如何在基于kafka和ELK stack的日志分析系统中进行流量控制
-
- 为什么需要做流量控制
- 没执行流控之前的流量情况
- 如何通过kafka做流量控制
- 执行kafka流控之后的流量情况
- 注意事项
为什么需要做流量控制
在搭建日志分析系统时,运维人员最担忧的问题之一,就是部署在生产服务器上的日志采集单元是否会过度侵占本该属于生产应用的系统资源。具体来说,就是cpu,内存和网络资源。特别是在当前虚拟机或云大行其道,多个虚拟机,或者docker镜像会共用cpu和网卡的情况下,更应该注意控制辅助应用对整个系统资源的使用情况。
这篇文章主要是针对网络消耗的,因为多个虚机会共用物理机上的网卡,首先网络带宽就是被共用的。如果日志分析系统监控的是web应用主入口,或者资源访问入口等对网络资源消耗比较大的应用系统,并且这些系统产生的日志量也很大,由于filebeat到kafka的连接默认上是不受限制的(系统有多少资源,能传多快就多快),如果不做限制,有可能会多产生非常高的数据吞吐,造成网络饱和,并DOS掉其他client的网络连接。。。具体还是来看例子。
没执行流控之前的流量情况
首先,在没有进行流量控制的时候,看看filebeat对网络的使用情况。
这里的基线是:
- filebeat所在的应用服务器是2c4g的配置
- filbeat被配置为只使用一个cpu
- filebeat和kafka服务器在同一个内网内
- 100M的网卡
- filebeat不做任何关于log的预处理,直接发送log
测试结果:
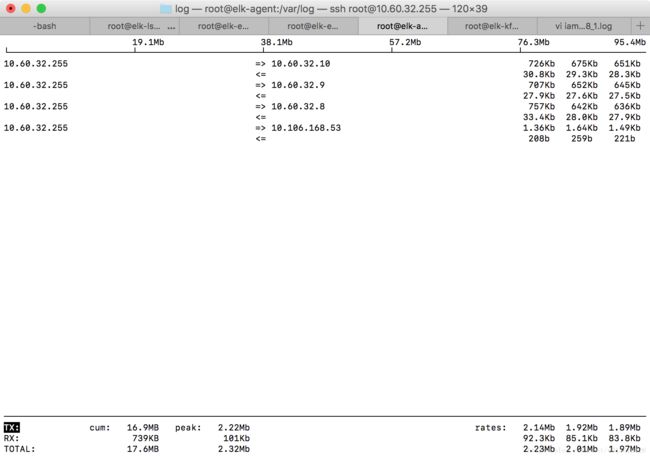
这里是通过iftop命令获取的数据。
可以看到,filebeat和kakfa所有的三个节点建立了链接(10.60.32.8/9/10)。每个节点的平均发送速率(三个值分别是2s/10s/40s,取40s内的平均速率)在650Kb左右。总的带宽使用是1.89Mb/s.
如何通过kafka做流量控制
从0.9版本开始,kafka集群新增了针对生产和消费请求进行配额(quotas)控制的能力。Quota基本上是一个单client-id的数据byte速率的门槛值的概念。逻辑上一个client-id代表了一个产生请求的应用程序。一个client-id理论上可以拥有多个producer或者consumer实例,qouta会把这些实例当做一整个个体来对待。假如一个client-id为“test-client”的程序quota设置为10MB/s,拥有相同id的实例会共享这个配额。
默认情况下,每一个单独的client-id对应一份集群配置的固定quta速度(默认配置在quota.producer.default, quota.consumer.default)。quota是一个被定义到每台broker粒度的概念。每个client在达到限速前可以与单台broker产生最大为X bytes/sec的写/读流量请求。决定将quota定义到每台broker粒度比设置一个固定的全集群粒度的带宽概念更合适,这样可以省去一个在集群broker间协调quota的机制。这个协调机制可能比quota机制本身的实现更为麻烦!
broker在发现超出quota的情况下会如何处理?kafka目前的处理方法是,broker并不会返回错误信息而是会尝试降低客户端的速度。broker计算出将客户端速度限制在quota以下需要的delay时间然后在response时先delay这么多时间再响应。这种机制基本实现将quota限速功能对客户端透明化(无需客户端一侧的配置),同时也避免了客户端需要实现的复杂麻烦的backoff和retry的逻辑。事实上,异常的客户端行为(没有回退机制的重试)可能将quota想要解决的问题更加恶化。
那么如何设置quota?
当然,你也可以通过server.properties文件进行设置,方法是增加两个参数:(下例是将值设为10MB/s)
quota.producer.default=10485760
quota.consumer.default=10485760但在最新的1.0版本的kafka文档中,已经说明,这两个参数已经是deprecated,在将来会被去掉。
对quota进行配置的最通用的方法是通过kafka-config.sh进行配置,具体配置文档的链接。
执行kafka流控之后的流量情况
在kafka的服务器上执行如下操作:
bin/kafka-configs.sh --zookeeper 10.60.32.10:2181 --alter --add-config 'producer_byte_rate=24857,consumer_byte_rate=24857,request_percentage=200' --entity-type clients --entity-default将producer的速率限制为24857bytes/s,也就是195Kb/s左右。
再重复通过iftop进行测量,结果如下:
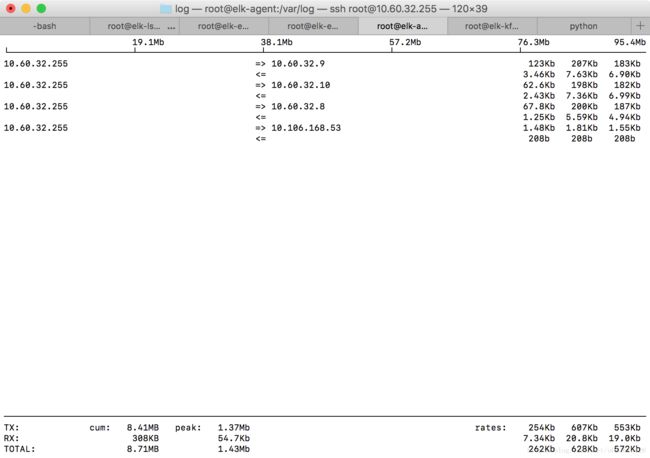
可以看到40s的平均输出带宽降为了553Kb/s。限流生效。
另外,我们可以通过zookeeper的配置进行查看配置值是否生效:
[zk: 10.60.32.10:2181(CONNECTED) 8] get /config/clients/
{"version":1,"config":{"request_percentage":"200","producer_byte_rate":"24857","consumer_byte_rate":"4194304"}}
cZxid = 0x1000002c6
ctime = Thu Nov 30 09:23:49 CST 2017
mZxid = 0x1000002dc
mtime = Thu Nov 30 09:52:50 CST 2017
pZxid = 0x1000002c6
cversion = 0
dataVersion = 5
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 111
numChildren = 0 注意事项
可能细心的朋友会观测到一个奇怪的值,峰值带宽(peak)是1.37Mb。原因是之前提到过的,broker计算出将客户端速度限制在quota以下需要的delay时间然后在response时先delay这么多时间再响应。这个是对平均速率的限制,而不是对峰值进行限制。
另外一个情况是,当我们在filebeat中配置了多个kafka hosts之后,filebeat和kafka集群之间其实是建立了多个链接的。而quota的配置是针对单个broker的。也就是说,当我们把producer的速率配置为250KB/s时,是指和单个kafka borker之间的速率链接上限是250KB/s。filebeat是默认开了负载均衡的,会把log平均分配到多个kafka broker。如果filebeat连接了3个kafka broker,则总带宽可能是250KB/s * 3 = 750KB/s。所以,当你决定限速的时候,一定要考虑到:
- filebeat允许占用的最大带宽
- kafka单点的producer速率
- kafka集群的大小。
filebeat允许占用的最大带宽 > kafka单点的producer速率 * kafka集群的大小