MnasNet 神经网络简介与代码实战
1.介绍
MnasNet是由Google大脑AutoML组所提出的,以运算时长为优化目标来搜索网络结构,同时模型要能平衡精确度和运算时长。更加详细的介绍可以参见:MnasNet: Platform-Aware Neural Architecture Search for Mobile
2.模型结构
下图中的可分离卷积可参考我的一篇博客(MobileNets V1神经网络简介与代码实战)
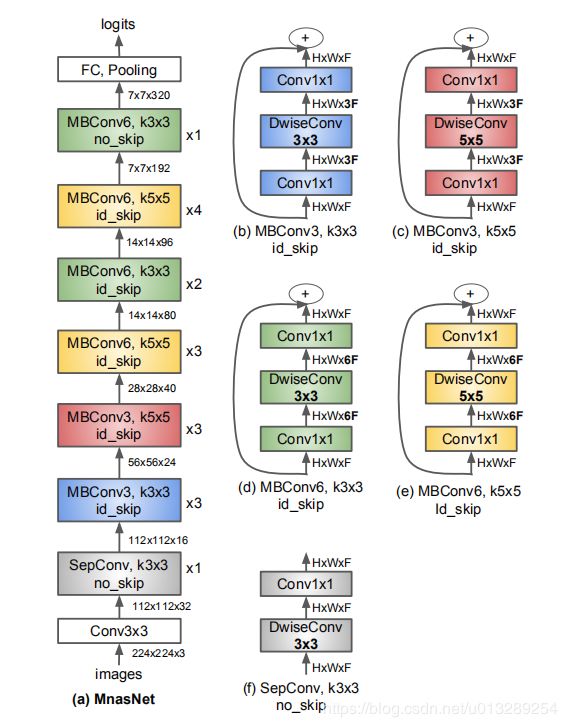
3.模型特点
(1)在depthwise convolution中,5X5卷积核的效果要优于两个3X3的卷积核
(2)层分级的重要性。很多轻量化模型重复 block 架构,只改变滤波器尺寸和空间维度。论文提出的层级搜索空间允许模型的各个 block 包括不同的卷积层。通过比较 MnasNet 的各种变体(即单独重复使用各个 block),在准确率和实时性方面难以达到平衡,验证了层分级的重要性。
4.代码实现 pytorch
def Conv_3x3(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU6(inplace=True)
)
def Conv_1x1(inp, oup):
return nn.Sequential(
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU6(inplace=True)
)
def SepConv_3x3(inp, oup): #input=32, output=16
return nn.Sequential(
# dw
nn.Conv2d(inp, inp , 3, 1, 1, groups=inp, bias=False),
nn.BatchNorm2d(inp),
nn.ReLU6(inplace=True),
# pw-linear
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
class InvertedResidual(nn.Module):
def __init__(self, inp, oup, stride, expand_ratio, kernel):
super(InvertedResidual, self).__init__()
self.stride = stride
assert stride in [1, 2]
self.use_res_connect = self.stride == 1 and inp == oup
self.conv = nn.Sequential(
# pw
nn.Conv2d(inp, inp * expand_ratio, 1, 1, 0, bias=False),
nn.BatchNorm2d(inp * expand_ratio),
nn.ReLU6(inplace=True),
# dw
nn.Conv2d(inp * expand_ratio, inp * expand_ratio, kernel, stride, kernel // 2, groups=inp * expand_ratio, bias=False),
nn.BatchNorm2d(inp * expand_ratio),
nn.ReLU6(inplace=True),
# pw-linear
nn.Conv2d(inp * expand_ratio, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
if self.use_res_connect:
return x + self.conv(x)
else:
return self.conv(x)
class MnasNet(nn.Module):
def __init__(self, n_class=1000, input_size=224, width_mult=1.):
super(MnasNet, self).__init__()
# setting of inverted residual blocks
self.interverted_residual_setting = [
# t, c, n, s, k
[3, 24, 3, 2, 3], # -> 56x56
[3, 40, 3, 2, 5], # -> 28x28
[6, 80, 3, 2, 5], # -> 14x14
[6, 96, 2, 1, 3], # -> 14x14
[6, 192, 4, 2, 5], # -> 7x7
[6, 320, 1, 1, 3], # -> 7x7
]
assert input_size % 32 == 0
input_channel = int(32 * width_mult)
self.last_channel = int(1280 * width_mult) if width_mult > 1.0 else 1280
# building first two layer
self.features = [Conv_3x3(3, input_channel, 2), SepConv_3x3(input_channel, 16)]
input_channel = 16
# building inverted residual blocks (MBConv)
for t, c, n, s, k in self.interverted_residual_setting:
output_channel = int(c * width_mult)
for i in range(n):
if i == 0:
self.features.append(InvertedResidual(input_channel, output_channel, s, t, k))
else:
self.features.append(InvertedResidual(input_channel, output_channel, 1, t, k))
input_channel = output_channel
# building last several layers
self.features.append(Conv_1x1(input_channel, self.last_channel))
self.features.append(nn.AdaptiveAvgPool2d(1))
# make it nn.Sequential
self.features = nn.Sequential(*self.features)
# building classifier
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(self.last_channel, n_class),
)
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = x.view(-1, self.last_channel)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
n = m.weight.size(1)
m.weight.data.normal_(0, 0.01)
m.bias.data.zero_()