一款实用延迟队列的自研历程
文章原创作者:北京哗啦啦 基础架构部架构师 王晓鹏
文章推荐人:程超
一、背景
一款技术产品必定有其使用场景,不然代码写的再好也没有用武之地,那么首先我们要先来了解一下,在什么情况下会用到延迟队列呢?
- 当订单一直处于未支付状态时,如何及时的关闭订单,并退还库存?
- 如何定期检查处于退款状态的订单是否已经退款成功?
- 新创建店铺,N天内没有上传商品,系统如何知道该信息,并发送激活短信?等等
以上业务场景均可以使用延迟队列来解决。
二、名字解释
延迟队列
顾名思义,就是延迟消费的队列。队列中存储的对象肯定是对应的延时消息,所谓“延时消息”是指当消息被发送以后,并不想让消费者立即拿到消息,而是等待指定时间后,消费者才拿到这个消息进行消费。
三、目前现有实现方案:
1、数据库轮询
思路是创建一张任务表,表中保存将要执行的任务,执行时间,以及状态。
执行任务的机器来轮询这个表,寻找新建状态且run_time_millis小于当前时间戳的任务,然后将其修改为开始状态,若成功改为开始状态则执行任务,任务执行成功后修改为成功,若失败且没有超出任务执行最大次数则增加sequence字段并将任务改为新建状态,同时将run_time_millis修改为任务下次要执行的时间,若失败且超出最大执行次数则将任务状态改为失败状态。
优点是简单可靠,缺点时需要轮询,浪费cpu。
2、redis zset
利用redis的zset数据结构。
score使用任务时间戳,轮询是按照小于当前时间的范围去选择。
3、java DelayQueue
java中的DelayQueue同样可以作为单JVM的延迟队列。
优点: 不引入其他服务依赖,wait-notify机制,不做polling,不会浪费cpu。
缺点: 数据保存在JVM内存中,当应用重启会造成数据丢失,或者数据量大时造成DelayQueue过大。
4、RabbitMQ 死信队列
rabbitmq本身是不支持延迟队列的,但是利用ttl 以及DLE (Dead Letter Exchanges)可以模拟出延迟队列。
我们公司之前一直使用这种方式,但是使用时有一些坑儿,比如:每个延迟时间需要单独一个队列(5分钟延时是一个,10分钟延迟是另外一个)。除此以外,使用较复杂,对开发者有一定的要求。
总结
我们考察了现有的延迟队列实现,基于有赞队列的实现方案—使用redis zset作为队列存储结构,同时结合了java DelayQueue的wait-notify方式,重新实现了一套延迟队列。
四、自研新方案
客户端将一个需要延迟执行的任务,发布到该队列,时间到了以后,即可执行该任务。

1、设计要点
基本概念
- Job:需要异步处理的任务,是延迟队列里的基本单元。与具体的Topic关联在一起。
- Topic:一组相同类型Job的集合(队列)。供消费者来订阅。
- delayJob:延迟执行的任务。
- FailedDelayJob:delayJob执行失败后,会转化为FailedDelayJob进行重试,重试的job叫做FailedDelayJob。
消息结构

消息结构字段含义:
- Topic:参考上文定义。
- Id:Job的唯一标识。用来检索和删除指定的Job信息。
- Delay:Job需要延迟的时间。单位:秒。(服务端会将其转换为绝对时间)
- Body:Job的内容,供消费者做具体的业务处理,以json格式存储。
- callBack:回调接口地址。使用http协议,该地址是一个url。
存储结构

状态转换说明:
1、客户端publish一个job,首先会被保存到delayQ中,此时状态为published(DelayJob);
2、后,会从delayQ中取出,放入ReadyQ和数据字典中(数据被分开,readyQ只存id),状态为Ready(DelayJob);
3、回调成功,则删除readyQ&数据字典信息,状态是deleted(DelayJob);
4、回调失败,DelayedJob 变为FailedDelayJob(transfer)但不删除readyQ&数据字典信息,状态为published(FailedDelayJob);
5、FailedDelayJob超时,会从FailedDelayQ删除,放入ReadyQ和数据字典,状态为Ready(FailedDelayJob);
6、回调成功,则删除readyQ&数据字典信息,状态是deleted(FailedDelayJob);
7、回调失败,小于重试次数,则再次transfer但不删除readyQ&数据字典信息,状态为published(FailedDelayJob);
8、回调失败,超过重试次数,则归档,发提示短信,同时删除readyQ&数据字典信息,deleted(FailedDelayJob)。
DelayJob和FailedDelayJob转换:

技术亮点
1、使用jdk的delayQueue实现原理,放弃polling方式,采用wait-notify方式获取redis zset中保存的元素,更高效。
2、由于锁的存在,同一个topic的所有请求会竞争同一把锁,锁成为系统性能瓶颈。采用了锁分段的方式,一个topic 拆解程多个存储结构,同时一把锁拆分成多把锁。压测结果表明,锁分段后qps能够提升6倍。
3、failover:服务部署,一主一备,主服务挂掉,触发failover操作,备服务启动。
4、recover:如果主备都挂掉,服务重启,可以恢复之前未完成的操作,不会丢失消息。
五、压测情况
压测机器:4核32g虚机。
压测发现jvm对吞吐量几乎无影响。所以固定jvm大小-xms -xmx : 6g 6g ,主要考量分片影响。
注:
分片含义:是将redis中的delayQ(zset) 以及代码中的sheculer&delayq做了分片,主要是为了锁分段。
目前测试情况发现,分片后在压测情况下,readyQ和数据词典中都有未消费的数据(bug)。
1、分片数4

2、分片数8

3、分片数16
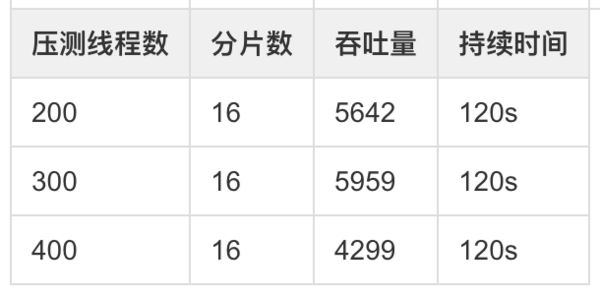
其它测试数据,平均耗时在50ms左右,中位数20-30ms,没有太大变化。
总结:
- jvm对性能影响微小,只要分配足够内存即可。
- 分片对性能影响较大,当分片等于8时能够取得最大的吞吐量 6208,分片再增加则会降低吞吐率。
- 压测线程数同样是抛物线,300时取得最大值。