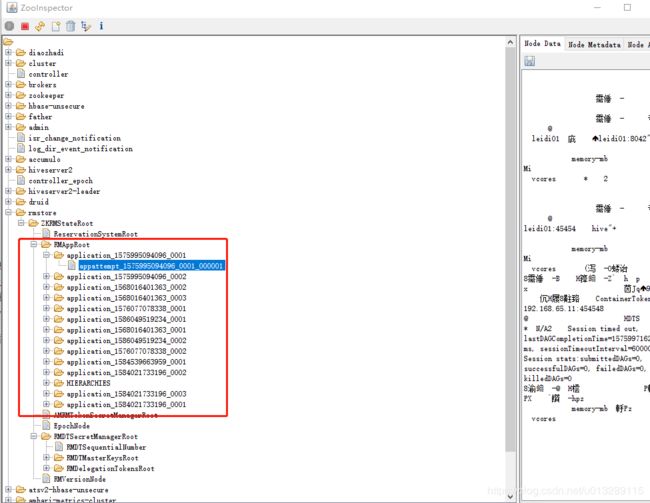
yarn application容错:在yarn上跑任务时,所有application启动时都会把application的信息写入zk里面,右边是写入的一堆序列化的二进制信息,假如这时active状态的resourcemanager突然挂了,standby的转换成active状态后会接管挂之前的application,这样resourcemanager主从的切换对正在yarn运行的application不影响。
yarn的容错机制也带来一系列问题:
- 一个spark任务在yarn运行突然失败了,默认会重试,重试前会把上一次的driver端的信息写入zk,这时如果driver端的数据太大,比如你代码里broadcast一个很大的文件,这样很容易把zk写满写挂,直接导致zk不能工作,zk停止工作直接的代价是整个集群不能正常工作,简直毁灭性的代价,有幸经历过一次,后续会整理博客发出来
- 如上图的application的信息存放在zk里面是持久化的节点,不会自动删除,当yarn的历史任务运行太多的时候,zk里面会存一堆的application的历史信息,导致zk的内存占用越来越大,也影响性能,需要写脚本手工清除
2.hbase
zk在hbase应用的功能主要两个:
- hbase regionserver 向zookeeper注册,提供hbase regionserver状态信息(是否在线),HMaster通过watcher监听regionserver的存活情况,并不是HMaster跟Regionserver通过心跳机制检测。
- HMaster启动时候会将hbase系统表-ROOT- 加载到 zookeeper cluster,通过zookeeper cluster可以获取当前系统表.META.的存储所对应的regionserver信息
zookeeper是hbase集群的"协调器"。由于zookeeper的轻量级特性,因此我们可以将多个hbase集群共用一个zookeeper集群,以节约大量的服务器。多个hbase集群共用zookeeper集群的方法是使用同一组ip,修改不同hbase集群的"zookeeper.znode.parent"属性,让它们使用不同的根目录。比如cluster1使用/hbase-c1,cluster2使用/hbase-c2,等等
3.kafka
zk在kafka的应用功能主要三个:
- broker的注册:我们上面描述的zk一个基本的功能是做集群的管理,所有broker会把自己的id号注册进zk的Znode里面,通过事件监听的机制,各个broker之间都知道所有兄弟的存活情况。当有broker启动时,会在zk里面创建Znode,并通知其它broker;当有broker下线或挂掉时,同样会通知其它broker。
- topic的注册:当topic创建时,kafka会把topic的name、partition、leader、topic的分布情况等信息写入zk里面,当broker退出时,会触发zookeeper更新其对应topic分区的isr列表,并决定是否需要做消费者的负载均衡
- consumer的注册:当有新的消费者消费kafka数据时,会在zk中创建Znode保存一些信息,节点路径为ls /consumers/{group_id},其节点下有三个子节点,分别为[ids, owners, offsets]。在常用的offset的维护中,应用消费kafka数据时要设置参数enable.auto.commit为true才会自动更新offset
4.hive
zk在hive的应用主要两个:
- hiveserver2的选举:在上面的namenode选举中用的是排他锁,而hiveserver2用的锁是共享锁,如下图

可以看到有两个节点在zk中注册,会创建有序的临时节点,每个Znode都有一串数字后缀,zk默认是同一个锁路径下id最小的那个znode获取锁,也就是上图中的后缀000000228所代表的hiveserver2节点是主的状态,假如这个节点挂了,这个znode会自动删除,watcher机制会通知另一个hiveserver2上位
- 表数据锁:Hive 锁机制是为了让 Hive 支持并发读写的原子性而设计的 特性,比如,一个sql在insert数据,这时需要锁住表,不让其它sql去读取表数据,否则会有问题。等到释放锁之后,也就是insert完了其它客户端才能读取这个表,hive表的锁机制非常有必要,通过
hive.support.concurrency=true来开启,后面打算专门一节来讲hive的锁机制,这里就不详述了。
五、总结
今天浅谈了一下zookeeper的基础知识点和在大数据的基本应用,其实zk的应用非常广,还有比如统一的命名空间、做配置中心等等功能这里没讲。总之zk是专门为分布式服务而生的,强大的协调能力为大数据生态提供了强大的后勤保障。在后面的章节里,我会把zk结合大数据的具体应用和才过的一些坑跟大家分享,让大家知道zk的重要性,毕竟zk是大数据的心脏!